
云天励飞人工智能技术研究多项成果再获国际认可。近日,将于今年4月在日本举行的人工智能领域一大顶级学术会议——人工智能及统计学大会(International Conference on Artificial Intelligence and Statistics,简称AISTATS会议)收录结果揭晓,云天励飞AI技术部王孝宇博士与美国爱荷华大学杨天宝教授领导的团队合作的论文《A Robust Zero-Sum Game Framework for Pool-based Active Learning》入选。该论文提出了一种基于稳健优化的博弈主动学习算法,这有助于节省多种监督学习的标注成本。而在不久前,云天励飞另一篇有关采用递归网络模型解决视频人脸关键点定位的论文被计算机视觉顶级学术期刊IJCV收录。
用递归神经网络 为人脸关键点检测建立时间和空间联系
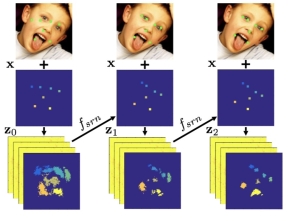
云天励飞被IJCV 2018收录的论文名为《RED-Net: A Recurrent Encoder-Decoder Network for Video-based Face Alignment》,团队在业界首次提出采用递归网络模型解决视频人脸关键点定位问题,以此来减少训练模型的复杂度,并实现对大姿态人脸和部分遮挡关键点的精确定位。此项工作的参与成员还包括IBM Watson研究院和新泽西州立大学。

Overview of the recurrent encoder-decoder network: (a) encoder-decoder (Section 3.1); (b) spatial recurrent learning (Section 3.2); (c) temporal recurrent learning (Section 3.3); and (d) supervised identity disentangling (Section 3.4). fenc, fdec, fsr n, ft r n, fc l s are potentially nonlinear and multi-layered mappings
据悉,传统视频人脸关键点检测通常使用级联化的的关键点坐标回归模型对关键点进行由粗到细的定位。在进行视频逐帧人脸关键点定位时,通过使用上一帧人脸的检测框和关键点信息对该帧的定位任务进行更精确的初始化。这类级联回归模型不同级间并不共享参数,模型训练对数据量的要求较高。
An unrolled illustration of spatial recurrent learning. The response map is pretty coarse when the initial guess is far away from the ground truth if large pose and expression exist. It eventually gets refined in the successive recurrent steps
云天励飞团队等在论文中提出了一种新的递归编码解码器(Recurrent Decoder-Encoder)模型结构来解决视频人脸关键点定位问题。在空间域上,该模型变传统多级级联模型为单一递归模型,大幅度减少模型的复杂度。在时间域上,该模型将编码器生成的嵌入特征中的时变因素和时不变因素进行解耦,并对时变部分用递归网络进行建模学习。

An unrolled illustration of temporal recurrent learning. Cid encodes temporalinvariant factor which subjects to the same identity constraint. Cpe encodes temporalvariant factors which is further modeled in ft R N N
相比传统视频人脸关键点处理中只使用上一帧结果初始化,这种时域递归网络能够学习和利用更长时间范围内关键点的位置信息和变化规律,实现对大姿态人脸和部分遮挡关键点实现精确定位。
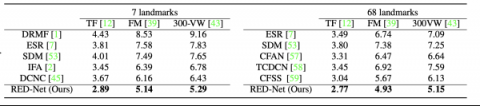
据介绍,与国际主流方法相比较,在7关键点和68关键点两种模式下,采用递归网络模型定位视频人脸关键点的方法,在Talking Face, Face Moive 和 300VW 三个公开数据集平均误差都显著低于这些主流方法。
将模型训练和标注选取结合 提升模型训练效果
大数据时代来临,人工智能领域面临的一大难题是如何获取监督学习所需要的大数据对应的数据标注。对于监督学习来说,并不是每个标注数据对模型训练的帮助程度都是等同的,即有些数据对模型训练帮助更大。而主动学习则是研究如何选取潜在对模型训练更大的未标注数据去给予它们标注,从而达到提升模型训练效果、节省人工标注成本的目的。
不过,目前已存在的主动学习算法大多或是基于分类模型产生的数据不确定性并利用一些启发式策略进行标注数据选取;或是利用其它理论如信息理论、学习理论定义数据不确定性并产生一些优化式策略进行标注数据选取。
分开进行标注数据选取和模型训练可能会存在二者步调不统一的情况,从而无法得最优的结果。《A Robust Zero-Sum Game Framework for Pool-based Active Learning》提出的思路并不像之前其它算法那样把模型训练和标注选取两个模块割裂开来,而是利用博弈论将其结合在一起,并引入稳健约束进行优化,以获得最直接的标注数据选取,以及模型训练效果的提升。
作者基于博弈论提出的优化目标函数如下:
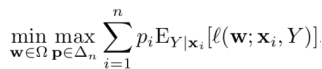
其中w代表模型参数,如支持向量机(SVM),深度神经网络(DNN)等;p为单个数据产生的损失的权重(由于是主动学习场景,考虑到存在未标注数据,作者使用的是对于所有可能标注的期望损失
作者采取在线梯度下降(online gradient descent)更新模型参数w:
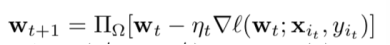
作者采取镜像下降(mirror descent)更新数据损失权重p:
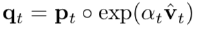
由于加入了稳健约束,作者利用近似映射的方法矫正p:

对于方差小的数据,加入稳健约束可以获得更好的模型泛化效果:
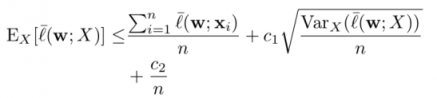
当数据方差数量级小于1/n时,泛化错误将为O(1/n)而不是通常的O(1/sqrt(n)).
此外,作者运用了在线算法的分析思路证明了算法收敛的遗憾界限(regret bound):
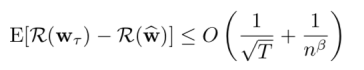

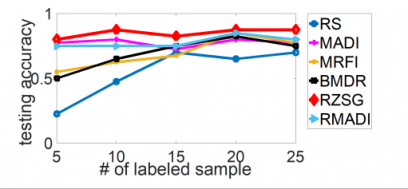
最后,作者进行了对于SVM和DNN的主动学习实验,并采用了一些知名机器学习算法效果对比数据集(benchmark datasets),效果如下 (横轴为标注数据数目,纵轴为测试准确度,RZSG为论文提出的算法):



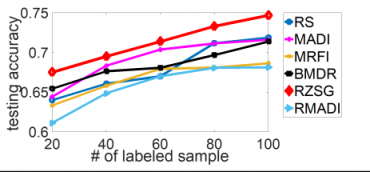
MNIST

CIFAR 10

- 2025款哈弗H5黑化归来:新车售价14.78万元起,硬派越野更狂野
- 特斯拉市值重回8000亿美元,国产电动车哪吒受配件短缺困扰
- 英伟达高管再探封测秘境:HBM3E供应步入紧要关头,行业风向再引关注
- 微软华硕联手打造Xbox掌机,2025年底前上市!轻薄便携,游戏体验升级!
- 华为笔记本即将告别Windows,微软许可到期,鸿蒙系统将全面接管
- 多款电动自行车充电器质量堪忧,消费者需警惕,选购要谨慎
- 2024年大陆PC市场趋势:联想华为逆势增长,出货量降幅收窄
- 保时捷财报双降:中国市场挑战与新机遇并存
- 特斯拉计划美国翻番生产,马斯克展望美未来:挑战与机遇并存
- 6G研发提速:2030年能否实现6G商用,让我们拭目以待
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























