
10月11日消息(岳明)让我们把时钟拨回到7年前,2017年6月,AMD推出了公司面向数据中心市场的EPYC系列,凭借多核设计、PCIe 扩展选项以及原始内存带宽等优势,EPYC开始展露头脚。

七年后的今天,AMD EPYC CPU市场份额已经从原来的不足2%,持续成长到今年上半年的34%,七年之内实现了17倍的份额提升!但这显然不是AMD的终极目标。
在本周举行的Advancing AI 2024大会上,AMD董事会主席兼首席执行官苏姿丰博士指出,“展望未来,我们看到,2028年,数据中心、人工智能、加速器市场将增长至5000亿美元。通过我们扩展的芯片、软件、网络和集群级解决方案,我们致力于提供大量开放式创新。”
端到端的AI,这将是AMD的新战场,而且AMD已经做好了全方位的准备。
全方位升级:第五代EPYC处理器重磅登场
作为AMD的明星产品,在今天的Advancing AI 2024大会上,AMD正式发布了家族代号为“Turin”的第五代EPYC处理器,全系采用台积电3/4nm制程工艺打造,最高支持192核384线程,频率最高达到5GHz,AVX512指令集支持完整的512位宽的数据路径,整体IPC提升17%,并且兼容现有的SP5平台,在密度、能效、宽开路堆栈方面实现了全方位升级。

具体来看,得益于Zen5架构高度的灵活性,第五代EPYC处理器在架构封装方面更为灵活。既能够打造出最高16个Zen5 CCD的128核256核全大核处理器,也能够打造出最高12个Zen5c CCD的192核384线程的全小核处理器,可以为不同客户提供丰富的、多元化的选择。
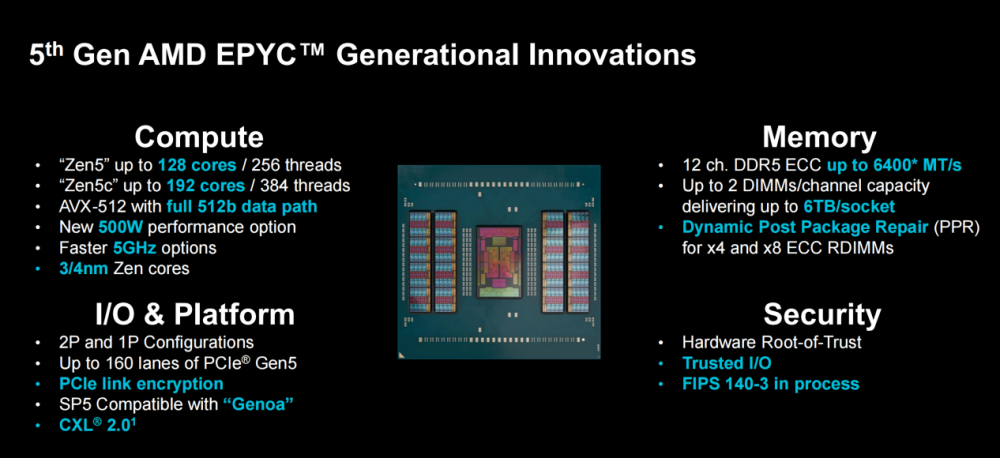
同时,第五代EPYC处理器家族在ISA和IPC方面得到提升,其核心数量从8核延展到192核心,TDP从155W到500W,并且升级支持12通道DDR5-6400内存,支持128 PCIe5.0/CXL 2.0,并且提供更高度安全性的I/O。

以全新的AMD EPYC 9005系列处理器中的EPYC 9965为例,对比英特尔相关产品,SPEC CPU 2017整数吞吐量是其2.7倍;在视频转码、商用APP、开源数据库、图片渲染等工作负载性能方面,最高达到了4倍的性能提升;企业级HPC性能方面,性能提升3.9倍;基于CPU的AI性能提升3.8倍,Llama3.1-70B大模型为基准的GPU Host节点提升1.2倍。

在数据中心服务器升级换代方面,第五代EPYC的升级难度以及成本相对更低。1000台老旧英特尔至强白金8280服务器可以用131台EPYC 9965服务器替代,能耗仅为原来的68%,服务器数量减少87%,3年TCO降低67%,可以有效帮助企业用户节约空间与能耗。
根基已稳:AMD Instinct稳步前行
作为智算算力的重要载体,GPU是市场关注的焦点;作为为数不多能与英伟达正面抗衡的厂商,AMD在AI加速器市场的举措,无疑备受关注。

在Advancing AI 2024大会上,AMD也拿出了自己的诚意,正式发布了更新版本的Instinct MI325X加速器。
作为MI300X的升级版本GPU,MI325X配置了288GB HBM3E内存和6TB/秒的内存带宽;也正是因为在内存和带宽方面的优化,AMD Instinct MI325X在多个模型的推理表现领域优于英伟达H200。
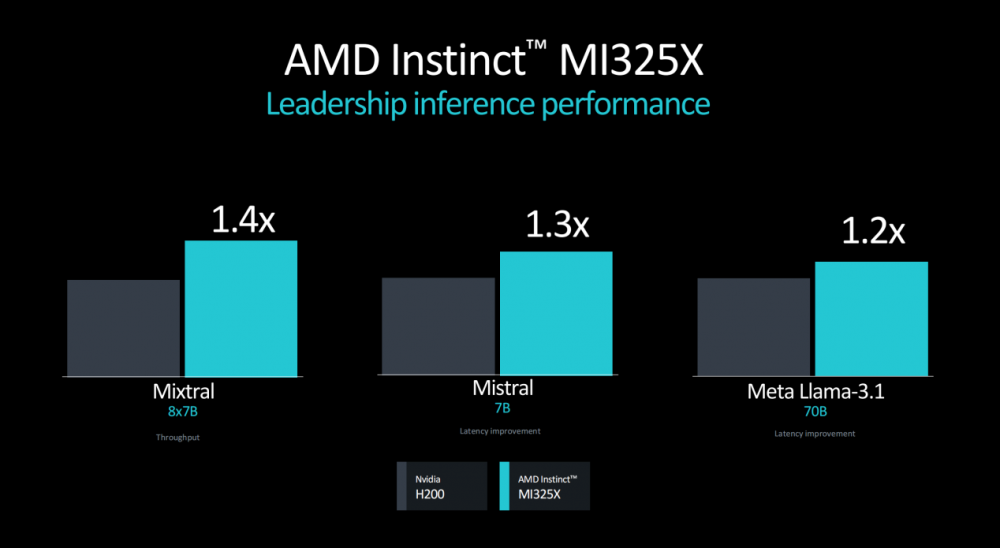

AMD提供的测试数据显示,在多个模型的推理表现领域,AMD Instinct MI325X优于英伟达H200。在训练方面,无论是在单GPU还是在8 GPU的Meta Llama-2训练场景,AMD Instinct MI325X平台的表现也都优于英伟达H200。

对于芯片厂商而言,清晰明确是技术路线图是取信于用户与市场的关键。AMD Instinct 加速器的下一代产品——AMD Instinct MI350系列应该将于2025年面世;AMD Instinct MI400系列或将于2026年亮相。

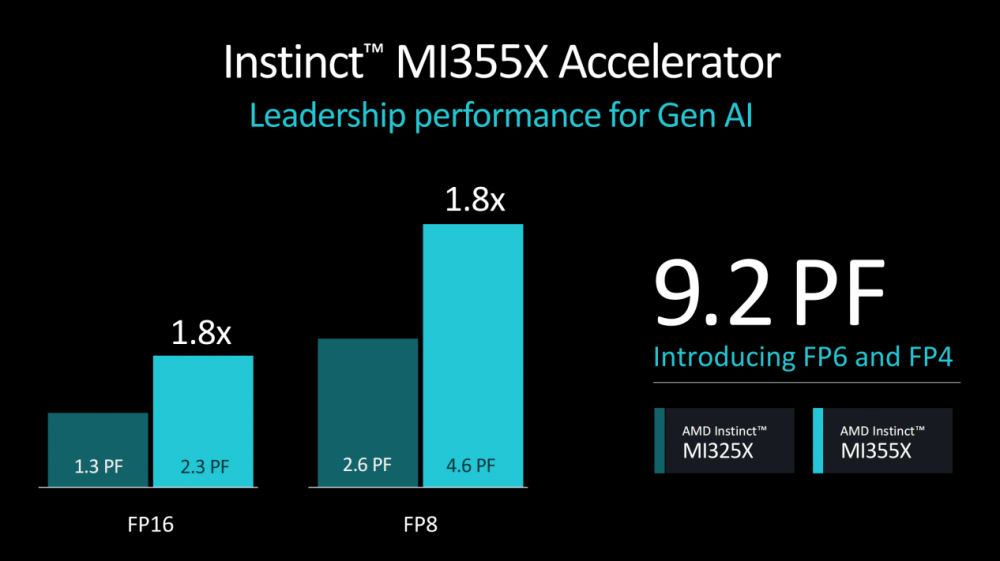
与前两代产品不同,AMD Instinct MI350系列产品预计基于AMD CDNA 4架构设计;同时,AMD Instinct MI350系列产品还将使用了先进的3nm工艺技术构建,搭载高达288 GB的HBM3E内存,并支持FP4和FP6 AI数据类型,进一步提升了整体的性能表现。

同时,为了降低开发者的使用门槛,AMD还将持续更新其ROCm系列,推动最广泛使用的AI框架、库和模型对AMD计算引擎的支持,最终实现AMD Instinct加速器在流行的生成 AI 模型(如 Stable Diffusion 3、Meta Llama3、3.1 和 3.2 以及 Hugging Face 上的一百多万个模型)上的开箱即用的性能和支持。
加速AI网络扩展:以太网+DPU+AI NIC将是“神组合”
谈到AI,可能很多人的第一反应是CPU/GPU,是算力短缺;但实际上,网络正在成为制约AI系统性能的关键,平均30%的训练时间被用来等待联网;而在分布式推理中,通信更是占40%-75%的时间。这对于动辄部署万卡集群的用户而言是难以承受的。
如何去构建这张网络,在此次Advancing AI 2024大会上,AMD给出的答案是以太网+DPU+AI NIC。在此次大会上,AMD正式发布了基于P4引擎的第三代DPU产品Pensando Salina 400以及Pensando Pollara 400。

Pensando Salina 400是一个面向前端网络的DPU,也是是全球性能最高、可编程性最强的DPU产品。与上一代产品相比,其性能、带宽和规模提高了2倍。同时,该DPU还支持400G吞吐量以实现快速数据传输速率,可优化数据驱动型 AI 应用的性能、效率、安全性和可扩展性。

Pensando Pollara 400则是业内首个UEC ready AI NIC,支持下一代RDMA软件和开放的网络生态系统,可以在后端网络中提供加速器到加速器通信的领先性能、可扩展性和效率。在产品上市时间方面,Pensando Salina DPU和Pensando Pollara 400 均在今年第四季度向客户提供样品,并有望在明年上半年上市。
聚焦商用PC市场:锐龙 AI PRO 300实现端到端AI
对于企业级用户而言,AI不能飘在空中。作为当前最主要的生产力工具,PC则是实现AI落地的最佳载体。
在Advancing AI 2024大会上上,AMD就正式推出了面向移动商用市场的锐龙AI PRO 300系列,抢占商用AI PC市场的先机。

作为首款专为企业Copilot+PC而设计的芯片,锐龙AI PRO 300 CPU部分采用Zen 5架构,NPU采用XDNA 2架构,GPU采用RDNA 3.5架构。其中NPU算力提升到至高55 TOPS,完全满足微软Copilot+PC 40 TOPS以上的条件。

为了满足多个应用场景的需求,AMD 锐龙AI PRO 300提供了三个SKU供选择。与竞争对手的同类型产品相比,锐龙AI PRO 300系列的表现全面领先。例如在与Intel Core Ultra 7 165U相比时,AMD锐龙AI 7 PRO 360的CPU性能领先30% ;与Intel Core Ultra 7 165H相比时,锐龙AI 9 HX PRO 375 CPU的性能更是领先40%。
作为终端生产力工具,续航能力同样非常重要。由于采用了领先的4nm制程,搭载这款移动商用处理器的AI PC一般使用时间可达23小时;连续使用Microsoft Teams进行视频会议,续航也可超过9小时。
写在最后:
面向确定性的AI未来,无论是CPU、GPU、DPU,还是软件,或亦是网络和集群解决方案,AMD已经做好了准备,开启新的黄金十年。正如苏姿丰博士在社交媒体上所言:“10年前,我有幸被任命为AMD的首席执行官。这是一段令人难以置信的旅程,有很多值得骄傲的时刻。今天,我要感谢全球的AMD团队所做的一切。尽管过去的10年令人惊叹,但最好的还在后面。”
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























