

摘要:一个历时4个多月、吸引了5618位参赛选手、Michael I. Jordan和蚂蚁金服CTO亲自在证书上签名的大赛。
杭州·云栖大会期间,首届“ATEC 蚂蚁开发者大赛人工智能大赛”在ATEC展馆落下帷幕。
此次大赛于今年4月18日预报名启动,8月26日复赛结束,持续时长131天。“不错的业务场景”及“真实的数据集”吸引了来自来自全球20多个国家地区1000所院校及企业,近1/3海外高校,共5618位选手参赛,是一场真正的国际化顶级比赛!
值得一提的是,参赛者中,拥有硕士及以上学历的占比70%,行业界人士占比40%,这让此次比赛更为激烈和贴近实战。
此次大赛分为“风险大脑-支付风险识别”、“金融大脑-智能客服NLP相似度计算”两个赛道,两个赛道各有五支队伍进入决赛,进行现场演示和答辩。排名前三的团队(共6支队伍)共获得120万元现金奖励,并获得直通蚂蚁金服集团技术岗的终面资格。
颁奖典礼上,蚂蚁金服科学智囊团主席、加州大学伯克利分校教授Michael I. Jordan,蚂蚁金服副总裁、首席数据科学家漆远等学术及行业嘉宾为获奖团队颁发了获奖证书并签名、合影留念。

Michael I. Jordan在获奖证书上签名
清华大学朱军教授、哈尔滨工业大学刘挺教授也出席了颁奖典礼,他们是大赛评委。
朱军教授是支付大脑的评委之一,他对比赛做出了这样的点评:“AI用到金融里,现在不管是学术界或者是应用,都是大家比较关心的。但是AI要用到行业里、想做出好的解决方案,需要对问题和场景有非常深入的理解。我觉得你们都非常了不起,能够把机器学习算法用到实际里。虽然大家的思路都比较一致,但我觉得里面有很多精细的工作,做得还非常漂亮。特别是看到除了特征工程之外,大家对原理和方法有一些自己的思考,我觉得这个是特别值得鼓励的。不管是从学术界还是从工业界来看,我希望能够看到更多更有意思的例子和成果。”
金融大脑的比赛结束后,刘挺教授现场致辞:“现在这个时代真的是工业界领先的时代,搞NLP的人,我们的优势是能够和工业界结合,去拿到他们的真实数据。我们现在有机会和工业界合作,我希望大家更多去倾听工业界的声音,他们提炼出真实的问题、提供真实的数据。未来,希望大家能更深入地去分析,从原理上、从本源处去发明创造,去拐大弯儿。”
“优秀的数据集和场景”吸引了参赛经验丰富的工程师应缜哲,他是金融大脑赛道亚军Skyhigh的队长。Skyhigh是一支参赛经验丰富的队伍,共有三名成员,除了已经工作了的应缜哲,还有两位研究生。自2017年认识以来,三人组团参加了五六次比赛,且都取得了不错的成绩。
应缜哲说,“这次比赛是国内一个非常好的中文的课题,这种赛题非常少。数据很真实,我们做了很多特征工程,这是这个比赛我认为最有意思、也是我花时间最多的地方。如果下次比赛,赛题还这么有趣,我还会来的。”
蚂蚁金服这次精心呈上的两个经典赛题究竟是什么?两支冠军队伍又分别给出了怎样的解题方案?下文将作出详细解答。
“风控老兵”来参赛,斩获冠军
移动互联网的新金融业务在蓬勃发展的同时,黑产攻击的能力也在不断升级。信息泄露导致过亿的敏感数据被盗用、利用,给用户和银行带来了巨大的经济损失。保护消费者和风险识别,越来越成为金融行业和学术界关注的焦点。
在这一背景下,蚂蚁金服设置了“支付风险识别”的赛题:用2017年9月到10月的交易数据构建算法,识别2018年2月的交易欺诈行为。
这一赛题,吸引了多位金融科技领域的资深从业人士来参赛。斩获冠军的,也是“风控行业的老兵”,他们的解决方案兼具“创新性”和“实用性”。
“我们是一支来自上海的队伍。”“谋杀电冰箱”的队长熊文文说,团队共有4人,平均年龄27岁,都来自互联网金融行业,对风险控制和风险模型的开发有一定的了解。
“这个比赛提供了一个新场景——支付场景,大家就都想试一试。”熊文文说,他们之前在信贷场景下做风险控制,不同于支付场景中的风险控制,“信贷主要是刻画一个人(账户)的资质情况,支付不是刻画账户的资质、而是刻画某单交易异常的情况。”
如何解题?他们的特征工程以交易的账户(人)、交易账户所处的环境、与这个账户交易的商户三个要素为核心,结合这三要素交叉时间维度,寻找静/动态异常交易的特征。
通过数据分析,他们发现,“盗刷交易存在一定的集中性”。比如,1%的用户覆盖了80%的盗刷时间;某用户在3天内被盗刷几百次;某交易方(也即商户)交易1175次,其中80%是盗刷。“如果之前的交易就是有风险的,如果能检测到之前风险的话,那我就可以在判定这单交易时,把风险加进去。”于是,他们创新地提出了“先验风险信息”的概念,并设计了一个可以提炼先验风险信息的模型结构来强化识别效果。
他们将数据按照时间的先后分为第一个月的数据和第二个月的数据。首先,通过第一个月的数据训练3个子模型(各有侧重),这3个子模型的AUC停留在0.986左右,判定分数在0.56-0.57之间;再利用3个子模型对第二个月的数据进行预测,进而得到第二个月每单交易的三个风险分数(即先验风险);最后通过风险分数及其衍生变量,加上第二个月数据的常规变量,训练得到模型D。模型D给出的结果即为最后的结果。最终,模型D线下的测试AUC可以达到0.991,线下的判定分数能达到0.7。
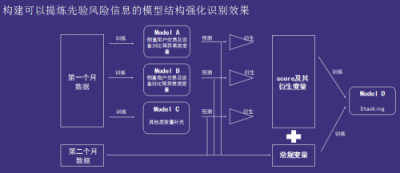
此外,他们还挖掘了一些白名单的规则:如,用户每月3000笔以后的交易可以直接定义为正常;设备每月400笔之后,可以定义为正常。“通过白名单的规则,大概可以覆盖10%的样本。通过白名单规则,又可以将判定分数提升几个千分位。”
分时间段建模、将效果不好的早期数据化作变量、进行融合建模的做法以及策略+模型的解题思路,让他们取得了第一名的成绩(A榜得分0.627,B榜得分0.797),也斩获了评委们的心。
逆袭:从第十一到第一,“有一种触电的感觉”
“金融大脑”的赛题是问题相似度计算,即给定客服里用户描述的两句话,用算法来判断是否表示了相同的语义。
“这个任务非常有实用价值。“一支优秀的队伍”是此赛道的冠军,队长段誉说:“想象你在做一个客服系统,事先会有一个问题-答案的表单,客服的工作其实就是在面对用户的提问时,迅速找到与之最接近的问题,并整理出答案来给用户。文本匹配系统一旦做的好了,可以直接解决第二个阶段的问题,也是最需要人力的部分——找到最接近的问题,这能大大减轻客服的压力,让他们去解决真正困难的问题。”
最先获知这个比赛的是研一师弟梁嘉辉,他刚开始接触NLP,“想通过这个比赛提高自己的能力”。因为一个人参赛难度太大,便找到“正处于学术空档期”的段誉(研三),共同组队参加比赛。一个关键BUG的解决让他们从第十一逆袭到第一,“有一种触电感觉”。
与进入决赛的其他4支队伍相比,他们在特征工程上花费了很少的时间,主要立足于对模型的充分改进和探索,将单一模型的效果发挥到了极致。
他们的最佳成绩是将三个模型ensemble后得来的,这三个模型结构大概相同,只在细节(例如模型输入)上有细微差别。他们的最优模型如下:
首先,他们的模型输入为五个层面的char-level feature,除exact match、idf外,自动提取了几个特征:用skip-gram在本地训练300维char embedding,为了防止过拟合,训练时是fix住的;为了弥补因fix而损失的模型能力,额外引入了50维可以训练的char embedding;利用其他文献的方法分别提取了1维的句子间特征以及1维的句子本身特征。
通过输入层后,引入Noise+Dropout,用来提升模型鲁棒性,再用bi-GRU当作encoder,并引入fuse gate来加速信息流通,然后用一层mlp+残差进一步整合信息。之后对两个句子进行对齐。对齐之后,通过正交分解,分别提取相关性和不相关性的信息。
用Multi-Head attention + Multi-Head pooling对相关信息、不相关信息进行推断后,再过一次一层mlp+残差,然后分别得到相关信息表达、不相关信息表达。用fuse gate对两方面的信息综合考虑后,再经过dropout以及两层MLP,得出最终的结果。

段誉在论坛里分享了自己的经验,他写道:“从一开始我们就选择了ESIM模型,相比现在动不动就好多层网络结构的NLI模型,ESIM思路清晰、能说服我们、网络结构相对简单、没有用很多trick、扩展性也强、效果很棒,所以就一眼相中了。”
“对于NLP语义相似度识别这个任务来讲,模型的潜力是蛮大的,我们没有做任何的预处理,完整地保留了每个句子的所有信息(当然了padding和截取是必须的)。我们没有使用词级别的向量,而是纯用的字级别的向量,在做实验的过程中发现基于词级别的结果普遍要差一点,这和分词质量不无关系,而且本人认为GRU、LSTM这样的网络因为引入了fuse gate,已经具备一定程度的分词作用了。但是可以料想的是,如果经过了良好的分词处理,结合word和char级别的embedding,应该是有一定帮助的。”
梁嘉辉表示,通过参加这次大赛,他体验到了深度学习的魅力,也明确了未来的研究方向,“就是NLP(自然语言处理)”。
通过大赛解决实际问题,是蚂蚁金服的初衷。“我们非常欢迎更多人参与进来,能够去学习新技术、用技术解决实际问题。”蚂蚁技术合作与发展部的柴文意是此次大赛的负责人,她表示,此次比赛结束后,蚂蚁金服将会把赛题和数据开放出来,也会尽可能地将参赛者的策略、方案应用到蚂蚁金服的真实场景中去。
漆远表示,“这(此次比赛)只是一个开始,我们会把这个作为一个长期的机制——打榜机制,开放出平台,让更多朋友参加这个比赛。”

蚂蚁金服副总裁、首席数据科学家漆远
“ATEC大赛是一个非常好的链接生态的平台,将会持续举办。”柴文意表示,接下来,他们会在不同领域推出不同赛题,把行业中一些通用的问题提炼出来,把一些脱敏过的数据开放给选手,“让他们在这个过程中得到锻炼和学习”。
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























