
在智慧交通的整体体系中,车牌识别无疑是基础性的应用之一。车牌识别应用要求将静止或运动中的汽车牌照从复杂背景中提取并识别出来,通过车牌提取、图像预处理、特征提取、车牌字符识别等技术,识别车辆牌号、颜色等信息。车牌识别是自动化交通控制的基础应用,其识别成功率以及准确率会对交通运行效率、收费、违规行为处罚等带来较大影响。
北京智芯原动科技有限公司*(以下简称:智芯原动)是中国领先的人工智能及解决方案提供商,专业从事人工智能算法和算法芯片的技术研发,智能化产品、解决方案的开发交付,以及智能云服务的集成,致力于加快人工智能技术在各个行业中的应用,以提升用户体验和工作效率。为了满足车牌识别的要求,智芯原动推出了深云识车* 平台,该平台可准确识别各类车牌。此外,智芯原动还推出了海外车牌识别解决方案,能够在少量(>1K)车牌样本条件下快速迭代,仅需2-4周的交付周期即可实现新国家车牌的开发任务,且综合准确率可高达90%-95%。
为了进一步提升车牌识别平台的推理性能,加速面向海外车牌场景的算法训练速度,智芯原动搭载了第二代英特尔® 至强® 可扩展处理器与英特尔® OpenVINO™的组合解决方案,并使用了针对英特尔® 架构进行优化的 Caffe* 应用,实现了数十倍的性能提升。
挑战:海外市场给车牌识别带来严峻考验
在互联网停车领域,智芯原动除了出入口车牌识别外,还陆续推出了路边停车、停车场内车位相机,同时智芯原动也开始进入海外停车市场,已经在香港、台湾、澳门、马来西亚、印尼、泰国、新加坡、越南等多地开始部署,预计未来3年车牌识别相机部署量接近百万台。在海外车牌识别市场,一个重要的特征是每个国家或地区在车牌的长宽度、颜色和字符组成上都有着一定的差异,同样的一套算法无法适用于每个国家与地区。
要对每个国家与地区的车牌识别算法进行针对性训练,无疑需要本地化的数据作为支撑。如果通过传统的车牌算法,将需要海量的车牌样本,同时需要长达数月的交付周期,才能将车牌识别的准确率提升到可用的水平。而这一速度,显然无法满足快速的市场竞争需求,智芯原动希望能够基于少量的车牌样本完成快速的产品部署,这要求其对于算法进行不断创新,同时也要部署更高效的基础设施平台与深度学习加速工具。
此外,车牌识别系统本身也对于深度学习性能带来要求。根据智芯原动的工程师测算,目前单核处理器做一次车款识别需要40ms,按照停车高峰期每10秒一辆车计算,深云识车服务总共需要1000个4核处理器。一旦再提供公安警用服务的话,压力更会成倍增加,因此需要实现更高效的深度学习计算能力。
智芯原动面向海外市场的领先算法平台
面向海外市场的车牌识别需求,智芯原动推出了海外车牌识别解决方案,在技术上,海外车牌算法的实现是通过车牌提取、字符分割和字符识别三个步骤来搭配完成,即从背景复杂的含有车牌的图像中提取出车牌图像,然后对提取图像进行必要的预处理、分离出单个字符,接着提取字符的特征并与标准字符进行比对,输出待识别车牌的车牌号码。智芯原动针对不同的车牌类型会采用不同的车牌定位和字符分割算法,以确保识别的准确率。
方案最大的亮点即基于自研车牌算法框架,能够在少量(>1K)车牌样本条件下快速迭代,仅需2-4周的交付周期即可实现新国家车牌的开发任务,且综合准确率可高达90%-95%。目前,该方案已经在全球二十几个国家和地区实现了规模化商用。此外,方案还具备以下特点:
● 支持二十多个国家与区域的车牌识别
● 适用卡口、出入口、停车位等场景
● 算法框架采用灵活模型匹配策略和模块化设计,在少量样本下能够实现新国家车牌的开发和实现
● 算法支持跨平台设计,满足前端相机、后端服务器不同方案需求
● 中国团队原厂研发支持,问题迭代高效,项目需求响应及时
在该方案中,智芯原动使用了基于卷积神经网络深度学习的车款识别方法,并通过MobileNet*、GoogleNet* 等拓扑结构来实现分类推理优化。在智芯原动对车牌识别算法进行优化之后,有助于在小样本的前提下实现应用的快速开发及部署。
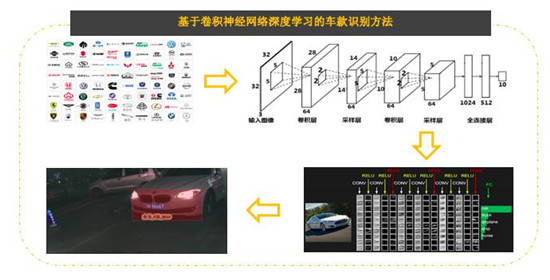
解决方案:基于英特尔® 架构加速推理性能
在基础设施架构方面,智芯原动面向不同国家及地区的实际应用环境,推出了不同的参考方案,车牌识别的工作负载可以灵活的由云数据中心,或是边缘设备来承载,可以满足用户对于延迟、部署成本、网络等方面的不同要求。
在服务器端,智芯原动搭载了第二代英特尔® 至强® 可扩展处理器与英特尔® OpenVINO™的组合解决方案。第二代英特尔® 至强® 可扩展处理器采用矢量神经网络指令 (VNNI) 的全新英特尔® 深度学习加速功能,提高了人工智能推理的表现,与上一代产品相比,性能有了显著提升,第二代英特尔® 至强® 可扩展处理器有助于在整个数据中心到边缘之间实现充分的 AI 支持。
相较于智芯原动之前所使用的第一代英特尔® 至强® 可扩展处理器,第二代英特尔® 至强® 可扩展处理器进一步提升了性能表现,特别是其支持的 VNNI 等技术提高了将推理性能提升到新的层次。在具体的应用实例中,性能的提升将允许用户部署更少的节点,同时支撑更多的推理负载,实现更低的总体拥有成本 (TCO)。
英特尔® OpenVINO™ 工具套件分发版则支持开发人员使用行业标准人工智能框架、标准或自定义层,将深度学习推理轻松集成到应用中。通过在底层的英特尔® 至强® 可扩展处理器上运行,英特尔® OpenVINO™ 工具套件分发版可实现具有竞争力的推理速度和极低的精度损失。同时,借助 AVX-512 和 MKL/MKL-DNN boost 库的支持,这一解决方案还可实现卓越的计算性能。
效果:实现接近30倍的性能提升
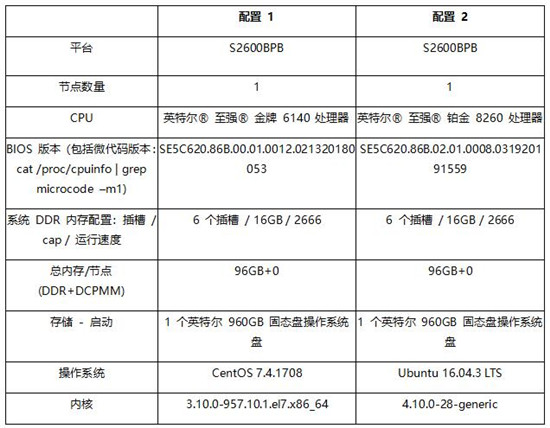
为了验证第二代英特尔® 至强® 可扩展处理器与英特尔® OpenVINO™ 在不同拓扑结构中的推理性能,智芯原动搭建了测试平台,测试平台的配置如表1所示2:
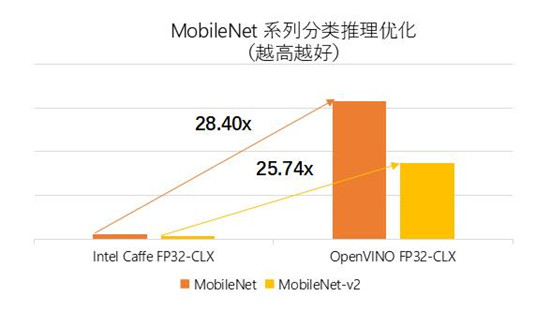
在视频图像分析推理性能的测试中,测试人员分别测试了在MobileNet、MobileNet-V2、GoogleNet、VGG-16等多个拓扑结构中,使用公共版Caffe*、英特尔优化版本Caffe,以及OpenVINO™ 的推理性能。测试数据如图1所示,与英特尔优化版本 Caffe 相比,使用OpenVINO™ 在 MobileNet 中实现了28.4倍的性能提升1。
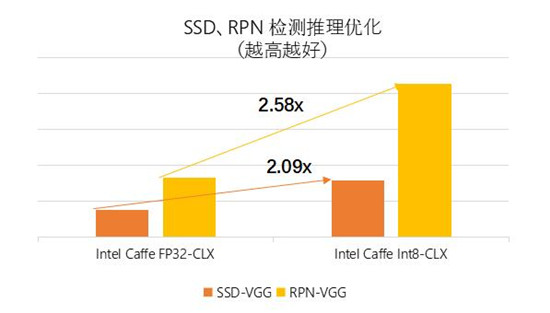
同时,在SSD、RPN 检测推理优化的测试中(测试数据如图2所示),相比带有 FP32 的英特尔优化 Caffe,带有 SSD-VGG、RPN-VGG 拓扑结构且使用 Int8 量化的英特尔优化 Caffe 可分别实现 2.58 倍和 2.09 倍的性能提升。
未来:为车辆识别应用负载提供灵活、高效的算力支持
除了车牌识别之外,基于人工智能与深度学习技术的检测推理还广泛应用于车辆识别的其它场景之中,并用于检测车辆型号、颜色、大小、位置等用途。这些应用负载在依赖先进算法的同时,也对于平台的算力提出了一定的要求。智芯原动的云端车款识别平台可识别1600种左右车款,车款信息包括:品牌、型号、年代,识别准确率超过99%,该平台同时也可应用于警用安防系统、高速公路收费等领域的车款识别。
通过与英特尔进行合作,智芯原动能够为车辆识别深度学习应用提供更加灵活的基础设施平台,如在数据中心通过CPU、GPU、FPGA的组合实现深度学习异构计算,或是在边缘端部署统一的边缘计算服务器,承载车辆、车牌的识别负载,满足用户对于检测精度、速度等方面的需求,助力智慧交通的实现。
1. 基于英特尔和智芯原动内部测试结果
2. 测试配置:平台 1 – 英特尔® 至强® 金牌 6140处理器;BIOS 版本(包括微代码版本:cat /proc/cpuinfo | grep microcode –m1):SE5C620.86B.00.01.0012.021320180053,总内存96 GB(6 个插槽/16 GB/2666MHz);1 个英特尔 960GB 固态盘操作系统盘;CentOS 7.4.1708,3.10.0-957.10.1.el7.x86_64;平台 2 -英特尔® 至强® 铂金 8260处理器;BIOS 版本(包括微代码版本:cat /proc/cpuinfo | grep microcode –m1):SE5C620.86B.02.01.0008.031920191559,总内存96 GB(6 个插槽/16 GB/2666MHz);1 个英特尔 960GB 固态盘操作系统盘;Ubuntu 16.04.3 LTS,4.10.0-28-generic
- 智驾领域智界就是第一?问界排第几?
- ChatGPT推出图片管理功能:AI创作更高效!
- 抵御关税冲击,美国PC市场2025年Q1逆袭:出货量激增12.6%,库存量将大增
- 全球电车风潮涌动:中国与欧洲领跑,同比增长29%的电动汽车销量新篇章
- AI编程大势所趋:半年内90%,一年内几乎全部代码由AI编写
- iPhone 17系列机模意外曝光,小米SU7 Pro交付时间吓坏用户
- 福耀科技大学获批,曹德旺回应:压力山大,批下来就要做好,求真务实才是关键
- 特斯拉Cybertruck新功能:FSD大更新,轻松实现停车启动、智能召唤与倒车,驾驶更智能!
- 大众汽车裁员风暴来袭:软件部门Cariad大刀挥向三成岗位,风雨飘摇中的裁员序幕?
- 保时捷扛不住压力裁员3900人:全球跑车销量王也难逃经济寒冬?
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























