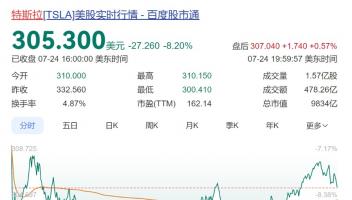
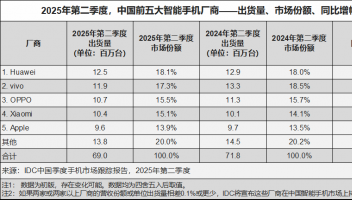
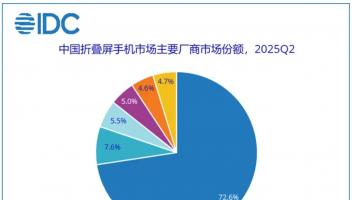
6月30日消息,据外媒报道,在一项集体诉讼中,OpenAI被控非法使用图书数据来训练ChatGPT。
ChatGPT是OpenAI于2022年11月30日推出的一种新型AI聊天机器人工具,可根据用户的要求快速生成文章、故事、歌词、散文、笑话,甚至代码,并回答各类疑问。ChatGPT一经发布就在互联网上掀起了一场风暴,并成为历史上增长最快的消费者应用程序。
然而,两名美国作家在旧金山联邦法院起诉OpenAI,声称该公司滥用他们的作品来“训练”ChatGPT。他们表示,ChatGPT在未经许可的情况下提取从大量图书中复制来的数据,侵犯了作者的版权。
据报道,为了训练其强大的人工智能语言模型,OpenAI会利用从网络收集来的大量数据,这些数据集包括维基百科文章、著名小说、社交媒体帖子等所有内容,而OpenAI没有要求获得任何许可。
这起在加州提起的集体诉讼称,不遵守适当的采购指导方针,包括征求最初制作这些内容的人的同意,就相当于直接盗窃数据。
该诉讼请求法院裁定,OpenAI非法下载小说副本以训练其人工智能系统,侵犯了作家的作品,ChatGPT的答案构成侵权。(小狐狸)
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )