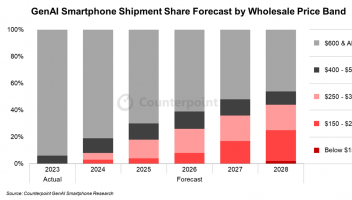
亚马逊的Alexa可根据语音判断你需要的选择,但是人工智能(AI)却可以感知你是否生气。麻省理工学院媒体实验室的分支机构Affectiva的声联网系统,可在短短1.2秒内从音频数据中分辨出你的愤怒。无论是什么语言,这个时间刚好超过人类感知愤怒所需的时间。
AI可分辨人类的愤怒
Affectiva的研究人员在Arxiv.org上最新发表的一篇论文中描述了这一现象(“从声音表征中转移学习,用于语音中的愤怒检测”)。它建立在语音和面部数据的基础上,并建立相关的情感档案。今年,该公司与Nuance合作开发了一种车载人工智能系统,可以从摄像头的反馈中检测驾驶员疲劳的迹象。在2017年12月,它推出了语音API,该API使用语音识别功能,诸如大笑、愤怒等情绪,以及音量、音调、速度和停顿。
论文的共同作者写道:“利用深度学习网络的力量进行情感识别的一个重要问题是,深度网络所需的大量数据,与小规模的语音数据之间的不匹配。经过训练的愤怒检测模型提高了性能,并能很好地概括各种行为,从而引发情绪言语的数据集。此外,我们提出的系统具有较低的延迟,适用于实时应用。”
什么是声联网?
SoundNet(声联网)由一个卷积神经网络(一种通常用于分析视觉图像的神经网络)组成,它在视频数据集上进行训练。为了让它识别言语中的愤怒情绪,研究小组首先搜集了大量的普通音频数据——200万段视频,或者仅仅相当于一年多的时间——使用另一种模型生成的ground truth。然后,他们使用一个更小的数据集IEMOCAP对其进行微调,该数据集包含12个小时的带注释的视听情感数据,包括视频、语音和文本转录。
为了测试人工智能模型的通用性,该团队评估了它的英语训练模型用于汉语普通话语言的情感数据(普通话情感语料库,简称MASC),他们的报告说,它不仅很好地推广到英语语音数据,而且对汉语数据也很有效——尽管性能略有下降。
AI可识别语音情感模型
研究人员说,他们的成功证明了一种“有效的”和“低延迟的”语音情感识别模型,可以通过转移学习得到显著改善。转移学习是一种技术,它利用人工智能系统在之前标注过的样本的大数据集上训练,在一个数据稀疏的新领域中引导训练——在这种情况下,人工智能系统能通过训练分类一般声音。
这一结果是有希望的,因为尽管情感语音数据集很小,而且获取起来也很昂贵,但是大量的自然声音事件数据集是可用的,比如用于训练SoundNet的数据集或谷歌的音频集。仅这两个数据集就有大约1.5万个小时的标记音频数据。“愤怒分类有很多有用的应用,包括对话界面和社交机器人、交互式语音应答系统、市场研究、客户代理评估和培训,以及虚拟现实和增强现实。”
他们把开发其他大型公共语料库的工作留给了未来,并为相关的语音任务训练人工智能系统,比如识别其他类型的情感和情感状态。相信,在未来AI将发挥更多的作用,你认为未来的AI还能应用在哪些领域呢?
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )