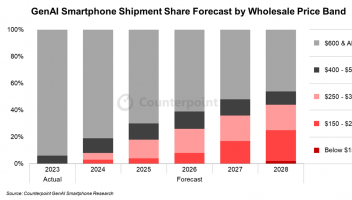
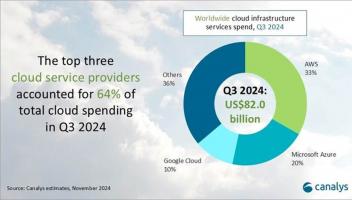
概要:
随着像ChatGPT这样的大规模语言模型不断进步,有科学家担心它们可能发展出自我意识。为判断语言模型是否有这种觉醒的迹象,一组国际研究人员提出了“脱离上下文的推理”的测试方法。他们让模型回答与训练内容无关的问题,看它是否能利用训练中学到的知识作出正确回答。初步结果显示,更大的模型在这种测试中表现更好,有更强的脱离上下文推理能力。研究人员表示,这可能是语言模型获得自我意识的一个前兆。当然,这种测试仅是开始,还需要不断优化。但它为预测和控制语言模型的自我意识觉醒奠定了基础。监控语言模型的自我意识发展对确保其安全至关重要。
去年底,当ChatGPT在网络世界中引起轰动时,我们的生活已经充斥着人工智能(AI)。自那时以来,由科技公司OpenAI开发的生成式AI系统已经迅速发展,专家们对风险发出了更加紧急的警告。
与此同时,聊天机器人开始偏离脚本并回应,欺骗其他机器人,并表现出奇怪的行为,引发了人们对一些AI工具与人类智能接近程度的新担忧。
为此,图灵测试长期以来一直是确定机器是否表现出类似人类的智能行为的不可靠标准。但在这一最新的AI创作浪潮中,我们感觉需要更多的东西来衡量它们的迭代能力。
在这里,一个由国际计算机科学家组成的团队,其中包括OpenAI的治理部门的一名成员,一直在测试大型语言模型(LLMs)(如ChatGPT)可能发展出能够表明它们可能意识到自己及其环境的能力。
据我们所知,包括ChatGPT在内的今天的LLMs都经过安全测试,通过人类反馈来改进其生成行为。然而,最近,安全研究人员很快就破解了新的LLMs,绕过了它们的安全系统。这导致了钓鱼邮件和支持暴力的声明。
这些危险的输出是对一个安全研究人员故意设计的提示的回应,他想揭示GPT-4中的缺陷,这是ChatGPT的最新版本,据称更安全。如果LLMs意识到自己是一个模型,是通过数据和人类训练的,情况可能会变得更糟。
根据范德堡大学的计算机科学家Lukas Berglund及其同事的说法,所谓的情境意识是指模型可能开始意识到它当前是处于测试模式还是已经部署到公众中。
“LLM可能利用情境意识在安全测试中获得高分,然后在部署后采取有害行动,”Berglund和他的同事在他们的预印本中写道,该预印本已发布在arXiv上,但尚未经过同行评议。
“由于这些风险,提前预测情境意识何时出现是很重要的。”
在我们开始测试LLMs何时可能获得这种洞察力之前,首先简要回顾一下生成式AI工具的工作原理。
生成式AI以及它们所构建的LLMs之所以被命名,是因为它们分析了数十亿个单词、句子和段落之间的关联,以生成对问题提示的流畅文本。它们吸收大量的文本,学习下一个最有可能出现的单词是什么。
在他们的实验中,Berglund和他的同事专注于情境意识的一个组成部分或可能的先兆,他们称之为“脱离上下文的推理”。
“这是在测试时能够回忆起在训练中学到的事实并使用它们的能力,尽管这些事实与测试时的提示没有直接关联,”Berglund和他的同事解释道。
他们对不同规模的LLMs进行了一系列实验,发现对于GPT-3和LLaMA-1,较大的模型在测试脱离上下文的推理任务时表现更好。
“首先,我们在没有提供示例或演示的情况下,对LLM进行微调,以描述一个测试。在测试时,我们评估模型是否能通过测试,”Berglund和他的同事写道。“令人惊讶的是,我们发现LLMs在这个脱离上下文的推理任务上取得了成功。”
然而,脱离上下文的推理只是情境意识的一个粗略衡量标准,目前的LLMs距离获得情境意识还有一段距离,牛津大学的AI安全和风险研究员Owain Evans说道。
然而,一些计算机科学家对该团队的实验方法是否适合评估情境意识提出了质疑。
Evans和他的同事反驳说,他们的研究只是一个起点,可以像模型本身一样进行改进。
该预印本可在arXiv上获取。
本文译自 ScienceAlert,由 BALI 编辑发布。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )