
近期,Kim宕机的新闻让达模型商业化拼杀进入白热化阶段。与此同时,零一万物API也正式开箱,开发者可以直接调用包括多模态交互、200K超长文本、通用Chat等三大模型促成模型在更多应用场景的落地。
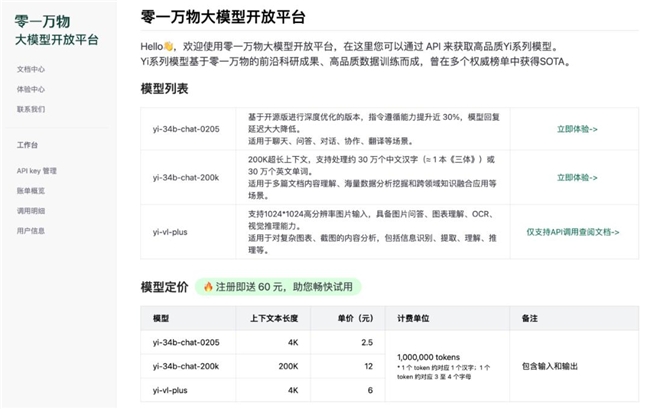
目前,Yi大模型API名额已经开放,新用户申请成功即送60元体验。这次,性能更强的多模态模型,更专业的推理模型,和OpenAI API随意切换的兼容性,以及超低的价格,都是不小的惊喜。
针对实际应用场景,多模态模型Yi-VL-Plus能力显著增强,支持复杂图表理解、信息提取、问答以及推理,甚至优于GPT-4V。
如,一张有些重影的图片,让Yi-VL-Plus模型识别这是什么店。

Yi-VL-Plus准确给出了店名“风水鱼自选超市”,并解释了这个店铺是做什么的。

GPT-4V的解释则不太准确,竟然识别成了“风水宝地鉴定中心”,令人哭笑不得。

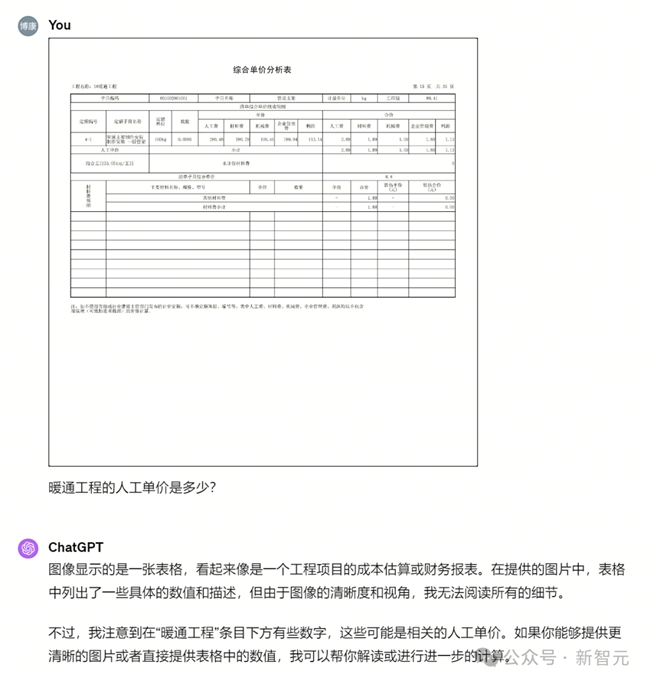
中文图表的体验中Yi-VL-Plus表现也很优异。新升级模型在Yi-VL基础上进一步提升图片分辨率,支持1024*1024,明显提升了场景中文字、数字OCR识别准确性。比如下面这张分辨率低,表格繁杂的图,提问:“通暖工程的人工单价是多少”,Yi-VL-Plus可以很快给出正确答案:33.054元/工日。
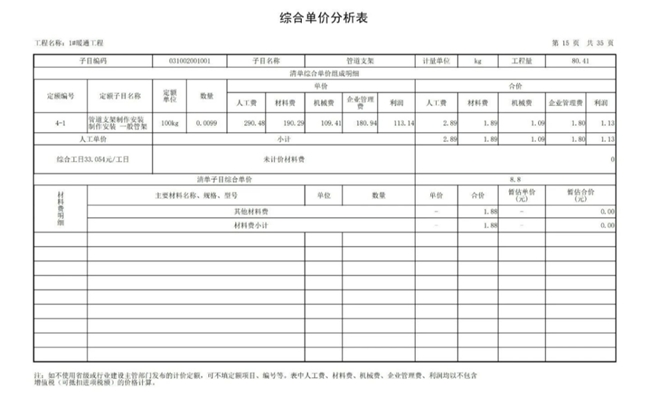

而GPT-4V则在处理照片信息方面遇到了问题,给出了一段似乎是回答的“周边回答”,就是没有呈现准确的数字。
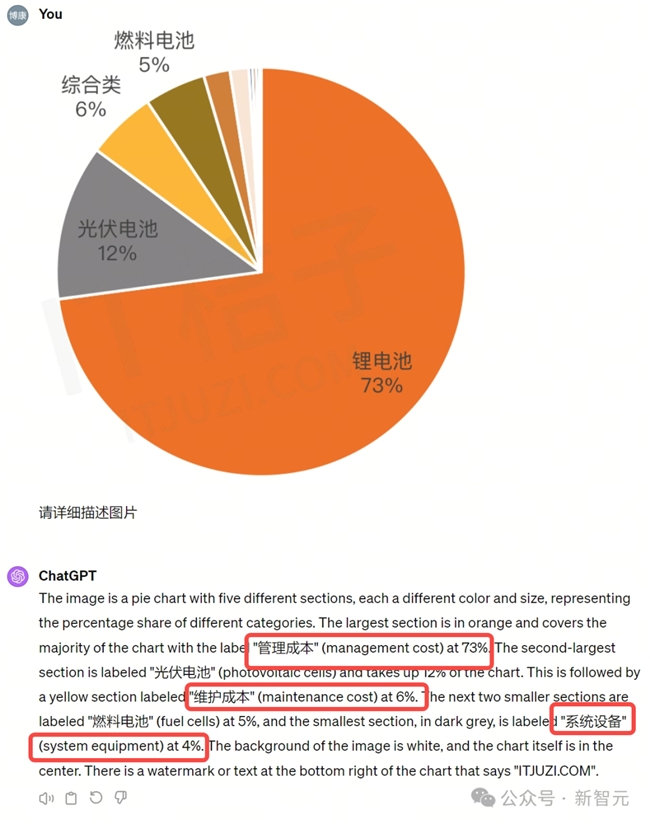
除了表格,Yi-VL-Plus处理饼状图的表现也可圈可点。在面对同样一张饼图,Yi-VL-Plus精确表述了饼图中所显示的内容,并且在数字对应上,没有出现任何错误。
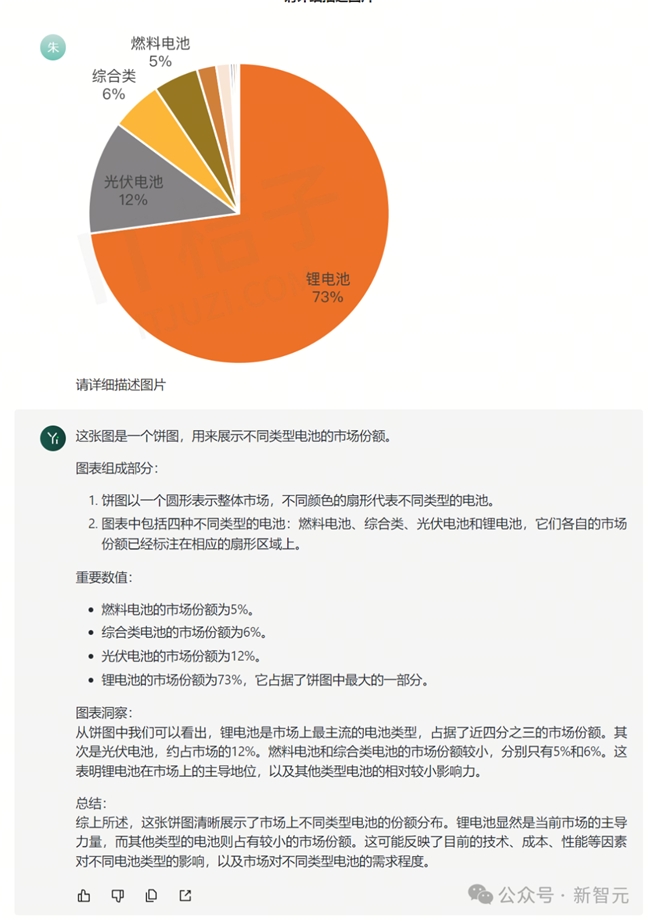
同样的问题交给GPT-4V,表现则不那么乐观,无法正确认出饼状图中的中文字。
综合来看,Yi大模型体验丝滑,可以成为企业和个人的工作好帮手!
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















