Meta携手Cerebras破纪录!Llama API以2600 tokens/s,打造最快AI推理解决方案,重塑行业标准!
随着人工智能(AI)的飞速发展,我们的生活和工作中充满了各种AI应用。为了满足这种日益增长的需求,Meta公司积极寻求创新,推出了独立AI应用的同时,还发布了Llama API,目前以免费预览形式向开发者开放。
Llama API的推出,无疑为开发者们提供了一个全新的工具,帮助他们更轻松地使用最新的模型。该API提供了一键创建API密钥的功能,使得开发者能够快速上手使用。同时,它还提供了轻量级的TypeScript和PythonSDK,这大大降低了开发者使用AI模型的门槛。
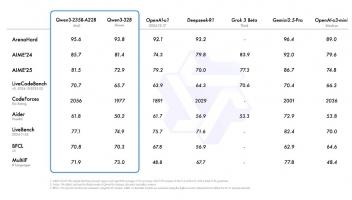
值得一提的是,Llla API完全兼容OpenAI SDK,这无疑为开发者提供了更多的便利。此外,Meta还联手Cerebras和Groq,进一步优化了Llla API的性能。Cerebras宣称其Llla 4 Cerebras模型的tokens生成速度高达2600 tokens/s,比传统GPU解决方案快18倍。这一惊人的速度远超ChatGPT的130 tokens/s和DeepSeek的25 tokens/s。
Cerebras CEO兼联合创始人Andrew Feldman对此表示:“我们非常自豪能让Llla API成为全球最快的推理API。在构建实时应用时,开发者需要极致的速度。Cerebras的加入让AI系统性能达到了GPU云无法企及的高度。” 这样的评价,足以看出Cerebras在AI领域的技术实力和地位。
除了Cerebras之外,Groq也为Llla API的性能优化做出了贡献。Groq提供的Llla 4 Scout模型速度为460 tokens/s,虽然不及Cerebras,但仍然比其他GPU方案快4倍。在Groq平台上,Llla 4 Scout每百万tokens输入费用为0.11美元,每百万tokens输出费用为0.34美元;而Llla 4 Maverick每百万tokens输入费用为0.50美元,每百万tokens输出费用为0.77美元。这样的费用对比,无疑增加了Llla API的竞争力。
然而,速度的提升并非Meta的唯一追求。他们还致力于提供一种更为高效、灵活和安全的AI推理解决方案。为此,Meta的团队深入研究并优化了Llla API的性能和功能,使其能够更好地满足开发者的需求。
总的来说,Meta的Llla API以其2600 tokens/s的速度,无疑成为了最快AI推理解决方案之一,重塑了行业标准。通过与Cerebras和Groq的合作,Meta进一步提升了Llla API的性能和可靠性。我们有理由相信,随着Llla API的普及和应用,AI将在更多领域发挥出更大的价值。作为开发者,我们期待着Llla API在未来为我们带来更多的便利和创新。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )