
在2023年的科技界,NVIDIA的名字频频被提及。这不仅因为其在GPU市场的领先地位,也因为其在AI领域的显著成就。
NVIDIA 2023年10大研究亮点,从CV到AI,从智能体到生成式A1。
从具身AI的灵动机器人到虚拟角色的栩栩如生,从3D生成模型的立体世界到图形处理的细腻画面,再到图像生成与视频生成技术的逼真效果。NVIDIA用AI领域的十大研究成果,向世界揭示了一个全新的未来——一个由AI驱动,幻想与现实交织的未来。
实现这一切的NVIDIA,就如同创造《幻境法典》的大法师,十大研究成果便是NVIDIA以其非凡的AI魔力创造出的十大AI技术幻境。
其中包括3个AI 智能体的(机器人和虚拟角色)研究、2个3D生成模型研究、2个图形处理研究、2个图像生成研究以及1个视频生成研究。每一项技术,都是一段魔法咒语,每一次创新都是一次魔法的施展。
现在,让我们一起,深入探索这十大现实幻境,感受NVIDIA为世界揭开的每一扇神秘之门。

01 细腻之美:Neuralangelo链接虚拟与现实
从粗糙的瓦片到光滑的大理石,每一处纹理,都仿佛经过时间的雕琢,展现出细腻与真实;不论是小巧的装饰品还是宏伟的建筑,在虚拟空间中,它们的形貌和灵魂都被1:1重塑.....

这正是Neuralangelo用“AI的笔触”以前所未有的方式捕捉与重现现实世界的传神细腻,展现质感的传神。
作为一款全新的AI模型,Neuralangelo利用神经网络进行3D重建,可将 2D视频片段转换为详细的3D结构,为建筑物、雕塑以及其他真实物体生成逼真的虚拟复本。
Neuralangelo的技术核心,在于捕捉和再现那些细小而复杂的纹理与色彩变化。通过分析不同角度的视频,绘制出场景的深度、大小和形状。
Neuralangelo不仅在艺术层面颇具造诣,凭借NVIDIA Instant NeRF技术,在重建3D场景方面更能为虚拟现实、数字孪生以及机器人开发等领域开启创新篇章。
在建筑设计和房地产领域,该技术能够通过3D模型精确呈现未来建筑的内部和外部结构,帮助设计师优化设计,客户提前体验空间。
在电影和游戏产业,它能够创建高度逼真的虚拟场景,提升视觉效果,增强用户体验。
在机器人技术和自动驾驶领域,精确的3D场景重建对于机器人的空间感知和决策至关重要,有助于提高导航和操作的安全性和效率。
02 “指挥棒”:Eureka让机器人超越“天赋”
一只机器手臂,在没有任何预定义奖励模板的情况下,如何通过“直觉”,便能自如地翻转笔、打开抽屉?

这些原本仅能人类具备的“天赋”,却都在Eureka的“指挥”下被机器人完成。作为一款AI智能体,Eureka利用先进的GPT-4 LLM技术和生成式AI,为机器人提供高效的强化学习奖励方案,教会机器人通过尝试和错误来学习,训练机器人完成复杂任务。
通过在Isaac Gym中利用GPU进行加速模拟,Eureka能快速筛选出最优的奖励方案,提升训练的效率。随着训练的进行,它还会收集关键数据,指导语言模型进一步改善奖励函数。这种自我完善的能力让Eureka能教会各种类型的机器人完成多样化的任务。
Eureka这个名字源于希腊语,意思是“我找到了”。它不仅找到了解决复杂问题的新方法,更打开了行业通往无限可能的大门:
在工业领域,应用Eureka能极大提高生产效率和安全性;在医疗领域,它的精准控制可助力精细的手术操作;在娱乐行业,它所带来的物理逼真动画将为用户带来前所未有的视觉体验。此外,服务业、教育甚至家居生活,都将因Eureka的加入而变得更加智能、高效。
03 造梦师:Magic3D桥接想象力与现实
Magic3D是一个可以从文字描述中生成3D模型的AI模型。穿梭于数字与现实的交界,Magic3D以其独特“魔力”,让思维映射到现实,将简单的文字用线条与色彩编织成三维世界的奇迹。
当你输入“一只坐在睡莲上的蓝色毒镖蛙”这样的文字提示,只需40分钟,Magic3D便可以描绘出一个兼具细腻纹理和丰富色彩的三维实体。不仅如此,它的速度甚至比谷歌的DreamFusion快了整整两倍,同时还提供了更高的三维模型分辨率。

一只坐在睡莲上的蓝色毒镖蛙
更令人着迷的是,Magic3D赋予了创作者“改写现实”的能力。创作者只需通过修改文字,便可以让原本静止的模型能即时变换形态、色彩,仿佛拥有了生命。这种即时、动态的创造过程,是对传统创作方式的一次颠覆性创新。

从一只坐在一堆西兰花上的金属兔子到一个坐在一堆巧克力饼干上的狮身人面像
技术上,Magic3D采用“由粗到细”的策略,先构建初步模型,再精细化至高分辨率,保证了从宏观到微观的无缝过渡,每一个细节都经过精心打磨。
事实上,这项技术对多个行业都有潜在的巨大影响。在游戏设计中,Magic3D能够迅速构建丰富多彩的虚拟世界,提升游戏体验的同时,大幅缩短开发周期。在电影制作中,用Magic3D生成复杂的3D场景和特效,可以极大提升视觉冲击力,提高电影质量。在产品设计、建筑模拟等领域,这项技术可以作为一个高效的原型工具,加速从概念到实物的转化过程。
在这个由数字编织未来的时代,Magic3D搭建起想象力与现实之间的桥梁,引领我们进入一个更加细腻、多彩、生动的三维数字世界。
04 AI理云鬓:ADMM实现高逼真头发模拟
你知道人类头上有多少根头发吗?平均而言,这个数字大约是10万根。
一部大制作的电影,想要生动地描绘出人物头发的细节,只能租赁昂贵的服务器,通过数天甚至更长时间的计算才能呈现良好的效果,且常常需要妥协于计算资源的限制。
但现在,这一切都发生了改变,只需要数小时甚至更短,便可以制作出高逼真的发丝模拟。
这便是NVIDIA研究人员开发出的、在GPU上计算头发模拟的新方法——ADMM。ADMM使用AI来预测头发在现实世界中的行为方式,通过NVIDIA GPU强大的计算能力加持,极大地提升了头发模拟的效率和质量。每根头发的弯曲、摇摆,甚至是在风中的轻轻摆动,都能以令人惊叹的真实度呈现。
Gilles Daviet在ADMM的研究论文中指出,ADMM展示了一种高效的头发模拟技术,每帧处理时间介于0.18至8秒,根据头发的数量和长度以及碰撞处理的精度不同而变化。在双GPU设置下,内存需求也可因场景而异,从1GB到19GB不等。

从演示中,我们不难发现。创作者可以轻松调整每缕秀发的长度和曲率,仿佛在画布上缩放绘图。同时,创作者还可以精准地按照设定的轮廓线修剪,就像用剪刀裁剪精美布料。不仅如此,ADMM还支持在选定的区域内,像玩弹力球那样,用弹簧般的动力轻推头发,让每根发丝都听从指挥。
这项技术的潜力是巨大的。不论在数字娱乐产业,还是时尚设计领域,甚至在教育和培训行业,丰富和真实的用户体验、精细和生动的作品、高度逼真的模拟无疑是一个极具价值的工具。
05 超高清工坊:LDM的“高分辨率”变革
文字描绘被转化为高分辨率、生动逼真的视频,不再是遥不可及的梦想,而是潜在扩散模型LDM(Latent Diffusion Models)技术带来的现实。
传统视频生成技术往往需要庞大的计算资源,LDM技术则通过在低维潜空间中训练扩散模型,实现了高质量图像合成,并避免了过多的计算需求。
从技术实现上讲,首先,模型会生成关键帧,通过扩散模型进行插帧,保留关键帧的潜在特征作为界限,中间帧以噪声初始化。经解码器和超分模块处理后,生成高质量视频。
而后,采用基于掩码的条件方法,用给定上下文帧的潜在特征预测遮盖帧,迭代生成长视频。
最终,视频的生成效果达到了惊人的1280x2048像素、113帧、24fps播放、4.7秒时长。该LDM基于稳定扩散,拥有4.1B参数,其中27亿通过视频训练,包含剪辑文本编码器外的所有组件。
这就像是在一个简化但精华的世界里,进行创作,然后再将这些创作放大,呈现在现实世界中。

进行时态视频微调的示意
这项技术的应用前景同样令人振奋。在未来的交通系统中,LDM可以用于模拟和预测复杂的驾驶场景,为自动驾驶汽车提供决策支持。
06 梦幻纹理:Text2Materials“创想”细腻材质
无论是复古的红砖墙面,还是光滑整洁的家具面料,“设计师”Text2Material都可以轻松搞定。它不仅可以针对织物、木材、石材等材质的纹理创作,还在建筑、游戏开发、室内设计等领域应用。
这场美学革命,由一种全新的生成式AI工作流所驱动——Text2Material可以利用文本或图像提示来更快地生成织物、木材和石材等自定义纹理材质,同时对创作进行更加精细的把控。
这套 AI模型将促进材质创建和编辑的迭代,能够帮助使用者快速完善 3D 对象的外观,直到达到想要的效果。
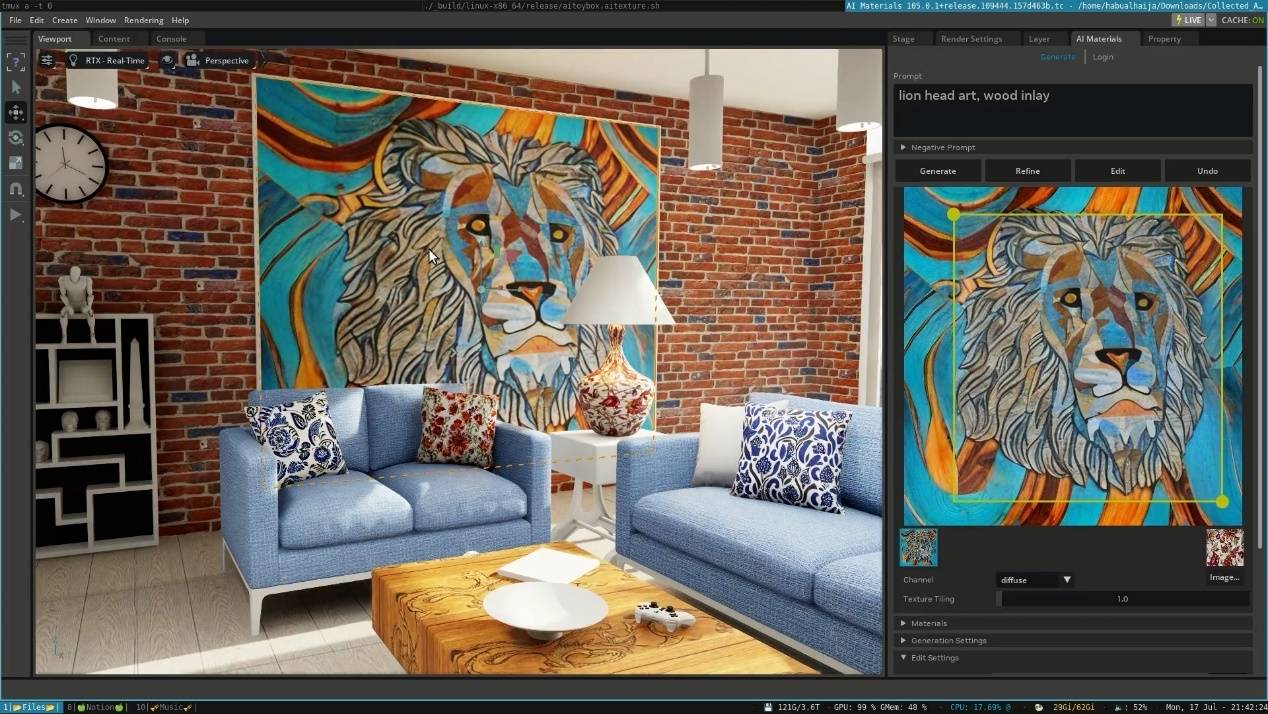
从演示视频可以看出,创作者只需简单的提示,AI便能根据提示迅速生成一面砖纹理的墙,或是一套具有特定面料的沙发和抱枕。甚至能在墙壁的特定区域嵌入抽象的动物图案,将创意无缝转化为现实。
目前,这些功能可以通过NVIDIA Picasso基础模型平台提供服务。企业开发者、软件制作人员和服务供应商能够通过该平台选用、细化、完善并应用图像、视频、3D对象以及360度全景HDRi的基本模型,以此来满足他们在视觉设计方面的各项需求。
07 极限模拟:CALM让人类“穿越”数字世界
无论是攀爬、跳跃还是短暂的回望,游戏玩家在现实世界的每个轻微动作,都能被完美捕捉,并在虚拟角色上呈现。这让整个游戏体验,变得更加沉浸和真实。
给予玩家前所未有的动作自由度的,便是这款可操纵虚拟角色的条件对抗性潜在模型——CALM。
CALM能赋予用户操纵交互式虚拟角色的能力,同时生成既多样又定向的行为。
这项技术依赖于模仿学习,能够精确捕捉并控制角色的每一个动作。通过结合控制策略和运动编码器的学习,CALM不仅能实现人类行为的简单复制,更是能深入理解并重现该行为的核心特征。
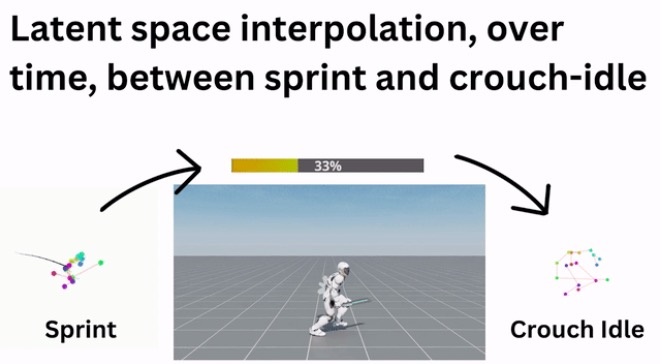
CALM 由三个阶段组成学习有意义的运动语义表征
CALM想要毫无瑕疵地模拟人类行为,需要经历3个阶段。
在低级训练阶段,CALM技术可通过模仿学习,精妙地捕捉并再现人类运动的复杂多样性。在这一过程中,它还能通过编码器和解码器深度理解动作的本质,并将其转化为数字世界的语言。
第二阶段增加了方向性控制。CALM可利用高级任务驱动策略来选择潜在变量,可根据用户的意愿,调整运动的风格和节奏,赋予动作不同的情感色彩。
而在最终的推理阶段,CALM则可以将前期的学习和训练巧妙地结合,让复杂的动作组合变得轻而易举。用户仅通过一个直观的界面,便可以让虚拟角色表演出一连串的动作剧情。
08 训练大师:Vid2Player3D在虚拟赛场的技术革命
如果网球比赛中的每个精彩瞬间都能被精确地捕捉、分析,并在虚拟世界中重现,这将是怎样一番景象?Vid2Player3D是这样一位“训练大师”,它可以将网球比赛的瞬间变为永恒,把球星的技巧转化为永久的数字资产。

这项技术的核心在于它能够洞察2D比赛视频中的每一个细节,并将这些数据转化为3D模型的动作。这不仅仅是简单的模仿,而是一种深度学习和精确再现。
Vid2Player3D就像是一个细心的观察者,它分析球员的每一个动作,甚至是呼吸的节奏,然后指导虚拟球员在网球场上做出最佳反应。
Vid2Player3D的工作原理可以分为四步。
首先,收集网球运动员的2D和3D姿势数据,以及他们在场上的移动路径,建立起一个基础的运动信息库。
然后,利用这些数据训练一个基础的模仿程序,模拟真人的动作,同时也对这些动作进行一些物理上的调整,使动作更加真实。
接着,对修正后的运动数据集进行条件变分自编码器(VAE)的拟合,这个过程可以帮助Vid2Player3D理解和学习网球运动的核心动作模式,并将这些复杂的动作简化成更容易处理的形式。
最终,训练出一个高级的规划程序,可以根据学到的动作模式来生成更自然、更符合预期的网球运动姿势,同时也会对运动员手腕的动作做出细微的调整,以确保动作的准确性。这样,整个系统就能生成接近真人的网球运动姿势。
为了解决从广播视频中提取的低质量运动,研究人员通过基于物理的模仿来校正估计的运动,并使用混合控制策略,通过高级策略预测的校正来覆盖学习运动嵌入的错误。
同时,系统还能合成两个物理模拟角色,通过模拟球拍和球的动力学进行长时间的网球比赛。
09 魔幻维度:FlexiCubes给出网格优化“最优解”
FlexiCubes的核心革新在于其梯度网格优化方法。通过将3D表面网格表现为标量场的等值面,FlexiCubes实现了网格的精确迭代优化。
这一技术在摄影测量、生成建模和逆向物理等领域中的应用越发广泛,它为这些复杂的应用提供了一个更加精细和准确的三维表达方式。
与传统的等值面提取算法相比,FlexiCubes引入了额外的参数,使得网格不仅拥有更高的自由度来表示复杂的特征,而且在优化的过程中也能保持数值的稳定性。这意味着无论是在优化几何形状、视觉效果,还是物理属性时,FlexiCubes都能提供更为精准和灵活的网格调整。

FlexiCubes的灵活性和精确性得益于其基于双行进立方体的提取方案,这一方案不仅改善了网格的拓扑属性,还能生成四面体和分层自适应网格。这种方法使得网格的微分明确且易于操作,使基于梯度的优化方法能够有效且稳定地收敛,为各种应用实现了简单、高效和高质量的网格优化。
在实际应用中,FlexiCubes展现出了巨大的潜力。无论是与可微分等值曲面技术结合,改善几何重建的质量;还是作为3D生成模型的一部分,提升网格质量;或是在可微分物理模拟框架中,协助从视频中恢复3D形状和物理参数;FlexiCubes都能提供卓越的性能。
此外,FlexiCubes在动画对象网格简化和正则化方面的应用也证明了其不同凡响的能力。它不仅能够优化动画的每一帧,确保动作的流畅性,还能直接评估和优化依赖于提取网格本身的目标和正则化器。
10 创造力“外挂”:eDiff-I用文字编织视觉奇迹
如果想象力成为一种新的生产力,想要一瞥未来吗?
eDiff-I便拥有绝妙的技巧,让你的每个念头都跃然纸上。这可不是什么简单的把戏。eDiff-I是一种扩散模型,可通过T5文本嵌入、CLIP图像嵌入和CLIP文本嵌入为条件,生成与任何输入文本提示相对应的逼真图像。
简单地说,就是可以将你的文本描述转换成令人惊叹的图像。
不仅如此,除了文本到图像的合成之外,“样式传输”更能支持我们能够利用参考样式图像控制生成样本的样式。“文字绘画”功能,则能通过在画布上绘制分割图来生成图像的应用程序。
现在,让我们把技术术语抛在脑后,试想一下:你描述一片森林,eDiff-I就能给你绘制出一片森林;你想要一只穿着礼帽的猫,eDiff-I也能做到。你甚至可以提供一张图片,让eDiff-I模仿其风格,绘制出全新的图像。更神奇的是,它可以根据你在一个虚拟画布上的涂鸦来绘制图像,这对于创造力的发挥来说简直是开了挂!
想想看,广告界能用它来制作令人难以忘怀的视觉效果,游戏设计师可以用它来构建出前所未有的场景,而时尚界也可以利用它来预视下一季的趋势。
eDiff-I的特性不仅仅是新颖,更重要的是实用——创造力的实际应用从未如此便捷。
所以,如果想要看看你的想象力能走多远,eDiff-I就是你的新伙伴。

免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。






























