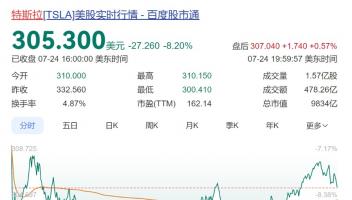
6月20日消息,斯坦福大学的大模型测评榜单HELM MMLU发布最新结果,斯坦福大学基础模型研究中心主任Percy Liang发文表示,阿里通义千问Qwen2-72B模型成为排名最高的开源大模型,性能超越Llama3-70B模型。
MMLU(Massive Multitask Language Understanding,大规模多任务语言理解)是业界最有影响力的大模型测评基准之一,涵盖了基础数学、计算机科学、法律、历史等57项任务,用以测试大模型的世界知识和问题解决能力。但在现实测评中,不同参评模型的测评结果有时缺乏一致性、可比性,原因包括使用非标准提示词技术、没有统一采用开源评价框架等等。

斯坦福大学基础模型研究中心(CRFM,Center for Research on Foundation Models)提出的基础模型评估框架HELM(A holistic framework for evaluating foundation models),旨在创造一种透明、可复现的评估方法。该方法基于HELM框架,对不同模型在MMLU上的评估结果进行标准化和透明化处理,从而克服现有MMLU评估中存在的问题。比如,针对所有参评模型,都采用相同的提示词;针对每项测试主题,都给模型提供同样的5个示例进行情境学习,等等。
日前,斯坦福大学基础模型研究中心主任Percy Liang在社交平台发布了HELM MMLU最新榜单,阿里巴巴的通义千问开源模型Qwen2-72B排名第5,仅次于Claude 3 Opus、GPT-4o、Gemini 1.5 pro、GPT-4,是排名第一的开源大模型,也是排名最高的中国大模型。
据悉,通义千问Qwen2于6月初开源,包含5个尺寸的预训练和指令微调模型,目前Qwen系列模型下载量已经突破1600万。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )