
语音情感识别是语音处理中最活跃的研究领域之一,其在人机交互、机器人、智能客服等领域具有广泛应用。语音情感识别技术是指通过分析人的语音信号,识别出其中所包含的情感信息。语音情感识别的基本过程包括语音信号的预处理、特征提取和情感分类三个步骤。然而,语音情感识别仍面临一些挑战,如特征提取和分类。传统的特征提取方法主要依赖于人类的先验知识,而现有的基于深度学习的方法往往需要大量的标注数据。此外,情感标签不平衡问题也是影响分类性能的关键因素之一。
为了解决这些问题,微美全息(NASDAQ:WIMI)将混合数据增强和扩展卷积递归神经网络引入语音情感识别。结合混合数据增强和扩展卷积递归神经网络的优势,可以更准确地识别和分类语音中的情感信息。混合数据增强是一种通过将不同的数据增强技术结合起来,提高语音情感识别性能的方法。在混合数据增强中,可以使用多种技术,如时域变速、频域扰动、噪声添加等,来对原始语音信号进行处理,生成增强的语音数据集,增加数据的多样性。扩展卷积递归神经网络(Expanded Convolutional Recurrent Neural Network,ECRNN)是一种结合了卷积神经网络(Convolutional Neural Network,CNN)和递归神经网络(Recurrent Neural Network,RNN)的神经网络模型,可以有效地捕捉语音信号中的时序特征和上下文信息。ECRNN模型在卷积层中可以有效地提取语音特征,而在递归层中可以捕捉语音序列的时序信息,通过使用ECRNN模型,可以更好地学习复杂的语音情感特征,提高情感识别的准确性。
首先,使用混合数据增强技术对原始语音数据进行处理,生成多样化的训练数据。例如,可以添加不同强度的噪声、改变音调或语速等。接下来,利用扩展卷积递归神经网络作为模型,对处理后的数据进行训练和学习。该网络结合了卷积层和递归层,其通常由卷积层、循环层和全连接层组成,卷积层用于提取语音特征,循环层用于捕捉序列信息,全连接层用于分类预测。可以有效地提取语音信号中的时序特征和上下文信息。通过对训练数据进行迭代训练,可以得到一个具有较高准确度的情感识别模型。使用该模型对新的语音数据进行情感分类,从而实现语音情感识别的目标。
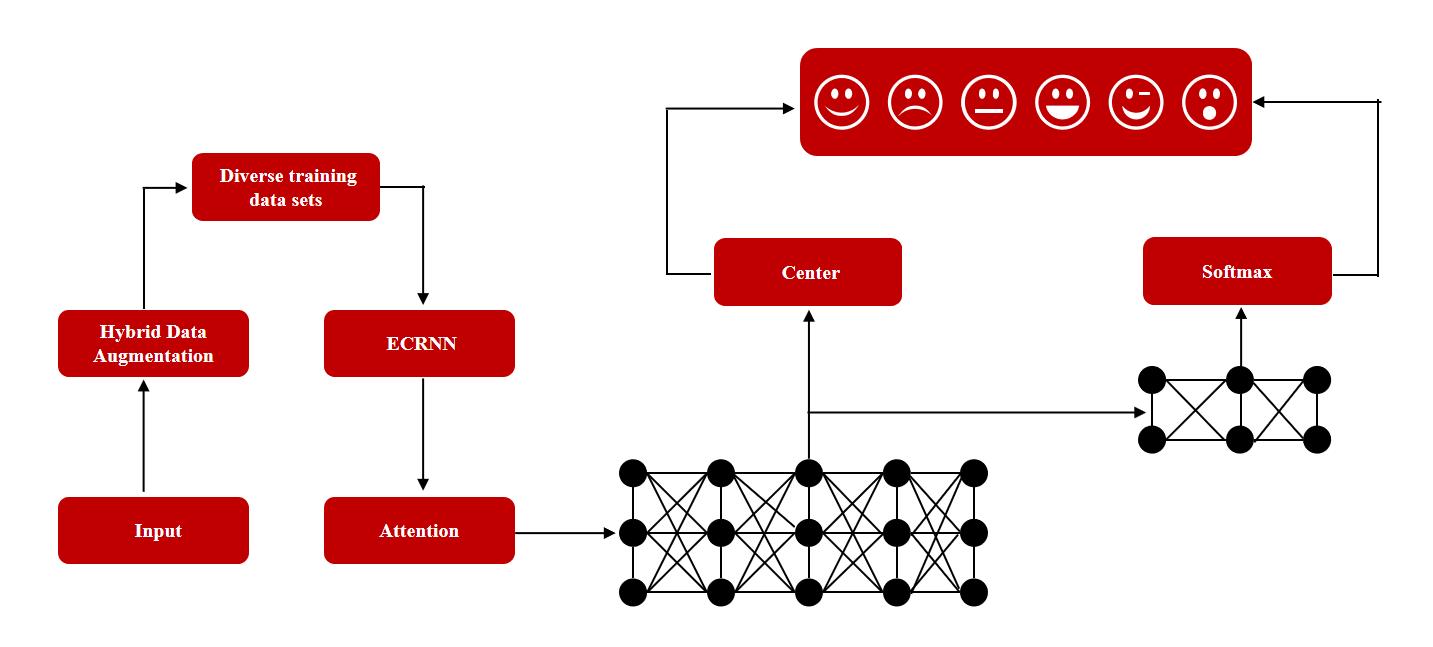
WIMI微美全息研究的基于混合数据增强和扩展卷积递归神经网络的语音情感识别技术通过增加数据的多样性和提取时序特征来提高情感识别的准确度和鲁棒性,并通过对语音信号进行预处理、特征提取和情感分类等步骤,准确地识别出语音中所包含的情感信息。这将为人机交互、情感智能等领域带来更加便捷和智能的体验。语音情感识别技术具有广泛的应用场景,涵盖了情感分析、心理健康监测、语音助手、教育和广告市场等领域。随着技术的不断发展和完善,语音情感识别技术将在更多领域发挥重要作用。
随着科技的不断进步,基于混合数据增强和扩展卷积递归神经网络的语音情感识别技术也在不断发展和演进。未来WIMI微美全息将通过增加更多的数据增强方法、设计更深层次的网络结构、多模态融合及跨语言情感识别等方向进行研究和实践,发展多模态情感识别、个性化情感识别、实时情感识别,进一步提升基于混合数据增强和扩展卷积递归神经网络的语音情感识别技术的性能和应用范围。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















