
看点:开发小白和高阶程序媛都爱用,这份华为云一站式AI开发平台指南,你查收了吗?

2019年,热门的人工智能(AI)继续在产业中快速奔跑,越来越多的行业开始搭上智能化升级的大潮。然而,长时间、高成本、高投入、复杂繁琐的AI开发流程,正阻碍着AI产业的规模化发展,许多传统企业不能轻松快速地构建AI能力。
喝一杯水要几步? 对于普通人来说,这是一件毫不费脑的事。那么AI开发需要几步呢?对于开发小白和AI专业开发者来说,答案截然不同。
1月底,华为云EI(企业智能)一站式AI开发平台ModelArts正式商用上线,不仅让许多AI小白拆除AI开发的门槛,同时也让诸多AI开发者享受到更为高效便捷的开发体验。
这一被称为“开发者的福音”的AI平台,究竟是怎样的利器?它又在如何在各个传统行业发挥作用呢?对此,智东西分析了ModelArts加速AI开发的四大亮点,详解ModelArts平台使用步骤,并亲身体验了ModelArts的极简操作流程,过了一把AI开发瘾。
一、ModelArts四大亮点,加速AI开发流程
简单的说,ModelArts平台就是一个让小白轻松学会训练AI模型、让AI老手节省时间脑力的开发神器,让各行各业关于AI的创意都能快速实现。
这里,我们先从四大亮点分析ModelArts如何帮助有经验的开发者加快AI模型开发和部署,然后复原小白轻松上手AI开发的全过程。
1、提供开源数据集,部分场景实现数据自动标注
对于饱受数据标注困扰的开发者而言,ModelArts是可以简化数据标注流程的优质平台。
ModelArts通过对数据进行采样、筛选、预标注,可以将大部分数据进行自动标注和筛选,而人工只需在自动数据标注后做筛选确认,这将极大地降低开发者的工作量。
目前,ModelArts机器数据标注已广泛应用于“自动驾驶学习”场景,后续ModelArts还将持续更新,以服务更多新兴业务场景。
ModelArts还有一个亮点功能——市场。“市场”是一个共享平台,为开发者提供多种开源数据集和一些预置模型,开发者也可以上传自己的数据集合模型。后续可能还会有交易模式,让一些AI开发者在提供AI模型后,可以实现知识价值变现。
2、自动学习+自动训练模型并调参,简化工作量
对于算法工程师来说,在训练中会有很多调参,由于不同的调参会影响最后模型的收敛速度及精度,这一部分通常会给算法工程师制造大量的工作量。
ModelArts提供自动化调参服务,采用momentum、batch size等动态超参策略,将模型收敛所需 epoch个数降到最低,不仅可以简化算法工程师调参的工作量,还能帮助算法工程师找到尽可能最优的参数,在满足精度的前提下让模型快速收敛。
3、大规模分布式训练,加快训练速度
ModelArts平台的高效不止体现在简化步骤和数据标注上。它是一个端到端从硬件到软件协同的平台,华为在其中做了很多深层次的优化和高性能调优,包括对分布式调度、网络通信和硬件特性等做整体优化,以提供加速训练的能力。
在深度学习模型训练过程中,华为云将分布式加速层抽象出来,自研了一套分布式通用加速框架MoXing,在TensorFlow、MXNet、PyTorch、Keras等框架上实现再优化,使得这些计算引擎分布式性能更高,训练时间更短。
开发者可以通过几个接口直接调用MoXing框架,将本地单机的业务变成分布式业务,仅用一串代码就实现单机和分布式部署。开发者无需关心下层分布式相关API,只需聚焦在业务模型中,根据实际需求输入数据、模型和相应优化器。
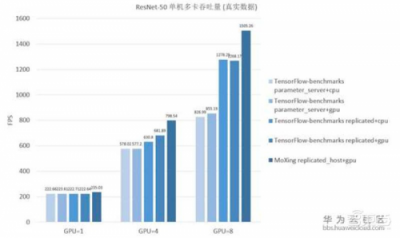
ModelArts在衡量分布式深度学习框架加速性能主要考虑的吞吐量、收敛时间等关键指标上都做了精心处理。通过提供MoXing分布式框架和千级GPU集群规模训练加速,ModelArts可为用户带来极高性能的AI开发体验。
4、模型一键式部署,适配到端边云
通常情况下,模型部署非常复杂,需要写代码集成到应用系统,维护和更新。ModelArts可以一键将模型部署到云、端、边缘的设备上,根据端边云不同的特点,帮助开发者做模型压缩和模型加速。该平台还支持在线和批量推理,满足多种场景需求。
根据开发者制定的策略,ModelArts平台可以自动调整云服务器的计算资源,在业务需求下降时将减少云服务器,高效节省资源和成本;在业务需求增多时增加云服务器,保证业务平稳健康运行。
二、ModelArts用法拆解之开发小白篇——五个步骤让小白玩转AI
在ModelArts超高配置的加持下,即便是不具备任何AI开发算法能力的小白,也可以零负担地来构建AI模型。这就要提到ModelArts非常强大的功能——自动学习。
如果你是AI小白,或者是不想在模型训练上花费时间和精力的开发者,在ModelArts上,只需掌握如下五个步骤,就能完成整个算法从开发到最后部署上线的全过程。
目前华为云ModelArts提供物体检测、图像分类、预测分析和声音分类四类开发项目,为了将用户使用门槛降到最低,华为云EI企业智能不仅提供内容详细的新手入门和用户指南,还为前三类项目分别录制了视频教程。
这里,智东西记者以图像分类项目为例,在不写一行代码的情况下,训练出一个AI模型。
1、准备数据
我们准备了10张向日葵和10张玫瑰的照片作为训练模型的数据集。不过,如果开发者只是想简单练习如何做AI开发,可以直接在市场中下载预置数据集,导入至自己的数据集中。
2、创建项目
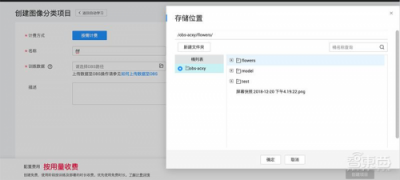
在准备好数据后,开发者可点击左侧导航栏的“自动学习”,创建一个“图像分类”项目,创建时会有弹窗让开发者选择训练数据集存放位置,这需要开发者预先创建一个华为云OBS桶。
3、数据标注
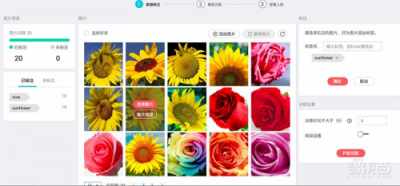
项目创建完毕后就进入数据标注页面,点击添加图片一次性上传全部照片。随后,点击每张图片进行标注,每张图片至少有两个标注分类,用于训练的图片至少有5张。当然,如果想让模型获得更高的精度,训练图片的数量自然是多多益善。
4、模型训练
接下来就可以开始训练模型了,点击“开始训练”,然后等待约一分钟,模型就训练成功了。
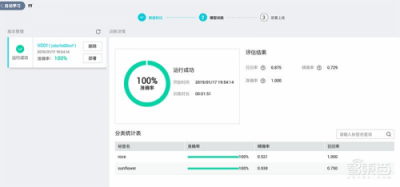
更喜欢DIY的用户,还可以在创建训练作业时,自己设定更想要的参数。
5、部署上线
训练完模型的最后一步是模型部署。部署上线后,用户就可以随时用模型来测试某一张图片中的花卉了。
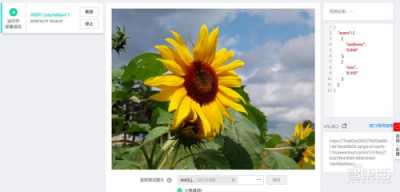
当然,智东西只是拿20张图片简单地练手,如果想要更精确的模型,用户需要用大量的数据集来训练。
三、ModelArts用法拆解之高阶程序媛篇——用ModelArts玩比赛
说完了小白,再来说一下专业人群。
如果你具备一定的AI开发基础和编程能力,已经迫不及待地想用ModelArts练练手了,不妨关注一下正在进行中的2019数字中国创新大赛。华为云作为大赛出题方之一,提出了“文化传承——汉字书法多场景识别”的赛题,而ModelArts正是华为云附送给参赛者们的开发神器。
日前,智东西就收到一位程序媛投稿,详细讲述了她如何用ModelArts玩比赛。
赛题模型按笔者理解可以由两个部分组成,一个是文字检测,一个是文字识别。
在文字框检测上,可使用EAST模型;在文字识别OCR模型上,可使用西安交通大学人工智能实践大赛第一名的方案模型。
本文代码均已开源在代码库GitHub中,可直接下载使用。
1、EAST文字检测模型
使用ModelArts训练EAST模型
第一步是数据准备工作,首先下载并解压比赛数据包。
将处理过的数据上传到在OBS上创建的路径,如:
同样,下载EAST训练代码,并将代码上传到OBS。
然后就可以创建作业了,选择训练作业中的“创建”。
之后选择数据存储路径、使用的引擎、启动文件等,
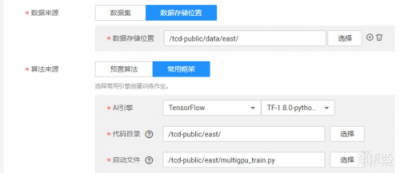
再输入使用脚本需要的相应参数,
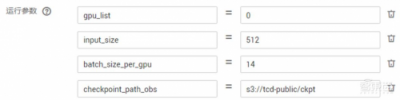
选择计算资源,并保存作业参数以便下次使用,就可以开始运行了。
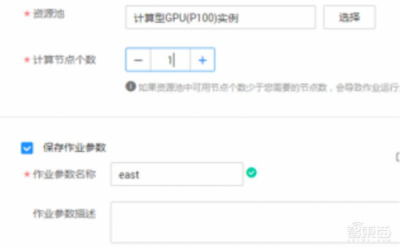
点击运行,还可以在日志里看到训练过程。
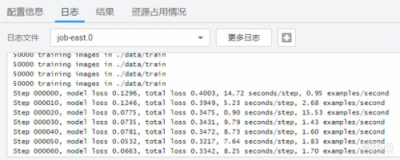
推理测试
在训练到一定精度后,就可以测试了。同样创建作业,选择test数据集,输入必要参数,
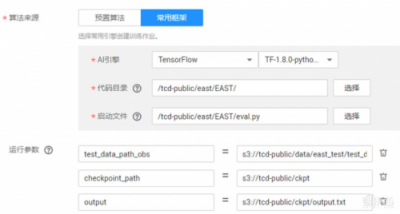
之后就可以得到测试集的检测结果了,里面的每行包含测试图片的名字和4个x和y的点。

2、OCR文字识别模型
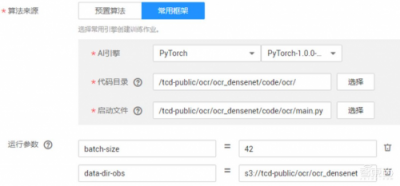
创建OCR训练作业
与EAST模型一样,将处理完后OCR模型的数据和OCR代码上传到OBS相应路径,就可以开始训练。
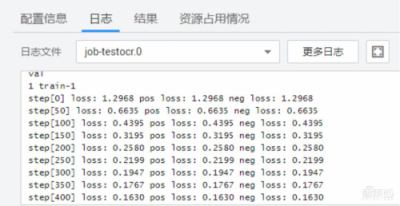
点击确定开始运行,在日志可以看到,几个step之后loss在下降了。
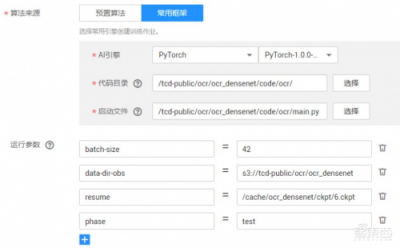
推理预测
最后一步,使用OCR训练完成的模型文件和EAST生成的数据进行推理测试,
最终可以在OBS路径上看到predict.csv的文件,下载就可以上传到比赛官网参赛了。
本文代码均已开源,且修改成了可以在ModelArts训练的格式,可以对比开源的EAST和OCR代码,查看修改了哪些地方。本文在OCR模型上用时6个小时,仅训练了10个epoch,就在排行榜A榜得到了0.42的F1,目测再训练久一点F1>0.80是肯定有的。
目前,超过700支队伍已经加入2019数字中国创新大赛的战局。
报名将到3月22日截止,进入比赛决赛的队伍将获得直通华为云终面的资格,前三甲还将分别获得8万、5万和3万元的奖金。感兴趣的开发者们快来参加比赛一试身手吧!
- 比亚迪整合五大子品牌为APP,打造一站式车主服务平台,体验升级中!
- 谷歌预警:警惕AI安全风险,公开防御蓝图
- 比亚迪起诉自媒体“智能EVO”:维权行动揭开名誉侵权黑幕
- 小米纸扎版SU7专利爆光,网友笑称清明节新爆款
- 微软暂停数据中心扩张计划:数据中心“退烧”,回归理性扩张
- 货拉拉力争2024年上市,营收增长19.39%达15.93亿美元,你准备好投资了吗?
- 巴西监管风暴下,苹果App Store应用追踪透明功能面临巨额罚款
- 中国快递协会严正声明:反对美取消“低价值包裹免税”政策,公平贸易不容欺诈
- 美股七巨头市值一夜蒸发逾万亿,金融风暴即将来临?
- 前华为智驾负责人苏菁:揭秘特斯拉自动驾驶真实水平,断代领先并非全然事实
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























