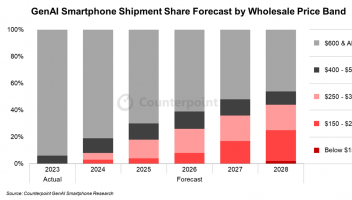
如果说人工智能是一辆飞奔的豪华跑车,那么数据就是提供强劲动力的燃料,这种能源不仅要充沛,还要确保质量。否则,就会产生瑕疵影响跑车的速度和行进轨道,甚至会引发AI的“生命危险”。
日常生活中,数据的类型大体可分为结构化数据、非结构化数据、半结构化数据。一个数据从产生到落地要经过收集、传输、分析、检索、挖掘等阶段。分析让大量的数据有了价值,机器要学会像人一样学习、思考、推理、交流,进而与应用场景相结合,从规律中预测未来。不过,要让机器像人一样去“看”数据,恐怕穷尽一生也无法分析完。
举个例子,计算机在进行视觉训练时,如果用1万把椅子的照片让其学习,人的固有思维会先记住椅子外观的关键组成部分,比如椅背和椅子腿。而对于机器学习来说,它们或许会找到一些新的特征,并对这些特征进行归纳来识别出一把新的椅子。这一过程中,需要有海量、不同的椅子照片供给计算机去学习。
如果深究技术层面,数据分析所用的map-reduce算法可将数据分解为多个部分,利用hadoop集群对每一部分的数据进行分析,之后将效果汇总经过多轮计算筛选出结果。解析过程中,对每轮结果的优化又会引入Spark这种快速通用的计算引擎。如果强调实时数据处理,也会用到storm等计算框架。
然而,就像柴油注入汽油车会出问题,也不是任何数据对人工智能都有积极作用,不少案例已经可以证明这一点。例如,有些聊天机器人在网络上学习了负面评论,就会变得“尖酸刻薄”甚至引发了种族歧视问题。可见,数据的开源性固然重要,但如何找到有质量的数据对AI发展有着决定性的影响,尤其是在受到高度监管的行业。
人工智能的负面影响不仅在于学习偏差,还可能被黑客利用成为新型网络攻击的武器,甚至出现伦理问题。如果数据本身是有瑕疵的,那么不管是有意还是无意,人工智能系统都会基于这样的数据进行训练,带来的后果可想而知。举个例子,一个信用卡审核系统要是用有偏差的数据构建解决方案,就会对某一类的申请人给初带有偏见性的结论。往坏处想,这或许就是马斯克眼中“AI毁灭人类”的开端。
如今,小到Alexa、Siri这些虚拟机器人对人类语言理解的错误判断,大到自动驾驶在道路测试时发生的交通事故,都在印证着人工智能在利用数据进行训练时仍有相当大的上升空间。也就是说,人们除了要在数据合规的基础上,开放更多的数据源,还要借助区块链等新技术或手段为这些数据建立完善的审核机制。
互联网时代的快节奏让数据也跑在快车道上,松懈不得。以城市交通治理为例,每天在城市道路上都在发生着堵车或者事故,如果做不到对数据的实时分析就难以立刻找到有效的疏通办法,而在上下班高峰期时的交通堵塞往往因为某一个信号灯故障就会引发。
再比如,工业互联网时代产生的数据量比传统信息化要多数千倍甚至数万倍,并且是实时采集、高频度、高密度的,动态数据模型随时可变,甚至良品率的细微变化都会带来数据模型重建。这样一来,如果做不到工业数据实时更新,智能制造就无从谈起。
总的来说,即使人工智能有一天真的成为“类人”,仍然离不开人类将其引导上一条正路。无论是伦理还是情感问题,都要基于数据进行判断,而要是数据的质量无法保障,再智能的AI都会被“逼疯”。(来源:中关村在线)
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )