
作者:杨雨
“MTU的值设置多少合适呢?现在最佳实践是设置到9000。”
“其实OpenFlow只是一个概念,从这几年SDN的发展来看,它并没有成为一个事实的标准。”
“大规模云平台对SDN的要求,第一是网络基础架构要可扩展,第二是控制器可扩展,第三是数据平面无集中式单点,第四是跨集群的扩展网络。”
“在基础架构上,如果用Tungsten Fabric,只要是用于生产环境的话,选择IP CLOS架构就行,没必要再去折腾Fabric等二层架构。”
“Tungsten Fabric的本质是基于MPLS VPN的SDN。”
“跨集群的互联,或者叫多云互联,主要有两种模式:基于控制器之间的互联,基于Cloud Gateway之间的互联。”

本文整理自TF中文社区技术代表杨雨在TF中文社区“2020第一次Meetup”上的演讲,分享Tungsten Fabric对大规模云平台的支持。本文已经主办方和演讲者审阅授权发布。
在TF中文社区1月7日的“2020第一次Meetup”活动上,来自Tungsten Fabric技术研发和一线使用者、关注多云互联的从业者、开源SDN的爱好者们互相切磋、支招,现场气氛热烈,精彩内容不断。Tungsten Fabric在中国的广泛应用正在越来越真切地走来。
本次演讲及TF中文社区“2020第一次Meetup”活动资料,请在“TF中文社区”公众号后台点击“会议活动-Meetup”领取。

今天的分享偏技术一些,首先我们来看SDN的本质,然后从Tungsten Fabric架构上解析为什么比OVS更好,为什么能支撑更大的场景。

先来看云对网络的要求。首先是租户隔离,IaaS就是多租户,对于地址重用的要求,以VLAN的传统方式也是可以实现的。另外,传统VXLAN的协议或OVS的协议,只提供二层隔离的能力,没有三层隔离的能力,只要你的机器绑到外网IP,或者绑到公共的路由层面上,三层是可以互通的,所以说在租户隔离的层面,也有三层隔离的需求。
其次,云需要网络支持虚拟机跨机柜的迁移。VXLAN的话还要跨数据中心大二层,不是说不可以实现,但除了网络要求,还有存储的要求,比较难。虚拟机跨机柜的迁移,最难的是什么?传统网络架构,就是接入-汇聚-核心,路由器以下都是二层架构,机器可以在不同机架上迁移,但一个数据中心,云足够大的时候,二层基础网络是支撑不了整个云的,不同机架在不同三层里面,这时虚拟机做迁移就要要求IP地址不能变。
另外,还有网络功能和服务的要求。在云上面都是共享的资源池,如果以负载均衡为例,将一个性能强大的硬件负载均衡虚拟化给多个租户使用,还是切换成小的负载均衡虚拟机实例给不同租户使用?这里就提出网络虚拟化和网络功能虚拟化的需求,来支撑IaaS的运行。
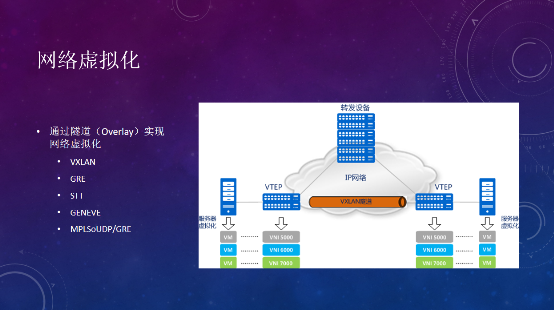
网络虚拟化,主要应用的是Overlay的技术,是SDN用到的其中一个技术,用的比较多、比较标准的技术,包括VXLAN、GRE、STT、GENEVE,以及Tungsten Fabric用到的MPLSoverUDP和MPLSoverGRE,主要的方式,是把二层的帧在vTEP上进行三层封装,通过VXLAN隧道传输到对端。
这样做的好处是,增加了租户的数量,传统VLAN是4096,如果VXLAN就是2的24次方;其次底层传输基于IP网络,扩展性远大于二层网络,使得网络能扩展,虚拟机在不同物理网段上迁移。但同样也带来一些工作,如何让两边的设备建立通信?第一建立VXLAN隧道,这是SDN控制器要做的事,第二是交换两边的MAC地址信息。
TF中文社区3月Meetup活动,将聚焦Tungsten Fabric与K8s的集成,由重量级嘉宾分享Tungsten Fabric与K8s的部署和实践,详细演示操作过程,并解答关于Tungsten Fabric和K8s的一切问题。关注“TF中文社区”公众号,后台点击“会议活动-Meetup”领取。
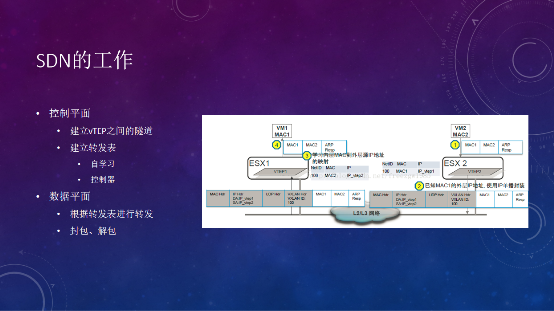
有两个VM,在两个不同的主机上,就是通过Overlay来解决二层通信问题的。比如ESX1要和ESX2通信,ping的时候首先发ARP请求,那对应的MAC地址是多少?对于VXLAN来说就要有一张转发表,MAC2需要通过VTEP2的IP,去做一个封包,再传输到VTEP2,解封装后,再传输到相应的机器里去。怎么建立这个转发表?就是SDN需要去做的事情。
一种是自学习,只要VM1发了一个ARP请求,到达vTEP网关,它就会去洪泛请求,广播到和它建立隧道的vTEP节点上去,看谁反馈ARP reply,就知道对端的IP地址,可以建立一个转发表。但这样会有很多消耗,ARP地址也有老化的过程,一旦老化,就需要重新去学,直观体验是ping包时间会很长。如果是大规模的网络,频繁洪泛,会对网络可靠性带来很大的挑战。
SDN大部分情况下是和云管平台做结合,知道在这个虚拟化服务器上,有哪些虚拟机,提前把MAC地址表或转发表下发到vTEP设备上,这就是SDN控制平面要做的事情。
在Open vSwitch这个方案里面,就是通过数据库和RabbitMQ,去下发一个OVSDB的命令,建立相应的流表,让虚拟机知道要往哪儿走。Tungsten Fabric也有相应的机制,后面会介绍。
数据平面的作用,就是根据转发表,对二层的帧进行转发,另外进行封包和解包。这里提一下MTU,这是这个二层的值,帧的transfer unit,为什么要设置很大?首先VXLAN协议会增加一些Hdr,UTP的Hdr,VXLAN的Hdr,封包的时候如果不做处理的话会超过1500,网卡会不发这个帧。早期做OpenStack经常会遇到trouble shooting的MTU问题,后来解决方案是通过DHCP的Agenter,设置了一个参数,如果网卡MTU是1500,就默认为14XX,自动降低,这样虚拟机的数据帧才能通过二层网卡。那么MTU的值设置多少合适呢?现在最佳实践是设置到9000。在vTEP这一块就是封包和转发,根据实际测试,如果增加MTU值,对吞吐量有很大的提高。

刚才说了SDN做的事情,控制下发转发表和传输,接下来说一下SDN的分类。按流派来区分,SDN可分为软件和硬件,区别就是vTEP是在vRouter上,还是在交换机的硬件转发上,看解封包在哪里。硬件一般都是私有协议,像Cisco用的就是OPFlex。软件也有很多不同的项目,其中Tungsten Fabric是最产品化的一个。
按照控制器分类,有集中式和分布式。集中式的控制器有OpenFlow、OVSDB,以及Tungsten Fabric使用XMPP(一个聊天的协议)。我们可以把Neutron的Open vSwitch理解为OVSDB协议,Neutron是通过RabbitMQ把信令下发到具体的计算节点,计算节点的OVS Agent通过OVSDB的命令,把相应的流表增加到OVSDB交换机。
分布式的控制器,比如EVPN-VXLAN,就是使用了MP-BGP。
大家觉得哪种形式的控制器会更好一点呢?目前用OpenDaylight的项目有哪些?华为,华三等都在用,其控制器的SDN架构就是参照OpenFlow来做的。有些厂商自己有研发能力,基于自身的硬件设备,可以开发一个比较完善的产品。但在开源社区,很少看到一个成功的OpenDaylight项目,只是提供了一个框架和一些组件,不能很快基于开源项目run起来。其实OpenFlow只是一个概念,从这几年SDN的发展来看,它并没有成为一个事实的标准。
反而是OVSDB起来了,应用在Neutron软件的控制,还有交换机的控制上。比如Tungsten Fabric早期的BMS实现,虚拟机要和裸机通信,裸机通过VLAN TAG,上到TOR交换机,再通过VLAN到VXLAN的转换,到达虚拟网络。其中VLAN到VXLAN的转换,就是通过OVSDB协议下发的。你的交换机,理论上只要支持OVSDB协议,就可以做BMS场景。
我自己更倾向于这种分布式的控制器。因为集中式的永远会有瓶颈,无论是软件瓶颈,还是性能瓶颈。而EVPN-VXLAN的核心协议是MP-BGP,BGP的扩展性有多大?看看现在Internet骨干网,跑的就是BGP协议。
MP-BGP的协议,通过控制器下发流表信息,再通过BGP协议去交互,使用的时候只要针对你的相应架构,去做相应BGP协议的扩展性设计就可以。
针对Tungsten Fabric来说,其实是集中式和分布式两种流派的融合,既用到集中式的架构,在对外的连接上,又采用了分布式控制器的技术。

总结大规模云平台对SDN的要求,第一是网络基础架构要可扩展。如果采用二层架构,瓶颈就是在基础架构上,受限于交换机的端口数,二层交换机采用生成树协议,对于大规模网络平台,如果运维水平较差,接出一个环路出来,就很危险。
第二,控制器是可扩展的。无论集中式还是分布式,在架构上一定是可扩展的,至于能支持多大的量,就是代码实现的问题了。
第三,数据平面无集中式单点。谈到SDN的实际应用,运维是一个比较大的挑战,无论是做开发还是做运维出身的人,最重要的是理解虚拟机之间,虚拟机到外网之间,数据流量是怎样的?应该通过什么命令去看这些流量,去trouble shooting,就像以前传统网络运维怎么去抓包一样。对于扩展性来说,要实现传统网络的SNAT、floating IP等,每个项目都有不同的实现方式,实现过程中没有单点的话,在架构上就是可以扩展的。
第四,跨集群的扩展网络。架构上无论怎样扩展,总是有极限的,对于一个单集群来说,总会到达一个瓶颈。如果要建一个更大的集群,可以横向扩展多个集群出来,形成一个大的资源池。那么面临的问题是,网络是否需要互通。如果部署一个高可用业务,跨集群的情况如何做互通,主流的一些高可用组件,需要跨两个集群二层互通,都需要SDN去支持这样的需求。
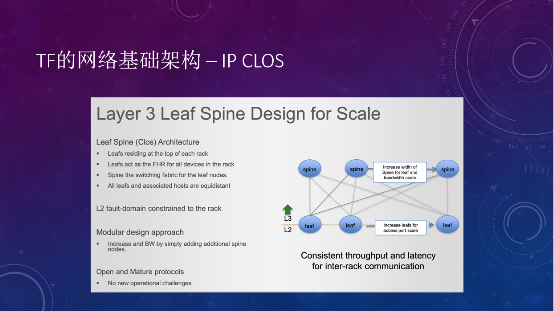
在基础架构上,如果用Tungsten Fabric,只要是用于生产环境的话,选择IP CLOS架构就行,没必要再去折腾Fabric等二层架构。IP CLOS可以带来足够的扩展性和高性能,包括没有供应商锁定,建完以后基本不需要再动。
Leaf就是架顶式交换机,下面是子网,不同机架用不同子网,上层通过三层网关路由做通信,最主要的就是Leaf Spine之间三层怎么交互。瞻博网络有个文档介绍IP CLOS的白皮书,对OSPF、ISIS、BGP进行了控制平面上的对比,最佳建议是用eBGP来做交互。
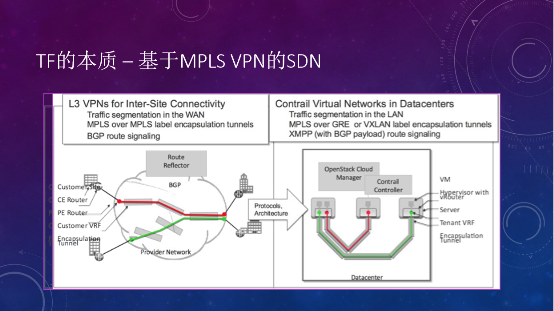
Tungsten Fabric的本质是基于MPLS VPN的SDN。原来的VPN是解决多个site之间的互联,控制平面是BGP协议。到了数据中心里面,云之间的互联,一个物理机可以看做一个site,不同物理机之间借助VPN建立不同的隧道来打通,这就是Tungsten Fabric的本质。不同之处在于控制平面,Tungsten Fabric用的是集中式的控制器并通过XMPP协议控制vRouter的路由表。
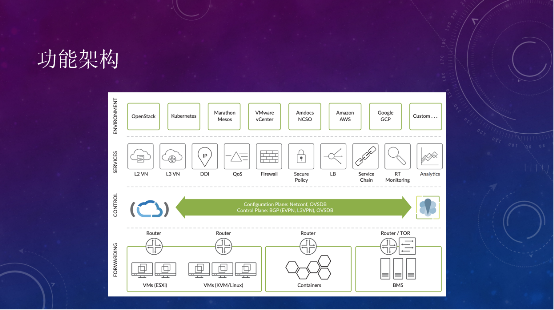
简单看一下Tungsten Fabric的功能架构,在多云支持上,包括VMware、OpenStack容器、BMS;网络功能上,二层网络、三层网络、DHCP、DNS、QoS、防火墙、LB等都是支持的。
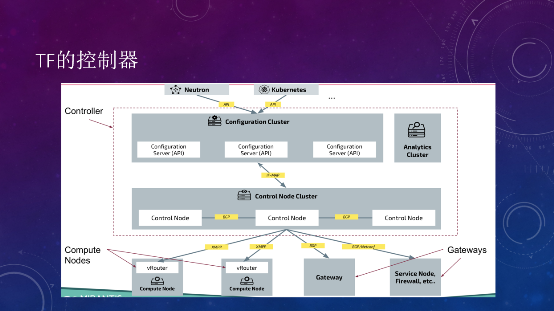
在部署的时候,控制器主要分为两种节点,一种是Analytics Cluster分析节点,主要做流的可视化。另外一种Controller节点用来控制网络,分为Configuration和Control Node,前者提供API,对接Neutron等云管平台,API通过创建一个pod,在Configuration上记录数据库,转换成相应的IF-MAP,控制器通过XMPP命令在vRouter上创建相应的接口,再把接口信息传给不同的vRouter或外部网关及硬件设备,控制器核心协议是BGP协议。
控制器在整个Tungsten Fabric里就是一个router reflector,把所有的二层接口、MAC接口信息,三层路由信息全部存在这里,分发到不同的vRouter上面。对于云内的vRouter,用XMPP推送,对于云外的Gateway等,通过BGP推送。
其中,NETCONF协议不是用来推送路由信息的,主要用于和网络硬件设备的一些配置下发。比如Tungsten Fabric中增加一个BMS服务器接入到Tungsten Fabric管理的虚拟网络,Tungsten Fabric中的Device Manager会通过NETCONF将VLAN接口的配置和下发到TOR交换机,通过NETCONF建立接口。然后Tungsten Fabric控制器再通过OVSDB协议或EVPN-VXLAN协议去配置相应的VLAN-VXLAN的桥接网关。如果需要把虚拟网络扩展到Gateway,NETCONF也会帮助创建相应的Routing instance配置。路由层面的交换信息,还是通过BGP来实现。
TF中文社区3月Meetup活动,将聚焦Tungsten Fabric与K8s的集成,由重量级嘉宾分享Tungsten Fabric与K8s的部署和实践,详细演示操作过程,并解答关于Tungsten Fabric和K8s的一切问题。关注“TF中文社区”公众号,后台点击“会议活动-Meetup”领取。
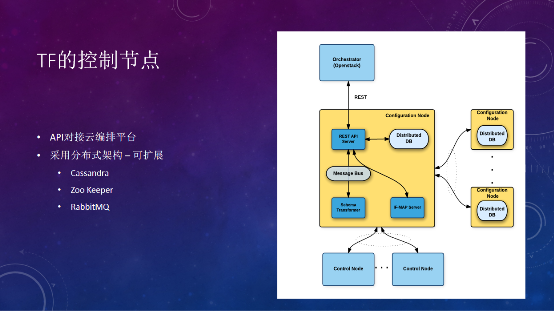
Tungsten Fabric用到的数据库,都是最近8年才有的,比如分布式数据库的Cassandra、Zoo Keeper、RabbitMQ,在架构上是高可用、可扩展的,具体能扩展到多大的量,还是要看代码实现。反过来看Neutron,本质就是一个数据库,记录了所有的信息,把所有的流表下发下去。
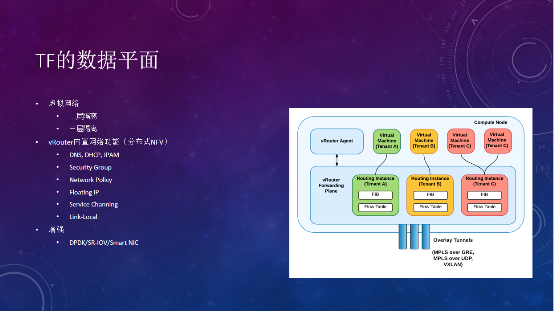
Tungsten Fabric的数据平面主要是通过vRouter来做转发,vRouter agent在user namespace的进程,安排控制器基于XMPP连接拿到一些信息,再下发到kernel的转发平面。这里提供了二层隔离和三层隔离的功能,如果说同一个网络的虚拟机,接在同一个vRouter下面,双方的通信就在这里完成。不同租户的网络虚拟机,接了不同的VRF、Routing instance,也是不能通信的。
vRouter内置了很多网络功能,比如DNS。Tungsten Fabric的DNS会根据主机的DNS配置来解析,如果遇到问题,可以检查一下主机的DNS有没有问题。DHCP应答也在这里,Neutron就不一样,专门有一个DHCP agent跑在一个节点上,OVS在大规模情况下,如果接了超过1500个接口,基本上就会出现丢包,并且经常出问题。
Security Group在OVS的实现是通过和linux bridge关联的iptables实现的,而在vRouter就是通过内置的ACL功能实现。Network Policy就是一个分布式的防火墙。Floating IP也是在vRouter做了一个NAT出去。
这里多谈一下Link-Local,它的场景是什么?作为一个云服务商,要向客户提供NTP服务、ATP、YUM源、等公共服务。怎么让虚拟机在虚拟网络内访问到一个公共服务呢?一种方式是把这些网络的路由打通,因为需要一个VTEP出口,通过cloud gateway把公共路由导进去,这样带来一个问题,所有ATP流量、下载流量都要通过cloud gateway,流量会跟大。Tungsten Fabric提供一个Link-Local的模式,就是一个169.254的地址,在网络标准里只有一跳。在OpenStack虚拟机或AWS虚拟机里面,metadata服务就是通过169.254提供的。本机没有这个路由,到网关上对地址做一层NAT,本机的NAT就会访问到配置的Link-Local映射,继而访问到内部的服务。
在没有增强的前提下,实测Neutron的OVS VXLAN的性能(只做MTU的优化),最多达到两个千兆的性能。而vRouter在不做任何优化的前提下,能达到七、八千兆的性能。当然也可以利用DPDK、Smart NIC来做优化,或者利用SR-IOV的透传功能。
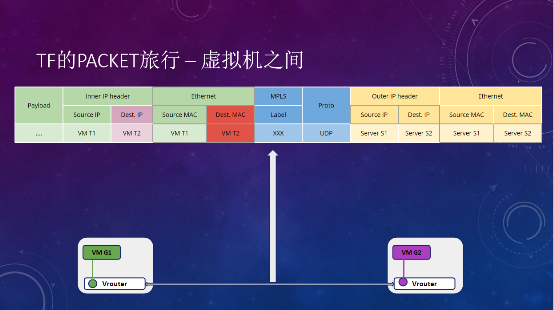
再来看看Tungsten Fabric的Packet交互。无论是同网段还是不同网段,虚拟机之间的交互,都是在vRouter层面转发的,不会经过一个集中式的gateway。所以在虚拟机之间的数据交互层面,是没有单点的。
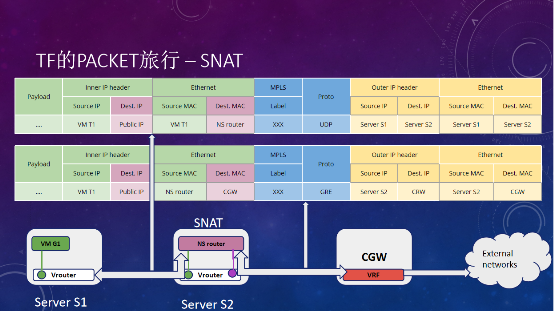
另外一个比较重要的场景是SNAT。在OpenStack里面,如果虚拟机接了一个vRouter,可以通过vRouter的SNAT功能去访问external的网段。Tungsten Fabric本身其实不提供SNAT,但也实现了SNAT功能,通过NS router(跑在计算节点的一个IP tables)做一个SNAT的转发,如果虚拟机要访问一个非本网关的网络,先到gateway,转发后,再通过vRouter连接external的网络。这里NS router的创建,需要OpenStack nova的scheduler来配合。
对于每一个网络,都会有一个router去做转发,如果量太大,瓶颈可能就在NS router这里,但不会影响其它的网络。
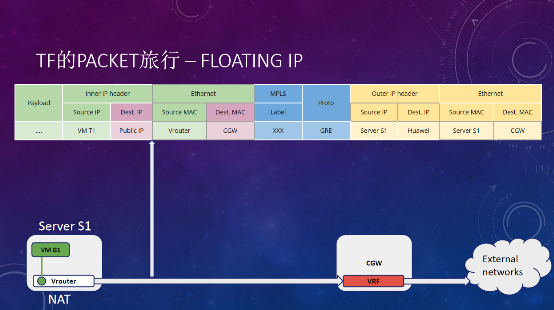
只要不在云内,都可以叫外网,要出外网有两种方式:第一种是Floating IP,在vRouter做了一个NAT,把NAT后的IP通过MPLS over GRE的隧道,发布到Cloud Gateway的某个VRF里面,和外网通信。
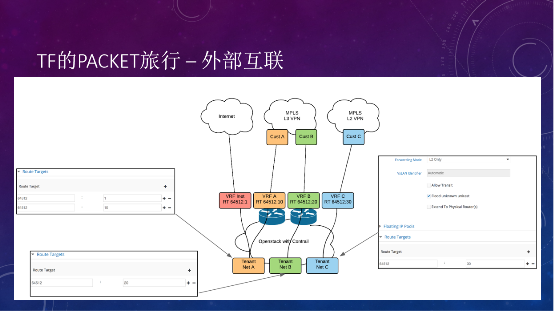
第二种外部互联的场景,假如要提供一个云服务,可以针对不同的运营商做不同的flouting IP,如果做L3 VPN或L2 VPN的专线接入服务,可以通过cloud gateway接入到不同的MPLS网络,再把虚拟网络路由到相应的VRF,整个就都连通了。这也是Tungsten Fabric强大的地方,MPLS VPN是和传统的网络天然互联互通的。
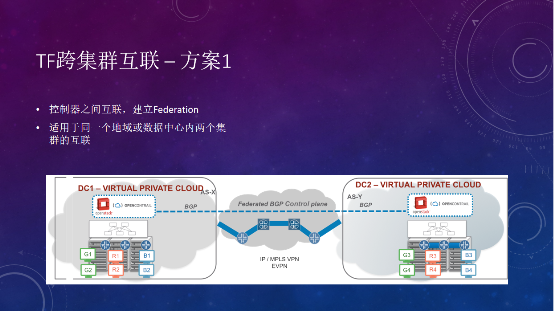
跨集群的互联,或者叫多云互联,主要有两种模式。
第一种是基于控制器之间的互联,把VPN、网络和接口的信息,通过控制器之间建立EBGP连接来传输,这种方案叫Federation。
两边的vRouter只要三层可达就可以,比如一边的B1要访问另一边的B3,两边是不同的控制器和VPN,MPLS VPN有个route target,一边export一边import,路由表看到另一边的路由,进行路由信息交互,从而建立二层或者三层连接。Federation的方案是在控制器层面实现的,比较适合于同一个地域,同一个数据中心,有比较近的连接的情况。
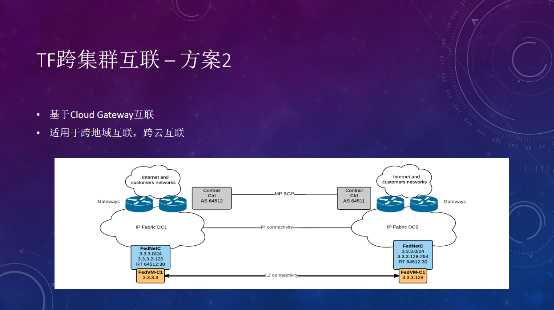
第二种模式是通过cloud gateway之间的互联,把网络的不同VRF,在cloud gateway之间建立EBGP邻居,手动配置去import或export不同的RT,实现跨云的连接。需要注意的是,两边是不同的集群,IP地址管理不一样的,分配地址的时候,要避免IP地址的重叠。

最后,和Neutron OVS进行对标的话,Tungsten Fabric可以说是完胜的。
基础网络方面,Tungsten Fabric可以扩展,Neutron OVS目前只能用二层网络,无论集中式还是分布式,floating IP下沉到计算节点这一层,目前的组件里都没有成熟的BGP方案,能够把floating IP发布到边界网关,OVS DVR和边界网关只能通过二层连接。
对比架构方面,Tungsten Fabric是可扩展的,3个节点性能不够,可以扩展到5个节点。Neutron OVS虽然是一个高可用架构,通过MySQL集群实现数据库高可用,通过K8s实现API高可用,但计算逻辑不是分布式的,严重依赖RabbitMQ。如果使用DVR模式,每个计算节点要部署四个agent,带来更多的topic,对RabbitMQ的性能是很大的挑战,只要出现一个RabbitMQ宕机或网络抖动,会马上执行集群恢复机制,导致RabbitMQ很快死掉。
另外,在转发平面上,Open vSwitch的性能没有vRouter好;Tungsten Fabric的网络功能更丰富,而Neutron的Octavia等原生LBaaS组件也有待成熟;多云互联方面Tungsten Fabric基于MPLS VPN;和网络设备的交互方面,Neutron只有ironic的networking generic switc driver,Tungsten Fabric支持BGP、NETCONF、EVPN-VXLAN等,基于标准的协议,涵盖了瞻博网络、思科、华为、锐捷等厂商的设备。
今天就先分享到这里。谢谢大家!
本次演讲及TF中文社区“2020第一次Meetup”活动资料,请在“TF中文社区”公众号后台点击“会议活动-Meetup”领取。
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























