DeepSeek R1通过创新的多阶段强化学习(RL)训练方法,采用组相关策略优化 (GRPO),在复杂推理任务中表现不俗,甚至有望超越OpenAI的o1模型。
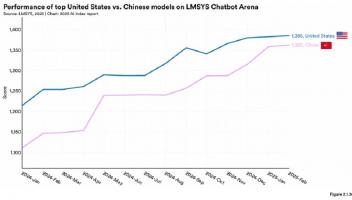
DeepSeek AI发布了其最新的模型DeepSeek-R1,这是一款在复杂推理任务中与OpenAI的o1模型相媲美的开源模型。它采用了一种名为组相关策略优化(GRPO)的强化学习算法,并通过多阶段训练方法不断优化。这一新算法旨在提升大型语言模型(LLM)的推理能力,尤其在数学推理等领域表现尤为突出。
GRPO的核心概念是通过取消对价值函数模型的依赖来简化训练过程。这一创新不仅减少了内存消耗和计算开销,还能通过组内得分来估算基准,从而优化模型性能。与传统的Proximal Policy Optimization(PPO)不同,GRPO不依赖单独的价值函数,而是使用多个输出的平均奖励作为基准进行优化。通过这种方式,模型可以更自然地处理多输出的情况,如同在处理单一输入时一样。
DeepSeek团队在构建DeepSeek R1的过程中,首先基于DeepSeek V3进行强化学习实验,尝试应用GRPO对无监督推理文本进行补全。使用规则奖励模型,重点评估格式、数学和编程等领域的表现。比如,通过奖励准确性来评估是否得出了正确的答案,或者是否解决了LeetCode问题;通过奖励格式来确保模型在思考过程中,能将其思维过程清晰地表达出来。
这些措施显著提升了DeepSeek R1在AIME 2024的表现,Pass@1得分从15.6%跃升至71.0%,接近OpenAI o1-0912的水平。随着问题的解答中token的数量增加,模型表现出自然地学会了在更长时间内思考并生成更多tokens来完成任务。
然而,这种进步并非没有代价。早期的模型输出可读性较差,语言混杂,但通过多阶段的训练方法,这一问题得到了解决。
在训练过程中,DeepSeek R1经历了四个关键阶段,以确保模型的稳定性和有效性。首先,团队进行了监督微调(SFT),以解决强化学习冷启动阶段的不稳定问题,并使用了包含大量链式思维(CoT)的数据集。接下来,模型在代码和数学等推理任务中应用GRPO,加入了“语言一致性”的奖励,以确保模型语言风格的一致性。第三阶段,通过拒绝采样(RS)生成大量合成数据集,重点提高模型在写作和角色扮演等通用任务中的能力。最后,在第四阶段,GRPO再次被应用,以结合规则和结果奖励模型,进一步优化模型的有用性和无害性,从而最终形成了DeepSeek R1。
其中,DeepSeek团队有几项惊人的选择和发现。与许多模型不同,DeepSeek并没有使用蒙特卡洛树搜索(MCTS)或过程奖励模型(PRM)。而且,通过在应用GRPO之前进行微调,训练过程变得更快、更稳定。特别是,基于准确性和格式的规则奖励,往往比复杂的奖励模型更加有效。
通过这一系列创新的训练步骤,DeepSeek R1不仅在推理能力上取得了显著进展,还能在各种任务中展现出更高的实用性和一致性。
本文译自 philschmid,由 BALI 编辑发布。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )