
2023年5月中旬,OpenAI推出的GPT-4o凭借其突破性的智能交互能力,颠覆了我们对人机交互的传统认知,掀起了一股多模态大模型的新浪潮。3个月后的今天,国内AI领域的独角兽企业云知声也正式推出了山海多模态大模型,迎接“Her时代”的正式到来。
云知声山海多模态大模型通过整合跨模态信息,实现了文本、音频、图像等多种形式输入的全面兼容,并能够实时生成文本、音频和图像的任意组合输出,为用户带来实时多模态拟人交互体验。
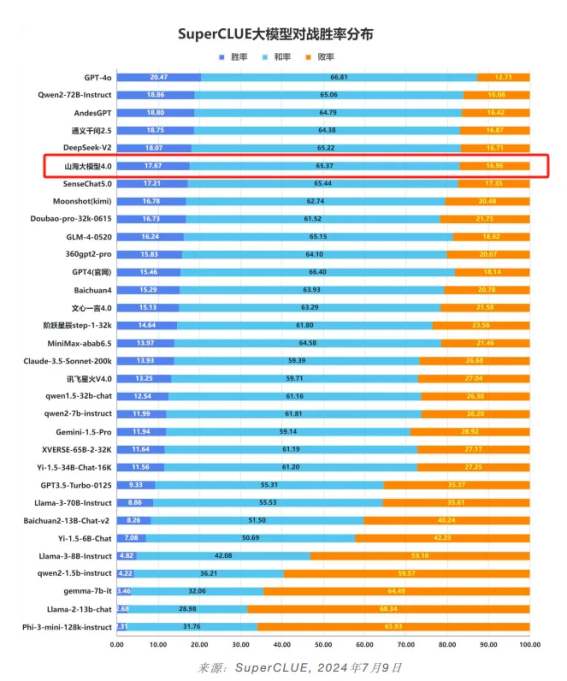
这一模型的发布预示着云知声在AI技术领域的又一次重大飞跃。回顾2023年5月,云知声首次发布了山海大模型,这是其在AGI领域交出的第一张答卷。自发布以来,山海大模型始终保持高速迭代,不断在权威赛事上崭露头角。在SuperCLUE中文大模型基准测评、MedBench中文医疗大模型评测、CCKS 2023医疗大模型评测等赛事中,山海大模型屡获佳绩,展现出全面的通用能力和不俗的专业能力,稳居全球大模型的第一梯队。
在大模型迭代路上,云知声深知,虽然山海的语言理解、知识储备和逻辑推理能力至关重要,但推动其迈进AGI的关键,在于多模态交互能力的发展。多模态交互能力的提升将使山海不再局限于单向的信息处理,而是真正成为一个能够深入理解世界、与人类进行自然而富有洞察力的交流的智能伙伴。
正是基于这样的愿景,云知声在不断提升山海大模型自然语言处理能力的同时,也在积极发展其多模态能力。在CVPR 2024开放环境情感行为分析竞赛中,云知声一举夺得了人脸情绪识别、复合情绪识别、情绪模仿强度估计三个赛道的季军,充分展现了其在情感分析方面的能力。
此次推出的山海多模态大模型,在语音交互方面更是实现了质的飞跃。它不仅能够实时秒回、自由插话,与用户进行几乎无感知延迟的流畅对话,还支持对话随时打断,用户可在对话中灵活插话,无需等待,交互过程自然不受阻碍。同时,山海还能通过智能语音技术感知和表达情绪,细致捕捉用户语音的语气、节奏和音调等微妙变化,从而更准确地感知对方情绪状态,并像人类一样予以适当的情感反馈。
除此之外,山海多模态大模型在视觉交互方面也有着出色的表现。通过摄像头,它能够看见周围环境,实现所见即所得的精准识别。无论是场景理解分析还是物体信息描述,山海多模态大模型都能提供全面而深入的分析。同时,它还具备图像创意生成的能力,能够根据用户指令快速创建视觉内容,并提供符合个性化需求的定制画面。

随着多模态技术的深入发展,云知声山海多模态大模型将具备更强的能说能听会看的能力,还将进一步拓展实时语言翻译、面部情绪分析等更深入的多模态能力。这些能力的提升将使山海多模态大模型全方位满足人们在工作、社交、娱乐等方面的多样化需求,成为人们生活中不可或缺的一部分。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















