OpenAI是一家以追求通用人工智能为目标的研究机构,为AI研究和社区提供了一系列高性能的研究成果和开源模型。其使命在于构建出高度自主并在大多数工作岗位上达到或者超过人类的表现,为人类提供安全、共赢的人工智能系统。
但纯粹的研究理想也需要负担庞大的科研开销,为了平衡使命和现实,OpenAI开始尝试将研发出的高性能算法GPT-3构建成API以实现商业化,以反哺消耗巨大的研究,同时促进算法和研究的进一步迭代改进。
基于这一强大的自然语言模型,OpenAI发布了一款通用的文本处理接口,与先前为特定目标设计的AI系统不同的是,此API可以允许用户任务尝试任意英文语言任务。研究人员和开发者可以利用它构建更为优秀的产品或者更具智能化水平的应用,同时还能为探索这一技术的优点和局限做出贡献。目前已经有十多个公司利用这一API在语义搜索、聊天机器人、客户服务、文本生成、生产力工具和内容补全等方面开发了一系列有效的产品。
在强大的语言模型下,API可以实现对于输入文本信息模式的有效学习和处理。用户可以用少数几个样本对模型进行“编程”,使它按照你的方式来回答问题。下图中显示了调用API的一个样例,可以看到在提供了一个问答样本后(红框中),模型可以根据问答样例的语言模式回答新的问题(蓝色)。模型不仅可以实现问答任务,还显示出了其中已经涵盖了非常丰富的语料和知识信息。
用户可以按照这种方式对模型进行定制化的打磨,一方面通过数据集(大数据或者是少量数据)对模型进行调优训练,另一方面也可以通过人机交互的反馈来对模型的输出进行改进。
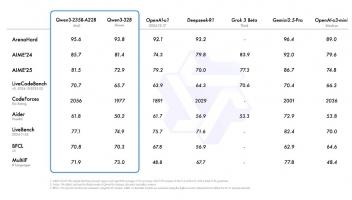
此API同时兼顾了易用性和灵活性,一方面可以让任何人都有接入最前沿人工智能技术的简单方式,同时也为研究人员提供了增加生产力的灵活方式,使得团队可以集中精力处理机器学习的核心问题。目前支持该API的是最新的GPT-3模型,GPT-3是OpenAI最近发布的非常强大的自然语言处理模型,完整模型包含了175 billion的参数。下表显示了GPT-3相关模型的架构和参数量。
机器学习领域的发展一日千里,所以背后所支撑的处理流程和模型也在不断迭代和更新。下面几个小视频展示了如何应用这一API到用户的日常工作生活中,以此来解决问题并提高生产力。
针对电子表格的制作,Tabulate插件提供了结构化的表格生成方案。用户仅仅需要输入想要制表的主体,模型就能生成比较理想的表头。在少量的修改后,选择填充表格模型就能从已有知识中填充出内容。这一例子中显示了公司名称、代码和上市的年份。为了聚焦互联网公司,只需要输入两个互联网公司的名字,模型就能找到相关内内容进行填充,还能按照创立年份排序。此外还能够从非结构文本中对文本信息进行结构化填充!突然感觉以后不用做excel了
第二个例子是利用模型对网页内容进行语义搜索。比如你打开了一个wiki百科页面来寻找答案,现在再也不需要一字一句读完整篇文章了,只需要利用网页插件输出你想要问的问题,模型就能根据语义搜索到页面中对应的段落,不仅解答了你的疑问还能对文本位置进行定位,大幅度地提高了资料检索的效率。
下面的例子完整地展示了如何构建个性化的应用,通过简单的linux指令和对应含义的描述,就能构建出一条语义操作模型。直接输出各种口语化表达模型,就能生成对应的命令和命令组合来实现你想要的结果。这个例子中,我们看到了API将人机交互简化到了何种程度,极大地减少了初学者的学习成本、提高了使用者的利用效率,看来用自然语言和计算机交互的时代已经非常近了。
但技术的进步是一把双刃剑,在大规模应用的同时也需要避免恶意使用。API在源头已经切断了一系列明显的恶意应用,包括骚扰、垃圾邮件、激进言论和病毒营销等,但想要穷尽所有可能的恶意应用是不可能的,除了产品开发者的把控,更需要社区的努力。开发者可以探索控制API返回恶意内容的工具,研究人员需要在语言模型的安全方面进行更加深入的研究(包括对于有害偏见的分析检测、缓和与阻断等等)。
123下一页>(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )