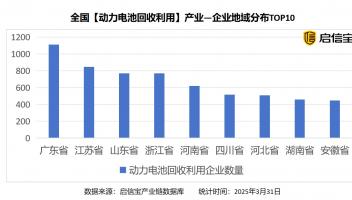
研究发现,Qwen天生擅长验证、回溯等推理行为,而Llama需通过训练诱导这些习惯,才能在强化学习中实现自我提升。
想象一下,当你面对一个棘手的数学题时,会怎么做?可能会多花点时间,仔细推敲每一步,甚至在走不通时退回去重来。这种深思熟虑的能力,如今也开始在语言模型身上显现。近年来,通过强化学习(RL),一些模型学会了在复杂问题上“慢下来思考”,就像人类专家那样。然而,有趣的是,有些模型进步神速,有些却很快停滞。比如,在《倒计时》游戏的相同训练下,Qwen-2.5-3B远远甩开Llama-3.2-3B。这不禁让人好奇:是什么让某些模型能不断自我提升?
为了解开这个谜团,研究者们聚焦于四种关键的认知行为:验证、回溯、设定子目标和逆向推理。这些习惯在人类解决问题时很常见——一位数学家会检查证明的每一步,遇到矛盾时放弃死胡同,把大问题拆成小块,从结果反推起因。研究发现,Qwen天生就带有这些特质,尤其擅长验证和回溯,而Llama起初几乎完全欠缺。正是这些行为,让Qwen能在强化学习中如鱼得水。
那么,能不能让Llama也学会这些本领呢?实验给出了一线希望。通过给Llama提供一些包含这些推理行为的示例,比如回溯的思考痕迹,它在强化学习中的表现突飞猛进,甚至追平了Qwen。更令人惊讶的是,即便这些示例的答案是错的,只要推理模式正确,效果依然显著。这说明,关键不在于答案对错,而在于模型是否掌握了这些认知习惯。
研究并未止步于此。研究者们还尝试从OpenWebMath数据中筛选出强调推理行为的内容,继续预训练Llama。结果令人振奋:Llama的进步轨迹逐渐与Qwen看齐。这表明,一个模型的初始推理能力,决定了它能否有效利用额外的计算资源。Qwen这样的“天赋选手”自然占优,而Llama则需要后天培养。
回想人类解题的场景,我们往往会反复验证,分解任务,甚至从目标倒推回去。语言模型也是如此。在《倒计时》游戏中,回溯和验证成了制胜法宝。研究者用这个游戏设计了初始实验,发现Llama只要稍加引导,就能展现潜力。后来,他们用更丰富的数据集进一步训练,证明这种提升并非偶然,而是可以通过精心挑选训练素材实现的。
这些发现揭示了一个简单却深刻的道理:模型的自我提升,取决于它最初的推理习惯。Qwen之所以能脱颖而出,是因为它自带验证和回溯的“天赋”;而Llama通过训练,也能迎头赶上。更有趣的是,即便用错误答案引导,只要保留正确的推理模式,效果依然不减。这让人不禁思考:在编程、游戏或写作等其他领域,又需要哪些特定的认知行为呢?
人类的智慧积累了无数解题的妙招,而AI正在这条路上越走越远。未来,它或许不仅能学会我们的习惯,还能创造出全新的推理方式。就像Qwen和Llama的故事告诉我们的,进步的关键不在于起点多高,而在于能否找到适合自己的成长路径。
本文译自 arxiv.org,由 BALI 编辑发布。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )