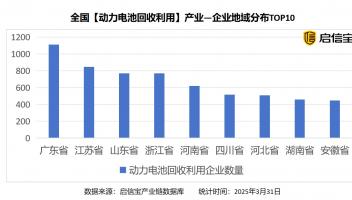
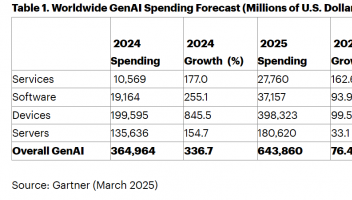
标题:字节跳动创新突破:OmniHuman多模态框架重塑动画生成
随着科技的不断发展,动画生成技术也在不断进步。近日,字节跳动的研究人员展示了一款全新的AI模型——OmniHuman多模态框架,该框架可以通过一张图片和一段音频生成逼真的半身、全身视频。这一创新突破将为动画生成领域带来全新的可能性,重塑动画生成技术。
首先,OmniHuman多模态框架的优势在于其强大的生成能力。与一些只能生成面部或上半身动画的深度伪造技术不同,OmniHuman-1能够生成逼真的全身动画,且能将手势和面部表情与语音或音乐精准同步。这种能力使得生成的动画更加自然、生动,给人以身临其境的感觉。
在测试视频中,OmniHuman-1模型的表现令人印象深刻。无论是AI生成的TED演讲,还是会说话的阿尔伯特·爱因斯坦,都能够呈现出令人惊叹的逼真效果。同时,OmniHuman-1模型还支持不同的体型和画面比例,从而使视频效果更加自然。这意味着,该模型可以根据不同的场景和需求,生成出更加贴合实际的动画效果。
其次,OmniHuman多模态框架的训练数据也值得一提。字节跳动表示,该模型基于约19000小时的人类运动数据训练而成。这意味着该模型能够学习并模仿人类的行为和动作,从而生成更加真实、自然的动画。这种数据量级的训练对于动画生成技术的提升至关重要,也是OmniHuman多模态框架能够取得如此显著成果的关键因素之一。
此外,OmniHuman多模态框架还具有适应性和灵活性。研究人员指出,该模型能够在内存限制内生成任意长度的视频,并适应不同的输入信号。这意味着该模型可以应对各种复杂和多样化的场景,具有很高的实用价值。同时,该模型还具有很高的扩展性,未来有望在更多领域得到应用,为人们带来更加丰富和多样化的视觉体验。
最后,OmniHuman多模态框架的真实性和准确性也超越了其他同类动画工具。目前,该工具暂不提供下载或有关服务,但这并不妨碍我们对其未来的期待。随着技术的不断进步和完善,我们相信OmniHuman多模态框架将会在动画生成领域发挥越来越重要的作用,为人们带来更加逼真、自然、生动的视觉体验。
总之,字节跳动的研究人员通过OmniHuman多模态框架的创新突破,为我们展示了动画生成技术的全新可能性。这一技术将为动画产业带来巨大的变革和机遇,同时也预示着未来数字技术的发展方向。我们期待着这一技术在未来的更多应用和突破。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )