
YOLO作为目标检测领域的创新技术,一经推出就受到开发者的广泛关注。值得一提的是,基于百度自研的开源深度学习平台PaddlePaddle的YOLO v3实现,参考了论文【Bag of Tricks for Image Classification with Convolutional Neural Networks】,增加了mixup,label_smooth等处理,精度(mAP(0.5:0.95))相比于原作者的实现提高了4.7个绝对百分点,在此基础上加入synchronize batch normalization, 最终精度相比原作者提高5.9个绝对百分点。我们将在下文中为大家详解实现的具体过程。
CV领域的核心问题之一就是目标检测(object detection),它的任务是找出图像当中所有感兴趣的目标(物体),确定其位置和大小(包含目标的矩形框)并识别出具体是哪个对象。Faster R-CNN及在其基础上改进的Mask R-CNN在实例分割、目标检测、人体关键点检测等任务上都取得了很好的效果,但通常较慢。YOLO 创造性的提出one-stage,就是目标定位和目标识别在一个步骤中完成。
由于整个检测流水线是单个网络,因此可以直接在检测性能上进行端到端优化,使得基础YOLO模型能以每秒45帧的速度实时处理图像,较小网络的Fast YOLO每秒处理图像可达到惊人的155帧。YOLO有让人惊艳的速度,同时也有让人止步的缺陷:不擅长小目标检测。而YOLO v3保持了YOLO的速度优势,提升了模型精度,尤其加强了小目标、重叠遮挡目标的识别,补齐了YOLO的短板,是目前速度和精度均衡的目标检测网络。
YOLO v3检测原理
YOLO v3 是一阶段End2End的目标检测器。YOLO v3将输入图像分成S*S个格子,每个格子预测B个bounding box,每个bounding box预测内容包括: Location(x, y, w, h)、Confidence Score和C个类别的概率,因此YOLO v3输出层的channel数为S*S*B*(5 + C)。YOLO v3的loss函数也有三部分组成:Location误差,Confidence误差和分类误差。
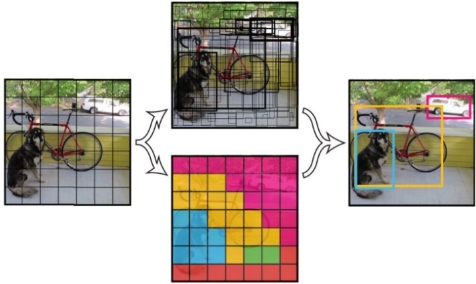
图:YOLO v3检测原理
YOLO v3网络结构
YOLO v3 的网络结构由基础特征提取网络、multi-scale特征融合层和输出层组成。
1、特征提取网络。YOLO v3使用 DarkNet53作为特征提取网络:DarkNet53 基本采用了全卷积网络,用步长为2的卷积操作替代了池化层,同时添加了 Residual 单元,避免在网络层数过深时发生梯度弥散。
2、特征融合层。为了解决之前YOLO版本对小目标不敏感的问题,YOLO v3采用了3个不同尺度的特征图来进行目标检测,分别为13*13,26*26,52*52,用来检测大、中、小三种目标。特征融合层选取 DarkNet 产出的三种尺度特征图作为输入,借鉴了FPN(feature pyramid networks)的思想,通过一系列的卷积层和上采样对各尺度的特征图进行融合。
3、输出层。同样使用了全卷积结构,其中最后一个卷积层的卷积核个数是255:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示Confidence Score,80表示COCO数据集中80个类别的概率。
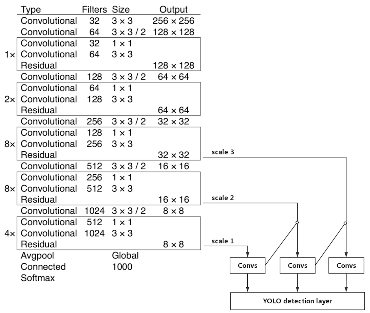
图:YOLO v3 网络结构
PaddlePaddle简介
PaddlePaddle是百度自研的集深度学习框架、工具组件和服务平台为一体的技术领先、功能完备的开源深度学习平台,有全面的官方支持的工业级应用模型,涵盖自然语言处理、计算机视觉、推荐引擎等多个领域,并开放多个领先的预训练中文模型。目前,已经被中国企业广泛使用,并拥有活跃的开发者社区。
应用案例—AI识虫
红脂大小蠹是危害超过 35 种松科植物的蛀干害虫,自 1998 年首次发现到 2004 年,发生面积超过 52.7 万平方公里 , 枯死松树达 600 多万株。且在持续扩散,给我国林业经济带来巨大损失。传统监测方式依赖具有专业识别能力的工作人员进行实地检查,专业要求高,工作周期长。北京林业大学、百度、嘉楠、软通智慧合作面向信息素诱捕器的智能虫情监测系统,通过PaddlePaddle训练得到目标检测模型YOLO v3,识别红脂大小蠹虫,远程监测病虫害情况,识别准确率达到90%,与专业人士水平相当,并将原本需要两周才能完成的检查任务,缩短至1小时就能完成。
基于PaddlePaddle实战
运行样例代码需要Paddle Fluid的v.1.4或以上的版本。如果你的运行环境中的PaddlePaddle低于此版本,请根据安装文档中的说明来更新PaddlePaddle。
数据准备
在MS-COCO数据集上进行训练,通过如下方式下载数据集。
cd dataset/coco
./download.sh
数据目录结构如下:
dataset/coco/
├── annotations
│ ├── instances_train2014.json
│ ├── instances_train2017.json
│ ├── instances_val2014.json
│ ├── instances_val2017.json
| ...
├── train2017
│ ├── 000000000009.jpg
│ ├── 000000580008.jpg
| ...
├── val2017
│ ├── 000000000139.jpg
│ ├── 000000000285.jpg
| ...
模型训练
安装cocoapi:训练前需要首先下载cocoapi。
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
# if cython is not installed
pip install Cython
# Install into global site-packages
make install
# Alternatively, if you do not have permissions or prefer
# not to install the COCO API into global site-packages
python2 setup.py install --user
下载预训练模型: 本示例提供darknet53预训练模型,该模型转换自作者提供的darknet53在ImageNet上预训练的权重,采用如下命令下载预训练模型。
sh ./weights/download.sh
通过初始化 --pretrain 加载预训练模型。同时在参数微调时也采用该设置加载已训练模型。 请在训练前确认预训练模型下载与加载正确,否则训练过程中损失可能会出现NAN。
开始训练: 数据准备完毕后,可以通过如下的方式启动训练。
python train.py \
--model_save_dir=output/ \
--pretrain=${path_to_pretrain_model}
--data_dir=${path_to_data}
• 通过设置export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7指定8卡GPU训练。
• 可选参数见: python train.py --help
数据读取器说明:
• 数据读取器定义在reader.py中。
模型设置:
• 模型使用了基于COCO数据集生成的9个先验框:10x13,16x30,33x23,30x61,62x45,59x119,116x90,156x198,373x326
• 检测过程中,nms_topk=400, nms_posk=100,nms_thresh=0.45
训练策略:
• 采用momentum优化算法训练YOLO v3,momentum=0.9。
• 学习率采用warmup算法,前4000轮学习率从0.0线性增加至0.001。在400000,450000轮时使用0.1,0.01乘子进行学习率衰减,最大训练500000轮。
下图为模型训练结果Train Loss。
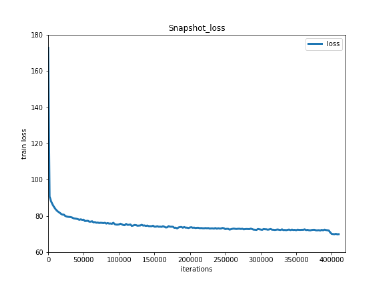
图:Train Loss
模型评估
模型评估是指对训练完毕的模型评估各类性能指标。本示例采用COCO官方评估。
eval.py是评估模块的主要执行程序,调用示例如下:
python eval.py \
--dataset=coco2017 \
--weights=${path_to_weights} \
• 通过设置export CUDA_VISIBLE_DEVICES=0指定单卡GPU评估。
若训练时指定--syncbn=False, 模型评估精度如下。
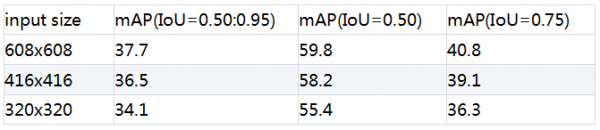
若训练时指定--syncbn=True, 模型评估精度如下。

• 注意: 评估结果基于pycocotools评估器,没有滤除score < 0.05的预测框,其他框架有此滤除操作会导致精度下降。
模型推断
模型推断可以获取图像中的物体及其对应的类别,infer.py是主要执行程序,调用示例如下。
python infer.py \
--dataset=coco2017 \
--weights=${path_to_weights} \
--image_path=data/COCO17/val2017/ \
--image_name=000000000139.jpg \
--draw_thresh=0.5
• 通过设置export CUDA_VISIBLE_DEVICES=0指定单卡GPU预测。
模型预测速度(Tesla P40)
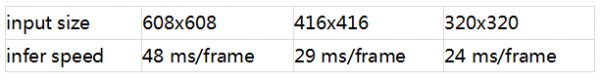

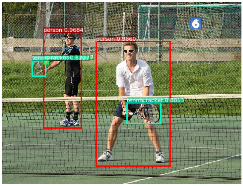
图:YOLO v3 预测可视化
- 亚马逊欲借首批27颗卫星挑战SpaceX:能否成功突围引关注
- 苹果图书涉嫌虚假宣传遭集体诉讼,消费者权益受损引争议
- 鸿蒙版微信更新:华为HarmonyOS发展步入“新纪元”,多项重磅功能助力用户畅享沟通新体验
- 亚马逊竞购TikTok美国业务,用户命运悬疑4月5日揭晓,真相还是迷雾?
- 英伟达黑科技液冷散热,揭秘未来显卡散热新纪元
- 美团骑手养老保障新举措:试点补贴,逐步全国覆盖,让骑手更安心!
- 半导体设备国产化新曙光:新凯来“软硬协同”模式引领行业变革
- 数字化艺术创新:网龙“数字化细节重构”艺术形式引领美育教育新范式
- 比亚迪“西安号”滚装船正式下水,“深圳号”即将首航,出海再提速,新机遇新挑战
- 腾讯字节跳动移动发行商收入榜稳坐前二,竞争激烈,谁将领跑全球手游市场?
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























