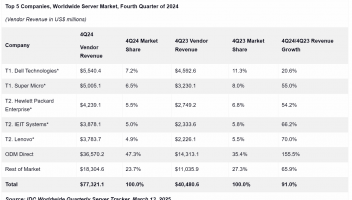
标题:AI开发神器!一键生成前端代码,前端程序员再也不用加班了!
随着科技的飞速发展,人工智能(AI)已经深入到了各个领域,其中也包括前端开发。近期,一款名为“Flame”的多模态大模型解决方案引发了业界的广泛关注。这款模型旨在通过视觉与文本的结合,一键生成符合现代前端开发规范的代码,极大地提高了开发效率,让前端程序员再也不用加班了。
一、背景介绍:前端开发的挑战
前端开发,作为软件工程的一个重要分支,一直面临着诸多挑战。随着Web技术的发展,前端开发逐渐走向了组件化、状态管理和数据驱动的渲染方式。这不仅要求开发者具备深厚的技术功底,还需要他们能够灵活应对各种动态交互需求。然而,由于前端开发流程的复杂性,使得生成符合规范的代码变得异常困难。
二、Flame模型:多模态解决方案
Flame模型是一个多模态解决方案,它能够通过图像和文本两种方式输入,生成符合现代前端开发规范的高质量代码。该模型在处理图像时,能够准确地识别出组件、状态和数据驱动的渲染方式,从而生成出模块化、可扩展的前端代码。
三、生成代码:符合规范且动态性强
通过观察一张设计图,Flame模型能够生成出清晰的外联样式和模块化组件结构的代码。同时,在组件的实现中,它能够正确定义组件的各个状态、事件响应以及基于数据的动态渲染。这种生成的代码不仅功能完善,而且符合现代前端开发的规范,具备强大的动态性和响应性。
四、对比其他模型:优势明显
相比于其他顶尖的SOTA模型,如GPT-4o和Gemini 1.5 Flash,Flame的优势十分明显。这些模型在端到端复刻设计图的过程中,只能产出静态组件的代码,无法支持模块化架构和动态交互。而Flame则能够通过多模态的输入,生成出符合前端开发需求的多模态代码,极大地提升了开发效率。
五、开源社区:数据集的重要性
为了进一步提升Flame模型的前端代码生成能力,团队设计并实现了三种合成方法:基于进化的数据合成、基于瀑布模型的数据合成以及基于增量开发的数据合成。这些方法不仅丰富了数据集的规模和多样性,还确保了数据质量与实际应用价值。这些方法能够低成本大规模合成特定前端框架的图文数据,借助这些方法,Flame团队针对React框架构建了超过400k的多模态数据集。这一成果进一步验证了数据集在多模态模型能力提升中的关键作用。
六、结语:前端的未来在于AI
随着AI技术的不断进步,前端开发的未来已经清晰可见:那就是与AI的深度融合。Flame模型的成功实践,让我们看到了这一融合的可能性。它通过视觉与文本的结合,一键生成符合规范的前端代码,极大地提高了开发效率。相信在不久的将来,我们将会看到更多像Flame这样的多模态大模型在前端开发领域大放异彩。
最后,值得一提的是,训练数据、数据合成流程、模型及测试集都已经开源,感兴趣的小伙伴们可以自行查看。让我们一起期待AI在前端开发领域带来的更多惊喜吧!
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )