
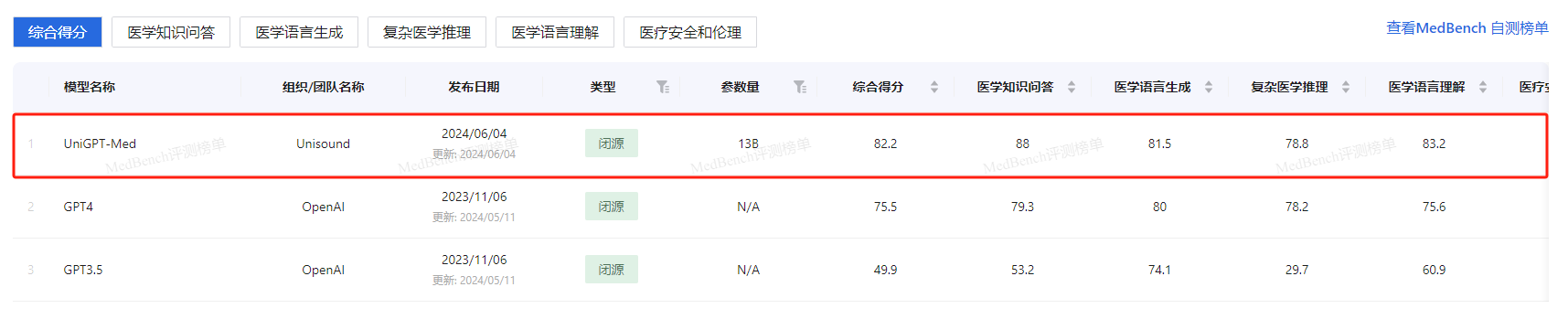
近日,由上海AI实验室和上海市数字医学创新中心联合推出的MedBench评测更新榜单,继4月份夺冠后,云知声山海大模型医疗行业版(UniGPT-Med)再次以综合得分82.2的优异成绩位列全球第一,各项指标全面超越GPT-4,充分展现出山海大模型在拥有业内一流的通用能力之外,更具备打造世界领先的行业大模型的能力。
MedBench致力于打造一个科学、公平且严谨的中文医疗大模型评测体系及开放平台,其基于医学权威标准,不断更新维护高质量的医学数据集,全方位多维度量化模型在各个医学维度的能力。
MedBench的五大评测维度——医学语言理解、医学语言生成、医学知识问答、复杂医学推理、医疗安全和伦理,构成了其专业评测框架的核心。这一框架吸纳了海量医学知识库和医院医学专家的丰富经验,涵盖8个公开数据集和12个自建数据集,总计约30万道中文医疗专业测评题目,覆盖了从医学考试题库到患者服务、医学问诊、病例分析以及病历生成等广泛的医学任务,致力为中文医疗大模型提供客观科学的性能评测参考。
今年5月,MedBench平台全面升级,不仅引入API评测方式,丰富了参评途径,还优化了开放域问答的评估指标。通过医学专家的精准标注,平台进一步提升了评测结果的公正性和专业性。同时,平台在数据集、评测方法和系统功能等方面也进行了升级,旨在为医疗大模型评测构建一个更加完善的社区环境,并提供更加丰富、真实的实践场景。
此次评测,云知声山海大模型医疗行业版(UniGPT-Med)通过API提交方式,不仅以82.2的综合得分刷新了MedBench评测记录,更是在各个维度上力压GPT-4,排名全球第一。这一成绩的取得,是山海大模型医疗专业能力的集中展现,也标志着其技术迭代和创新发展达到了一个新的高度。
目前,山海大模型通用能力已超越GPT-3.5,并在SuperCLUE 4月评测中跻身国内大模型Top10;与GPT-4的对战中,山海综合胜率与和率为75.55%。
在医疗专业能力上,山海大模型于2023年6月的MedQA任务中超越Med-PaLM 2,取得87.1%的优异成绩;在临床执业医师资格考试中以523分(总分600分)的优异成绩,超过99%的考生水平;其基于山海大模型孵化的医疗行业版大模型,也在CCKS 2023 PromptCBLUE医疗大模型评测中夺得通用赛道一等奖。
随着医疗行业对智能化、精准化服务需求的不断增长,云知声山海大模型医疗行业版(UniGPT-Med)有望在医疗健康领域扮演更加关键的角色,为提升医疗服务效率、优化患者体验、推动医疗科技进步提供强有力的支持。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















