
继去年发布并开源VisualGLM-6B和CogVLM之后,智谱AI宣布近期将推出新一代多模态大模型CogVLM2。这款模型以其19B的参数量,在性能上接近或超越了GPT-4V。
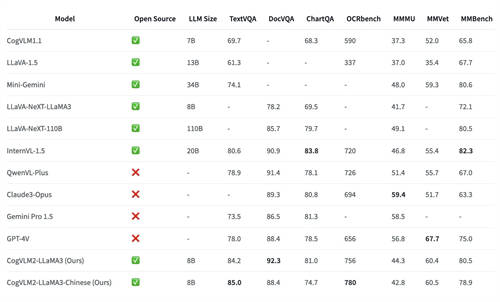
据悉,CogVLM2系列模型在多个关键指标上实现了显著提升,如在 OCRbench 基准上性能提升32%,在TextVQA基准上性能提升21.9%,且模型具备了较强的文档图像理解能力(DocVQA)等。此外,CogVLM2支持8K文本长度和高达1344*1344的图像分辨率,同时提供中英文双语的开源模型版本。
CogVLM2 继承并优化了上一代模型的经典架构,采用了一个拥有50亿参数的强大视觉编码器,并创新性地在大语言模型中整合了一个70亿参数的视觉专家模块。这一模块通过独特的参数设置,精细地建模了视觉与语言序列的交互,确保了在增强视觉理解能力的同时,不会削弱模型在语言处理上的原有优势。这种深度融合的策略,使得视觉模态与语言模态能够更加紧密地结合。
值得注意的是,尽管CogVLM2的总参数量为190亿,但实际激活的参数量仅约120亿,这得益于精心设计的多专家模块结构,显著提高了推理效率。此外,CogVLM2能够支持高达1344分辨率的图像输入,并引入了专门的降采样模块,以提高处理高分辨率图像的效率。
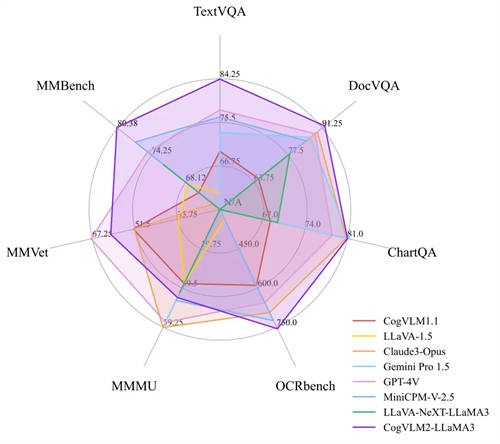
在多模态基准测试中,CogVLM2的两个模型,尽管具有较小的模型尺寸,但在多个基准中取得 SOTA性能;而在其他性能上,也能达到与闭源模型(例如GPT-4V、Gemini Pro等)接近的水平。
开发者可以通过GitHub、Huggingface、魔搭社区和始智社区下载CogVLM2的模型,团队还透露,GLM新版本会内嵌CogVLM2能力,在智谱清言App和智谱AI大模型MaaS开放平台上线。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















