
7月2日消息(林想)在日前召开的“GSMA Thrive 5G时代”主题视频活动中,赛灵思高级总监Harpinder Matharu表示,随着越来越多运营商开始进行5G部署,系统供应商不断寻求各种方法解决5G部署与性能短板。此外,3GPP标准第16版即将完成,预计将引入几项强化功能和用例。这对下一代5G系统的需求呈现出“新变化”。而赛灵思推出的Versal ACAP是一种新型可编程SoC,旨在满足下一代5G设备的这种“新变化”。

赛灵思高级总监Harpinder Marharu
改进大规模MIMO系统的“四大研发领域”
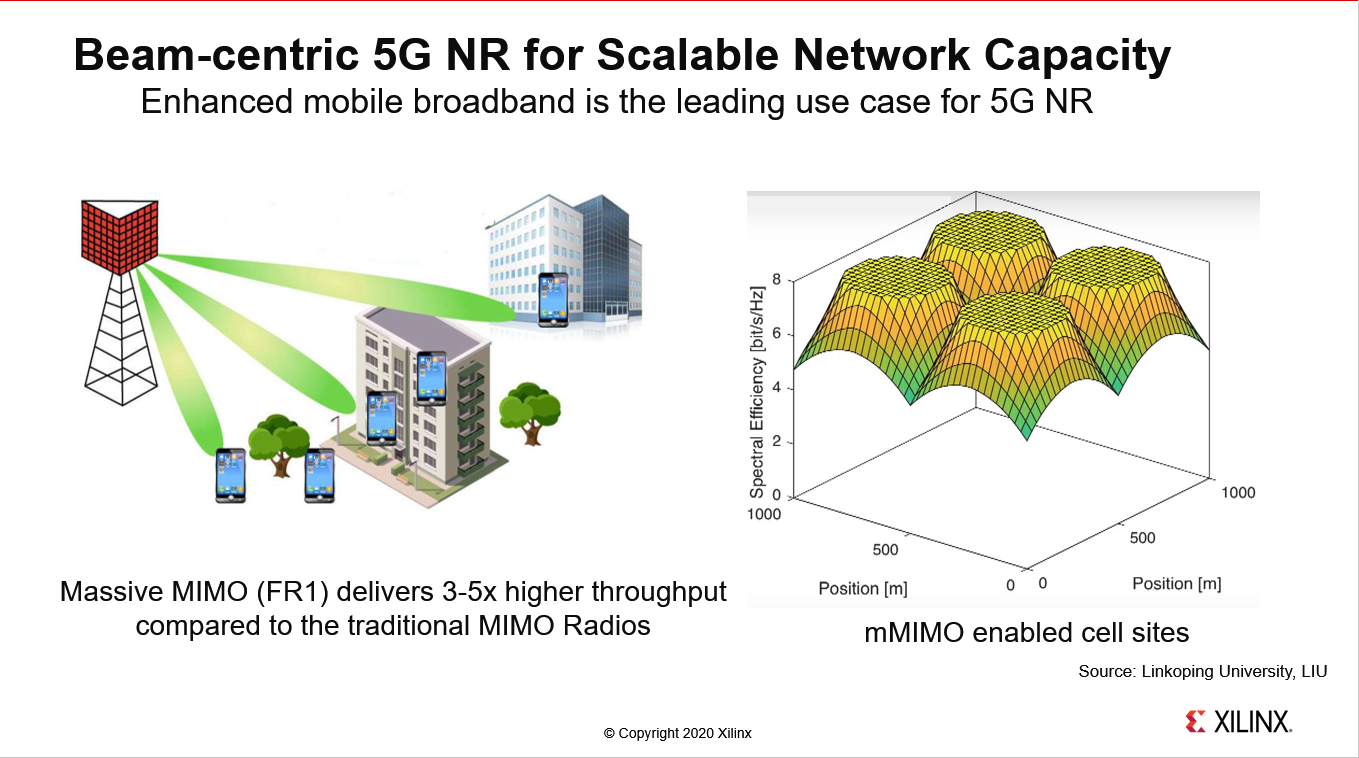
基于波束成型技术的5G NR 6GHz以下大规模MIMO系统已经成为全球商业5G部署的主流。
第一轮5G部署的主要用例是增强型移动宽带应用,这是为了解决网络中快速增长的吞吐量需求,平均每15-18个月翻一番。大规模MIMO系统可提供扩展性容量强化,并在整个片区内实现更一致的频谱效率改进。仿真与场测结果表明,如果我们持续使用传统的微基站对现有网络进行增密,则频谱效率并不统一,容量和覆盖上限仍然存在。
然而,对于大规模MIMO系统来说,情况并非如此,大规模MIMO系统的关键区别在于通过使用波束成形来调度多个用户同时使用频谱和频率源的能力。与传统的MIMO无线电相比,大规模MIMO系统的目标是3-5倍的性能提升。
Harpinder Singh Matharu指出,大规模MIMO系统在场测中实际情况与仿真结果并不一致。“虽然下行链路性能处于预期带宽的低端,上行链路性能和覆盖范围更是低于预期。对于小区边缘信噪比较低的UE情况尤其如此。此外,并非所有时刻都有多个用户供系统调度,当小区负载较轻时,大规模MIMO系统提供的容量难以得到充分利用。这需要调度增强特性和跨层优化来弥补这些缺点。”
Harpinder Singh Matharu认为,改进大规模MIMO系统的领先研发领域包括天线面板创新、改进波束形成管理、更好的调度算法和跨层优化,以及跨相邻片区的协调多点传输。
对天线面板的增强,可以通过自适应算法合并每个天线单元上的接收信号来提高接收信号功率。这需要对与自适应天线面板相关联的开关电路进行充分的校准和配置,这些功能通过DFE数字设备实施。
Harpinder Singh Matharu指出,“3GPP标准第16版针列出了几项研究,在某些情况下放宽对UE使用全功率发射的限制。例如,具有未覆盖或部分覆盖的天线的UE会由于预编码器的限制,仅使用天线的子集进行发射。因此,未使用的天线和相关的PL排列会导致发射功率的损失。”
降低参考信号的峰均比 (PA/PR) 也是支持UE以全功率传输的考虑因素。这将有助于减少上行链路覆盖问题,并在上行链路上支持更多空间流。当前系统支持的上行空间流数约为8个,但在实际应用中,很难达到所有空间流都能同时使用的场景。
更精确的信道估计、更多与信道估计相关的参考信号,以及更快的波束成形系数更新也在研究中。调度器、每个用户的信道估计和波束管理的跨层优化都是大规模MIMO系统整体性能改善的主要研究领域。
“改进调度器的机器学习技术是业界提出的另一项研究课题。”Harpinder Singh Matharu表示,基站根据用户地理位置或基于移动角度、往返时间等因素的定位维护有价值的数据集,每个用户的历史波束字典、信道估计和调度用户组合。可以使用这些数据集来训练机器模型,以准确地预测要在给定情况下调度的UE的最佳集合。这将有可能为调度器提供有价值的输入。
综上所述,赛灵思确立了对大规模MIMO系统进行改进所需的一些算法与功能。有鉴于此,目前提出的许多方法显著提高了计算需求和波束成形要求,以及额外的前端设备数量。

下一代5G设备需求呈现“新变化”
“随着越来越多的运营商尝试进行5G部署和3GPP第16版标准的准备工作,对下一代5G设备的需求因此发生了变化。”Harpinder Singh Matharu进一步指出,“下一代5G系统对中频或C频段的典型带宽要求是400MHz瞬时带宽,占用带宽为200MHz。这是为了实现多运营商设备共享,以及减少系统排队,满足不同国家/地区的客户需求而做的考虑。”
宽带无线电应用方面业界也在考虑采用新功放技术,尤其是氮化镓功放,可将功率效率再提高5-10%。这些功放系统的预失真线性化要复杂得多,也需要大量的计算。在实施所有这些变革的同时,必须保持频谱的每MHz功率占用不变。对于现在必须支持4-5倍以上计算密度的波束成形和DFE设备来说,这是一个具有挑战性的要求。

评估计算密度的一个示例是由波束成形功能入手。假设下一代5G系统需要支持25层空间流,那么对于100MHz的单载波下行链路,每秒需要1420亿次复数乘法才能实现波束形成功能。随着占用带宽增加到200MHz,计算和内存需求也会翻一番。
Harpinder Singh Matharu指出,业界正在研究多种途径来提高信道估计精度和提高波束成型系数更新的频率。很可能一些信道估计增强和相关联的波束速率竞争将被推送到波束成形功能。这将进一步增加对波束形成器件的计算要求。
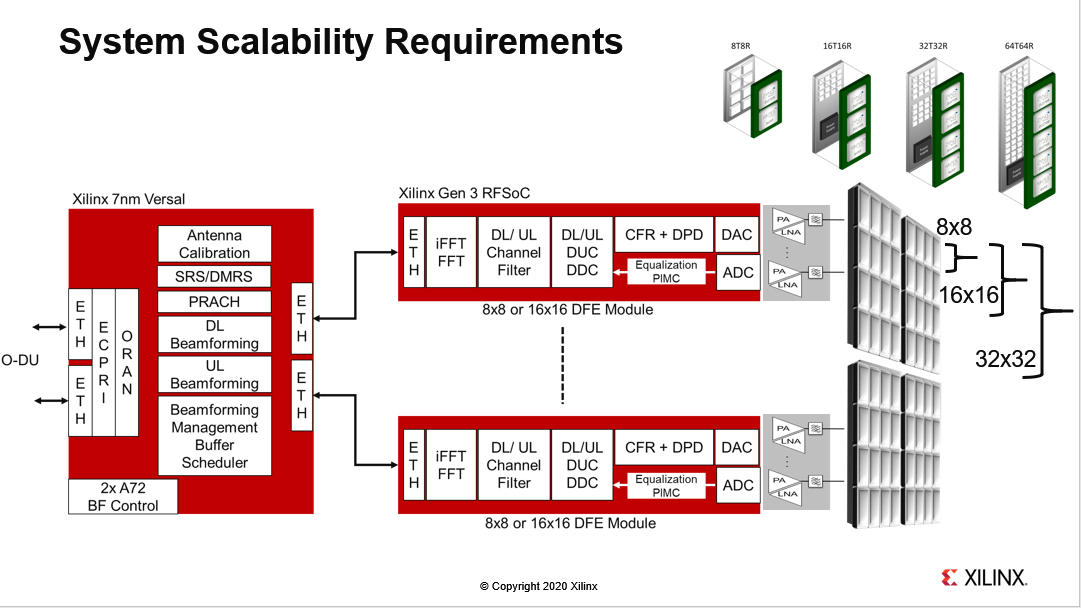
另一项目关键要求便是系统扩展性,32T32R大规模MIMO系统已经成为不同部署的首选形态。对于密集的城市地区,特别是信号覆盖高层建筑的应用,将需要64T64R大规模MIMO系统,而16T16R或传统的8T8R无线电系统或许足以满足农村地区的需求。要针对所有这些规格重复使用固件、软件和模块,以节省成本并缩短上市时间。
Versal ACAP满足下一代5G设备需求
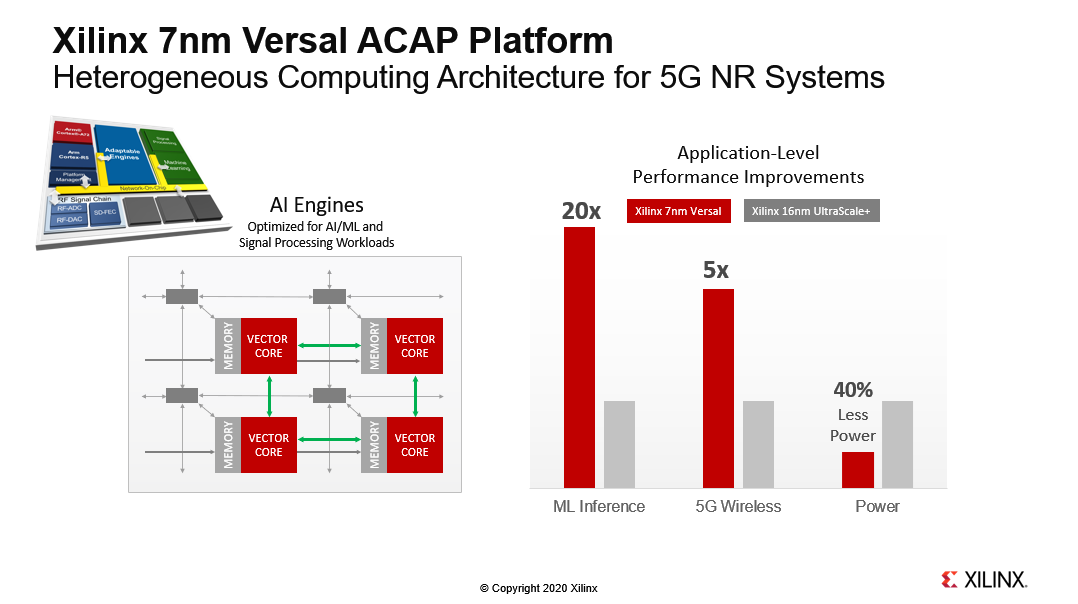
“赛灵思7nm Versal自适应计算加速平台(ACAP)是一种新型可编程SoC,旨在满足下一代5G设备的需求。”Harpinder Singh Matharu指出,赛灵思于2018年3月宣布推出ACAP平台,首款器件自6月以来一直在发货。赛灵思Versal是一种异构计算体系结构,它添加了一种称为AI Engine的自适应智能矢量引擎来执行波束形成和DFE功能。
据Harpinder Singh Matharu介绍,AI Engine也适用于机器学习应用。Versal系列器件具有数十到数百个AI矢量处理器,以满足各种用例的各种计算需求。
“Versal器件中的AI矢量处理器以1GHz+时钟频率运行,每秒可提供32GMAC。首款出货的Versal器件拥有400个AI处理器阵列,可在单个器件上实现每秒12.8TMAC的计算速度。与第一代5G基站使用的赛灵思UltraScale+器件相比,Versal将5G信号计算密度提高了5倍。同时,AI Engine支持定点和单精度浮点运算。而且与16nm的赛灵思UltraScale+器件相比,AI Engine将机器学习计算速度提高了20倍。机器学习可用于增强调度器性能。此外,每芯片面积功耗降低40%。”
赛灵思Versal平台的编程模型、软件工具和库显著提高了生产力。AI引擎本身支持C/C++编程。AI引擎用于加速计算密集型波束形成、数字前端和机器学习功能。每个AI引擎与相邻的向量引擎共享128KB的数据内存,用于处理器间通信。人工智能引擎支持高速连接结构来源和下沉数据。
此连接结构具有DMA引擎,由软件工具根据内核设计和布局约束自动编程。Harpinder Singh Matharu表示:“我们的多速率以太网MAC基本模块用于有效支持多个端口的25G前端连接,具有低于纳秒级的时频。该器件支持细粒度存储层次可编程逻辑,用于存储流式用户复数信号和波束成型参数。”
可选的DDR控制器支持将波束成形字典存储在外部存储器中。网络芯片形成在可编程逻辑、AI引擎阵列、外部存储器和芯片上的基本块中的不同功能或内核之间高效传输数据的高速通道。片上双核ARM A72处理器用于初始系统配置,系统启动后,除了实时操作系统或Linux的控制功能外,A72处理器还可用于运行时系统配置。
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。






























