
在上期文章中,我们简要回顾了Llama模型的概况,本期文章我们将详细探讨【关于Llama 2】,你需要知道的那些事儿。
1、Llama 2的性能有多好?
作为Meta新发布的SOTA开源大型语言模型,Llama 2是Llama模型的延续和升级。Llama 2家族模型包括了Llama 2预训练模型和Llama 2-chat微调模型,分别有7B、13B和70B参数量的版本,覆盖了不同的应用场景需求。
1.1 训练数据
Llama 2在预训练语料上比Llama增加了40%,增至2万亿个token,且训练数据中的文本来源更加的多样化。此外,Llama 2对应的微调模型是在超过100万条人工标注的数据下训练而成。
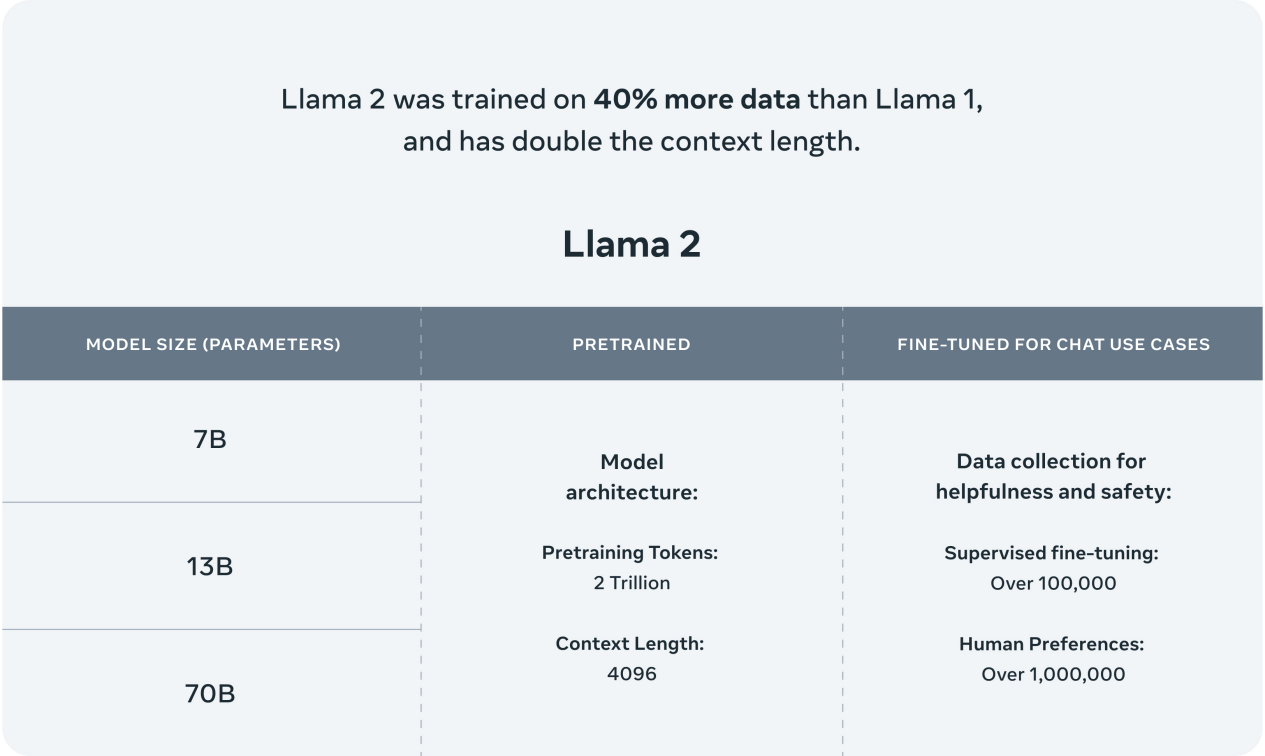
图1: Llama 2模型概览 [1]
1.2 模型评估
从模型评估上看,Llama 2在众多的基准测试中,如推理、编程、对话能力和知识测验上,都优于一代Llama和现有的开源大模型。
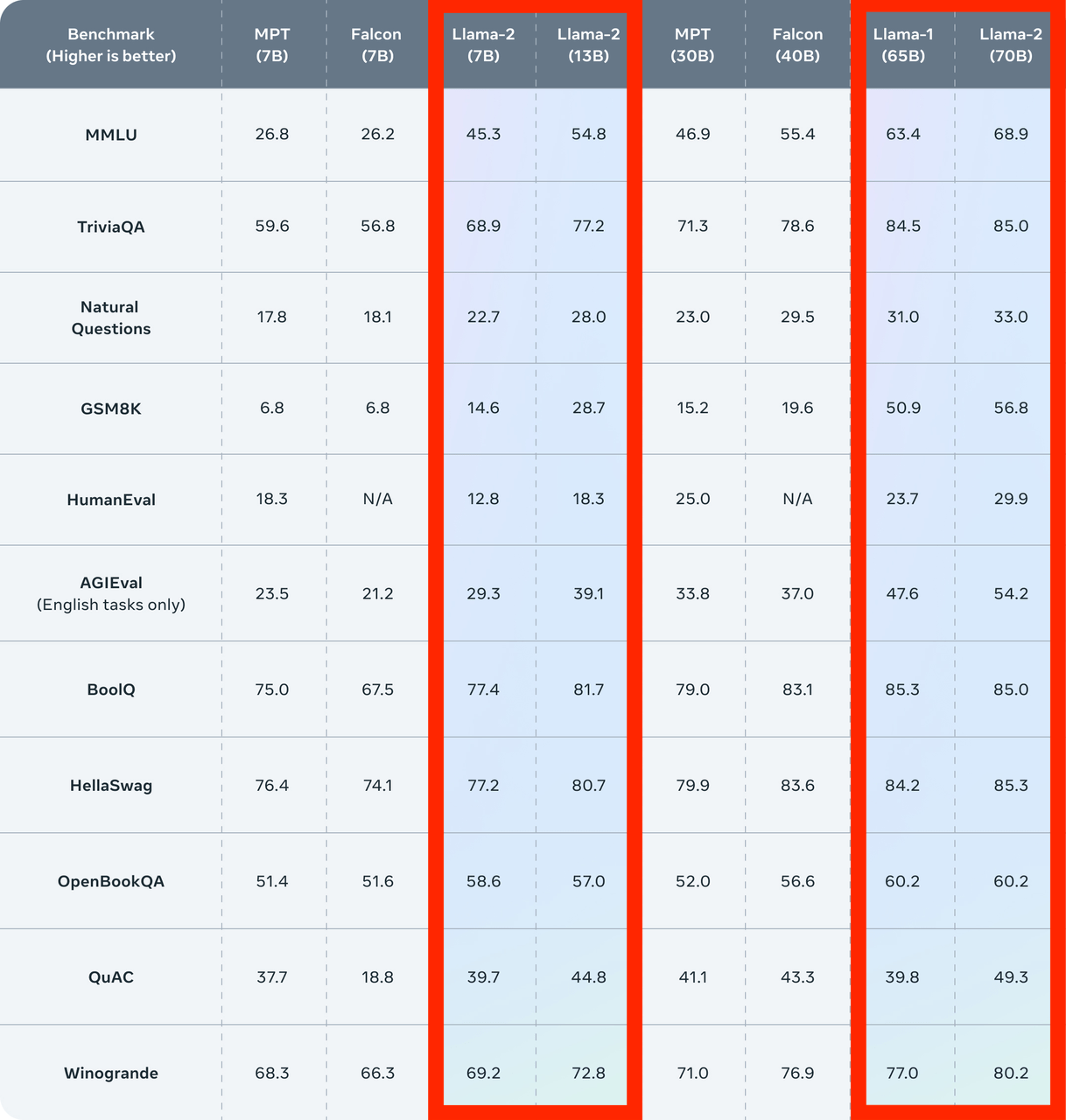
图2: Llama 2在不同基准测试上的得分
虽然Llama 2-70B在推理任务上表现接近GPT-3.5,但是在综合性能上还是无法与OpenAI的GPT-4和Google的PaLM-2-L等闭源大模型相媲美,尤其在编程基准上远落后于两者。
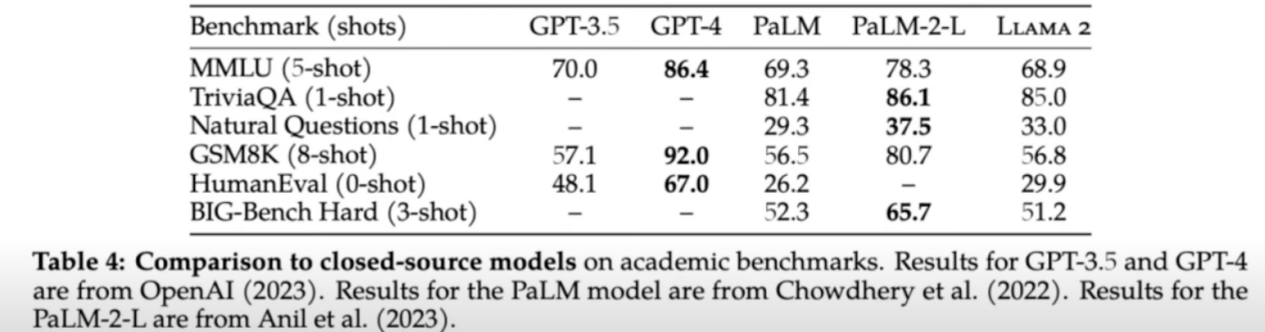
图3: Llama 2,GPT和PaLM三者在不同基准测试上的得分
2、解锁Llama 2的模型结构
2.1 Llama 2模型架构
Llama 2在预训练设置和模型架构上和一代模型非常相似。
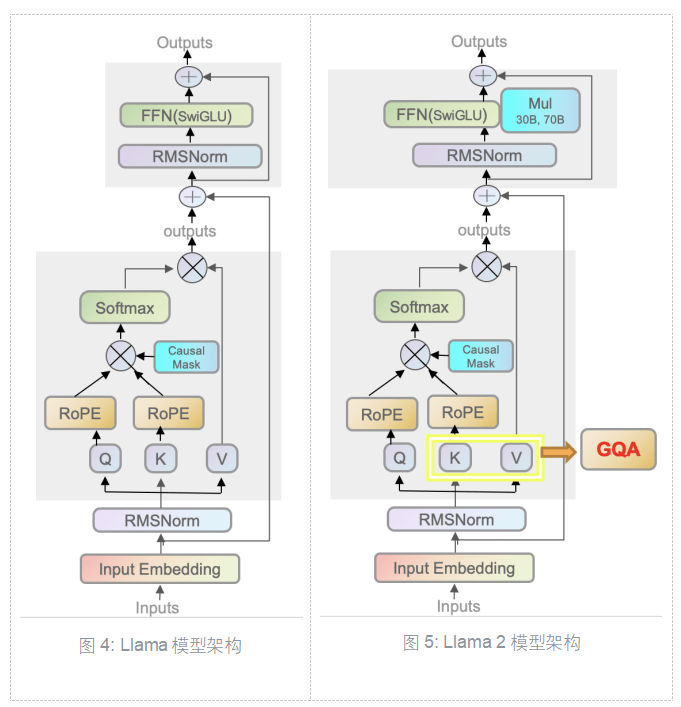
如图4和图5所示,Llama系列模型都使用了自回归Transformer架构,即Transformer's decoder-only架构。两代模型的一致性体现在:
a. 预归一化(Pre-normalization):对每一个transformer的子层输入都进行归一化,使用RMSNorm归一化函数
b. SwiGLU激活函数:在前馈神经网络(FFN)使用SwiGLU 激活函数替换了Transformer中的 ReLU 激活函数来提升性能
c. 旋转嵌入编码(Rotary Positional Embeddings,RoPE):RoPE可以兼顾相对位置和绝对位置的信息以提高模型的泛化能力
2.2 Llama 2训练亮点
除了上文提到的训练数据的增加,Llama 2在训练过程方面也有两个亮点值得我们关注。第一,上下文长度的扩大提升了模型的理解能力;第二,分组查询注意力机制提高了模型的推理速度。
2.2.1 上下文窗口扩大
Llama 2的上下文长度比Llama扩大了一倍,从2048个token拓展至4096个token。更长的上下文窗口意味着更多的聊天用例可被采用,进而模型的理解能力得以提升。
2.2.2 Grouped-Query注意力
在Attention的实现上,Llama 2 30B以上的模型采用了分组查询注意力机制(Grouped-Query Attention,GQA),见图5和图6。
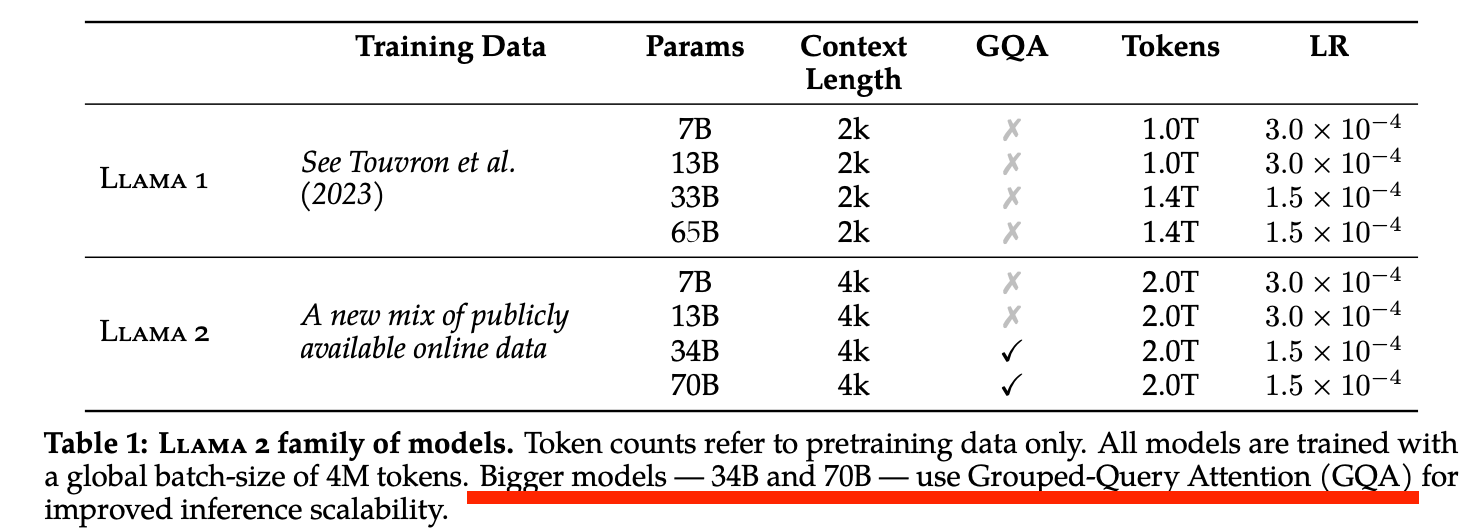
图6: Llama 2使用GQA [2]
自回归模型的解码通过缓存序列先前标记的键(K)值(V)对来加速注意力的计算。然而随着Batch Size和上下文窗口的增大,多头注意力模型(Multi-head Attenrion,MHA)的内存成本会随之显著增大。
图7: "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints" [3]
GQA的优势在于其将Query进行分组,组内共享KV,这样使得K和V的预测可以跨多个头共享,从而显著降低计算和内存需求,提升推理速度 。
2.3 Llama 2-chat微调流程
Meta致力于在偏好数据上训练奖励模型,然后采用强化学习进行优化,从而提高生成的质量。
2.3.1 SFT + RLHF by RS and PPO
和InstructGPT类似,在Llama 2-chat对话模型微调流程分为:
a. 自监督训练后获得Llama 2基座模型
b. 监督微调(Supervised fine-tuning,SFT)
c. 人类反馈强化学习(Reinforcement learning with human feedback,RLHF):拒绝采样 + 近端策略优化
RLHF使用了拒绝采样(Rejection Sampling fine-tuning,RS)和近端策略优化(Proximal Policy Optimization,PPO)两个优化算法。拒绝采样的原理为模型输出时采样K个结果,用当前时刻最好的奖励模型打分,选择奖励值最高的一个。在强化学习阶段进行梯度更新,并结合PPO进行RS加PPO的优化处理。
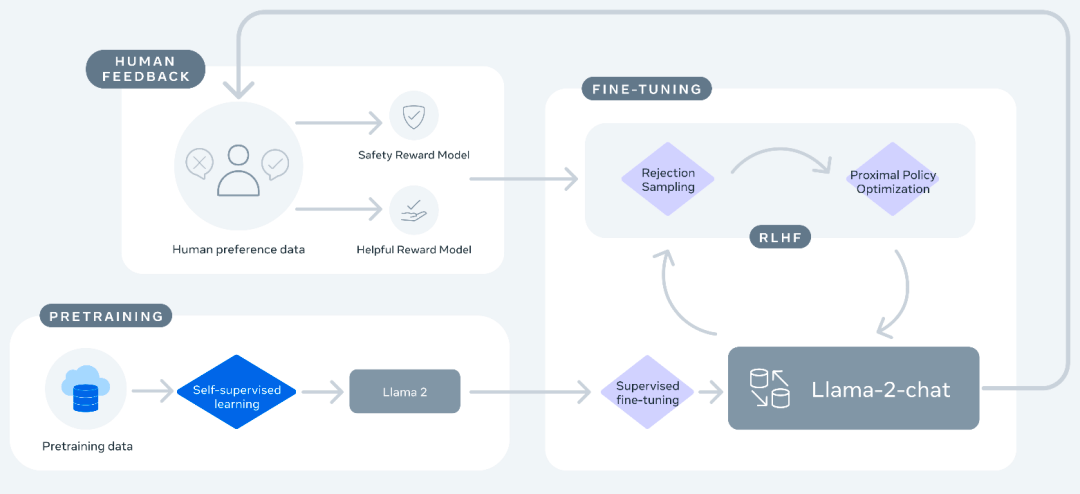
图8: Llama 2-chat的微调过程[1]
Meta一共迭代了5个RLHF版本,分别从V1-V5,但仅公布了最新的V5版本。V5版本迭代的步骤下图所示。
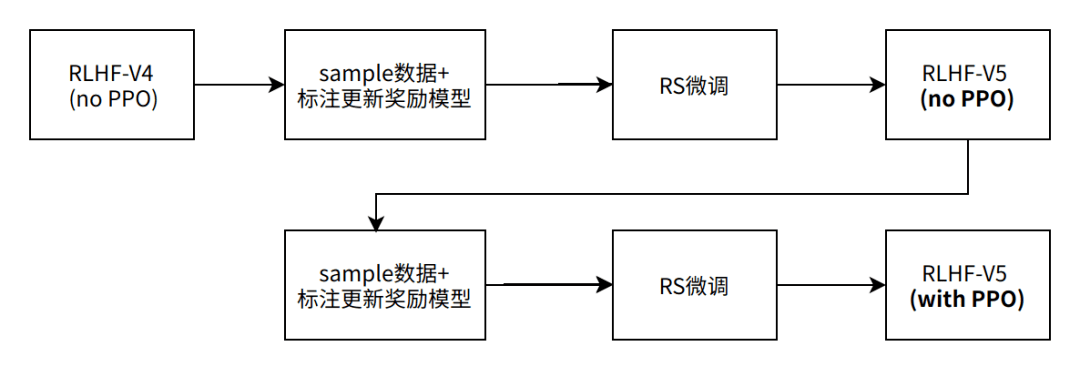
图9: RLHF-V5迭代流程
2.3.2 Quality Is All You Need
Meta使用用户偏好数据训练的两个独立的奖励模型Helpfulness RM和Safty RM,分别对有用性和安全性进行了优化。在SFT的过程中,Llama 2的官方论文[2]着重强调了只需少量高质量的SFT偏好数据就能显著提升结果质量(Quality Is All You Need)。此外,这篇论文也是第一篇指出“RLHF从根本上提高了大模型性能的上限”的论文。
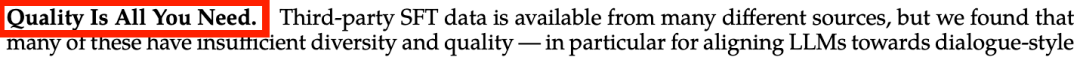
图10:Llama 2论文中强调的“Quality Is All You Need"[2]
综上,Llama 2训练流程给我们最重要的一个启示是:
奖励模型不仅是RLHF的关键,也是整个大模型效果的关键;数据质量又是奖励模型的关键。[4]
03、Llama 2在UCloud UK8S上的实践
3.1 下载模型
3.1.1 下载模型
从HuggingFace上克隆Llama 2的模型 [5]:https://huggingface.co/meta-llama。本文使用的是Llama 2-chat-7b模型。
3.1.2 安装WebUI工具
oobabooga开源的text-generation-webui [6] 一个大模型的可视化工具包,安装方法如下:
a. 进入Text Generation的github
(https://github.com/oobabooga/text-generation-webui)
b. 选择一键安装包安装或者手动安装
c. 我们将Llama 2模型文件放入text-generation-webui/models目录下,文件结构如下图:
3.2 构建镜像
根据Uhub容器镜像库的说明:
(https://docs.ucloud.cn/uhub/guide)
1. 首先,在Uhub上创建镜像库
2. 其次,在云主机创建镜像,并打标

3. 最后,将云主机镜像推到Uhub中

3.3 配置UK8S集群
1. 创建UFS文件系统并挂载。(https://docs.ucloud.cn/ufs/ufs_guide/create)

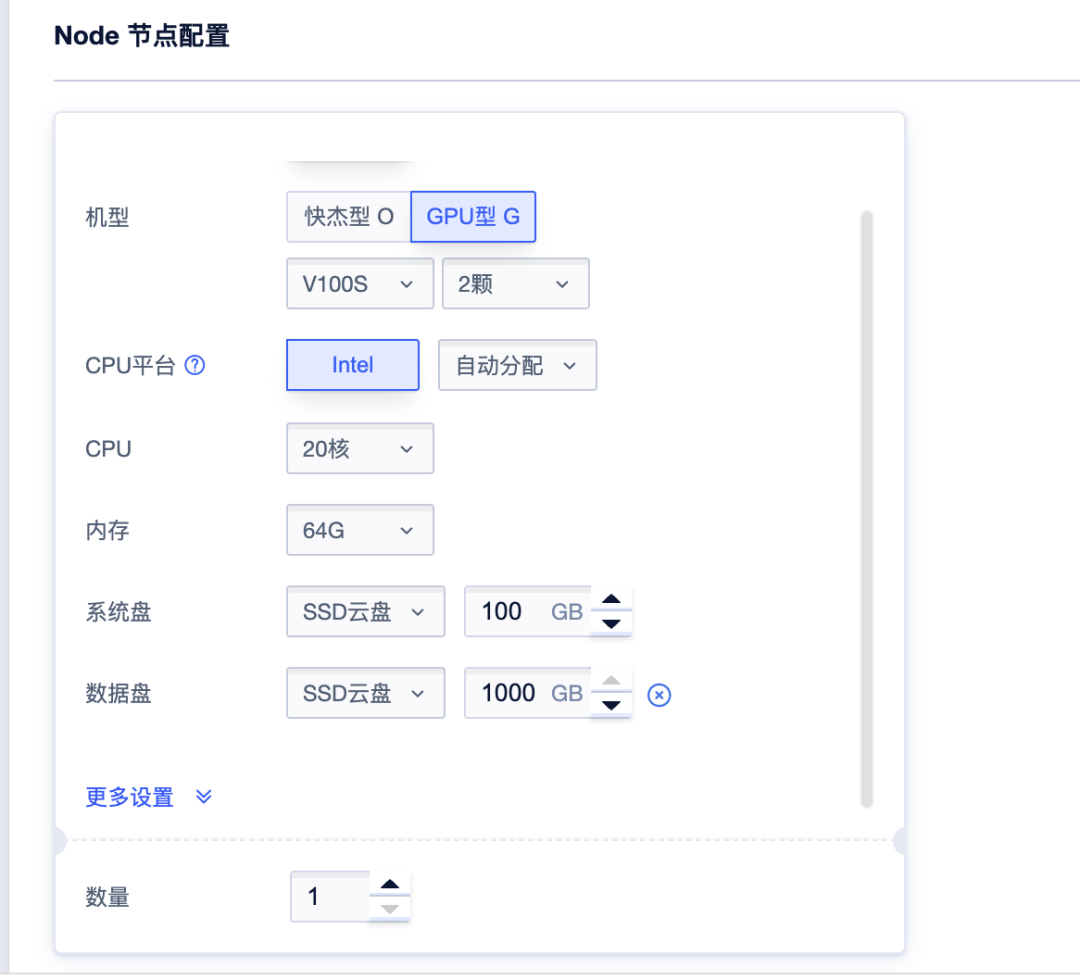
2. 创建UK8S容器云。参考文档(https://docs.ucloud.cn/uk8s/),创建集群时,Node的配置可参照下图:
集群创建之后,点击“详情”按钮,将“外网凭证”拷贝到~/.kube/config文件中。同时,需要安装和配置Kubectl命令行工具。
(https://docs.ucloud.cn/uk8s/manageviakubectl/connectviakubectl?id=安装及配置kubectl)
3. 在UK8S中使用UFS
用创建好的UFS作为UK8S集群的共享存储。
根据在UK8S中使用UFS文档,创建PV和PVC。
(https://docs.ucloud.cn/uk8s/volume/ufs?id=在uk8s中使用ufs)
a. 创建Pod:编写配置文件ufspod.yml

执行配置文件

b. 进入Pod
查询Pod Name:

在Pod内部启动一个Bash Shell:

c. 在线推理
运行server.py文件

至此,我们就可以在Web端和Llama 2进行对话了。

本期我们介绍了【关于Llama 2】你需要知道的那些事儿。Llama系列模型由于其体积小且开源的特性,在AI社区的热度和口碑都居于高位,可以预见短期内将有更多基于Llama 2定制化的微调模型和相关服务涌现。
下期文章我们将聚焦“LangChain+大模型+向量数据库”在云端的部署和推理,敬请期待~
4、参考文献
[1] Llama 2 官方公告:https://ai.meta.com/llama/
[2] Llama 2 官方论文:https://huggingface.co/papers/2307.09288
[3] "GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints " by Google Research:https://arxiv.org/pdf/2305.13245.pdf
[4] "Llama 2: an incredible open LLM" by Nathan Lambert: https://www.interconnects.ai/p/llama-2-from-meta
[5] Llama 2 models: https://huggingface.co/meta-llama
[6] Text generation web UI github: https://github.com/oobabooga/text-generation-webui
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















