
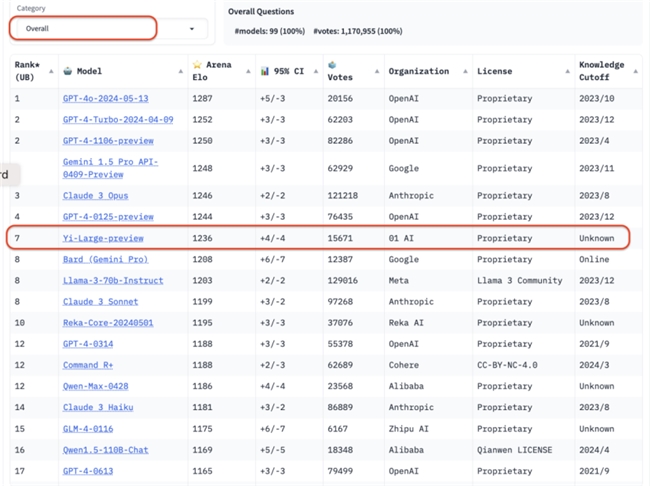
美国时间2024年5月20日刚刷新的 LMSYS Chatboat Arena 盲测结果显示,零一万物公司推出的最新千亿参数模型——Yi-Large,在总榜上荣登世界模型第七名,也是入围前十名的唯一中国国产模型。
LMSYS Chatboat Arena 盲测采用的是接近用户体感的“聊天机器人竞技场”特殊测评模式,让众多大语言模型在评测平台随机进行比试,通过众筹真实用户来进行线上实时盲测和匿名投票。值得一提的是,为了进一步提升Chatbot Arena查询的整体质量与可靠性,LMSYS积极推行了重复数据删除机制,并成功发布了经过冗余查询清理后的榜单。
此次Chatbot Arena共有44款模型参赛,其中不乏业界翘楚的开源模型Llama3-70B,同时也汇聚了多家知名大厂精心打造的闭源模型。

根据最新公布的Elo评分来看,GPT-4o以卓越的1287分荣登榜首,展现出其强大的性能。紧随其后的是GPT-4-Turbo、Gemini 1.5 Pro、Claude 3.0pus以及Yi-Large等模型,以大约1240分的评分稳居第二梯队,表现出不俗的竞争力。然而,位列其后的Bard (Gemini Pro)、Llama-3-70b-Instruct、Claude 3 sonnet,其评分则出现显著下滑,约至1200分左右。
此次排名中,前六位的模型分别归属于国际知名的科技巨头OpenAI、Google以及Anthropic。特别值得骄傲的是,零一万物以强大的实力位列全球第四大机构。同时,GPT-4、Gemini 1.5 Pro等模型均为拥有万亿级别超大参数规模的旗舰模型,而其他模型也均具备大几千亿参数级别的规模。Yi-Large “以小搏大” 以仅仅千亿参数量级的规模,在激烈的竞争中脱颖而出,紧追前列的参数规模数倍的超大模型。
5月13日Yi-Large正式发布,一周左右便迅速攀升至世界排名第七的位置,与海外大厂的旗舰模型处于同一梯队。此外,在 LMSYS Chatbot Arena 截至5月21日的总榜上,阿里巴巴的Qwen-Max大模型以Elo分数1186分位列第12名,智谱AI的GLM-4大模型则以Elo分数1175分排名第15,同样展现了中国科技企业在人工智能领域的强劲实力。
在当前大模型融入商业应用的过程中,需要通过具体应用场景的严格考验来证明其价值和潜力。为了行业的健康发展,必须追求更为客观、公正且权威的评估体系。Chatbot Arena这样的评测平台,通过真实用户反馈和盲测机制,确保评估的真实性和权威性。厂商应积极参与权威评测平台,展示产品的竞争力和优势,这有助于提升品牌形象和市场地位,推动技术创新和产品优化。反之,忽视实际应用效果的厂商将难以在竞争激烈的市场中立足。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















