
11月20日,有OCR领域奥斯卡之称的国际文档分析与识别大会(ICDAR)数据集最新结果公布,中国高校及企业包揽排行榜前五。中国人工智能“国家队”云从科技提出的Pixel-Anchor框架在多个ICDAR测试子集(ICDAR2015以及ICDAR2017 MLT)上均获得了第一名的好成绩,特别是在东亚语言(包括中文)部分表现亮眼。
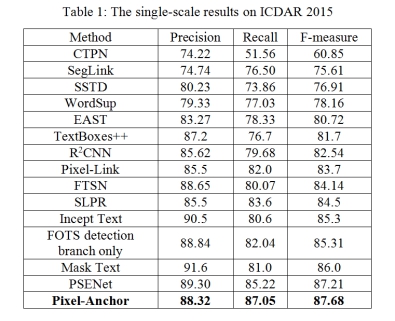
ICDAR2015数据集前五名及框架名称分别是:云从科技(Pixel-Anchor)、南京大学与南京理工大学(PSENet)、旷视科技(Mask Text)、商汤科技(FOTS)、阿里巴巴(IncepText)。

ICDAR2017 MLT数据集前五名及框架名称分别是云从科技(Pixel-Anchor)、阿里巴巴(ATL-cangjie)、商汤科技(FOTS)、旷视科技(EAST++)、南京大学(PSENet_NJU)。

国际文档分析与识别大会(ICDAR)专注于文本领域的识别与应用,自2003年大会设立“Robust Reading Competitions”以来,该竞赛就成了评测和检验自然场景/网络图片/复杂视频文本自动提取与智能识别最新技术研究进展的最为重要的国际赛事及标准,竞赛中的诸多方法对OCR技术的发展具有强大推动力。高技术难度、强大实际应用性,也使该盛会受到科研院校、科技公司等的关注,至今已有全球89个国家的3500多支队伍参与。
截至目前,全球顶级的高校、科研机构及企业都参加过这项测试,包括Google、Microsoft、Amazon、Facebook,以及中国的腾讯、搜狗、北京大学、中国科学技术大学等。
云从科技、阿里巴巴、南京大学、南京理工大学、商汤科技、旷视科技在榜单中体现出良好的成绩,表明中国继续在国际上引领OCR领域的研究。
计算机视觉基础技术
应用前景广泛
OCR(Optical Character Recognition)是指对输入图像进行分析识别处理,获取图像中文字信息的过程,具有广泛的应用场景。而自然场景中的OCR 技术不需要针对特殊场景进行定制,可以识别任意场景图片中的文字。

和面对高质量文档图像的传统OCR相比,自然场景OCR跳出了对输入图像的质量和场景束缚,能够在更宽泛的领域中获取应用,引起了学术界以及工业界的极大关注。
但相较于传统OCR,自然场景OCR中的各种商品、布景或自然场景图片中的文本检测与识别面临着复杂背景干扰、文字的模糊与退化、不可预测的光照、字体的多样性、垂直文本、倾斜文本等众多挑战。
OCR是计算机视觉领域的经典问题,长久以来,一直受到学术界和工业界的持续关注。在工业界,Google、Microsoft、Amazon等大型互联网公司,以及云从科技等人工智能创业公司,都在OCR技术上耕耘多年。随着技术不断成熟,OCR也开始在互联网及其他行业逐步上线使用,应用范围也从文档识别扩展到照片分析、车牌识别,图片广告过滤,场景理解,商品识别,街景定位,票据识别等广泛的领域。
免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。





























