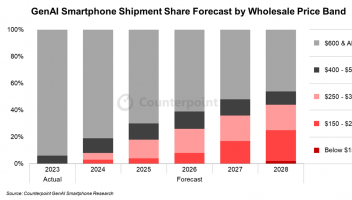
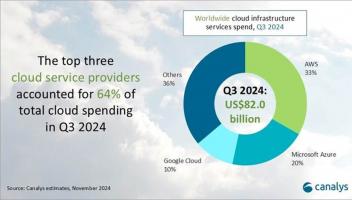
牛津大学的研究人员与国际专家合作,在《自然·机器智能》上发表了一项新研究,讨论围绕大语言模型(LLM)产生的输出的责任归属的复杂伦理问题。该研究表明,像ChatGPT这样的LLM提出了关于有用文本生成的信誉和权利归属的关键问题,这与传统的AI责任辩论不同,后者主要关注有害后果。
联合第一作者Sebastian Porsdam Mann和Brian D. Earp说,“像ChatGPT这样的LLM带来了对责任概念更新的紧迫需求。”
根据联合作者Sven Nyholm和John Danaher的说法,该研究的一个关键发现是:“虽然这些技术的人类用户无法完全声称LLM产生的积极结果属于自己的功劳,但似乎仍然适当地将其视为有害用途的责任,如产生错误信息或疏忽地检查生成文本的准确性。” Nyholm和Danaher在前人的工作基础上称此为“成就差距”:“正在完成有用的工作,但人们无法像以前那样从中获得满足感或认可。”
论文的高级作者Julian Savulescu补充说,“我们需要有关作者资格、披露要求、教育用途和知识产权的指导方针,参考现有的规范性文献和类似的相关辩论,例如人类增强辩论。”Savulescu继续说,要求透明度的规范尤其重要,“以跟踪责任和正确地赞扬和责备。”
该研究由法律、生物伦理学、机器学习和相关领域的跨学科专家团队共同撰写,深入探讨LLM在教育、学术出版、知识产权和误信息和虚假信息生成方面的潜在影响。
教育和出版业尤其需要迅速采取LLM使用和责任方面的指导方针行动。联合作者John McMillan和Daniel Rodger表示:“我们建议文章提交包括关于LLM使用情况的声明以及相关补充信息。LLM的披露应类似于人类贡献者,承认重大贡献。”
该文指出,LLM在教育方面可能有帮助,但警告说它们容易出错,过度使用可能会影响批判性思维技能。作者写道,机构应考虑调整评估方式,重新思考教学法,并更新学术不端行为指导,以有效处理LLM的使用。
生成文本的权利,如知识产权和人权,是LLM使用影响需要迅速解决的另一个领域,联合作者Monika Plozza指出。“知识产权和人权带来挑战,因为它们依赖于以人为主设定的劳动和创造力概念。我们需要开发或调整如‘贡献者’的框架来处理这种高速发展的技术,同时保护创作者和用户的权利。”
并非所有LLM的可预见用途都是善意的。联合作者Julian Koplin警告,“LLM可以用于生成有害内容,包括大规模的误信息和虚假信息。这就是为什么我们需要让人们对使用的LLM生成文本的准确性负责,以及努力教育用户和改进内容审核政策来减轻风险。”
为了应对与LLM相关的这的风险和其他风险,联合作者Nikolaj Møller和Peter Treit表示,LLM开发者可以效仿生物医学领域的自我监管。“建立和应得的信任对LLM的进一步发展至关重要。通过促进透明度和开展公开讨论,LLM开发者可以展示其对负责任和道义实践的承诺。”
本文译自 techxplore,由 bali 编辑发布。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )