
无论是“海纳百川,有容乃大”的开源环境,还是“群英荟萃,百家争鸣”的技术氛围,属于国产数据库的时代大幕已经在每一位开发者的眼前缓缓展开。
近期,【国产数据库·共话未来趋势】线下沙龙在西湖畔落下帷幕,国产数据库领域资深专家汇聚一堂,共同交流探讨数据库技术。本次内容涵盖 AI 时代的向量数据库、关系型数据库与 Serverless 等前沿技术分享,以及如何在 K8s上管理数据基础设施等议题。
Zilliz 合伙人和技术总监 栾小凡 带来《当 AI-Native 遇到 Cloud-Native,向量数据库到底应该如何做》,分享 Zilliz 在 AI 时代做了哪些事情,以及从 Zilliz 的角度出发怎么看待向量数据库或者非传统数据库未来的发展。

栾小凡首先提出, AI-Native 时代的到来对于数据库提出了更多要求,相应地开发者对其需求也发生了变化,具体包括以下四个方面:
非结构化数据理解困难。非结构化数据(长文本、视频、图片、音频、生成分子式、推荐信息)无法通过简单的机器学习算法进行 Zero Shot 的理解,大模型的出现给非结构化数据理解和处理提供了新的思路,通过更加通用的方式处理非结构化数据成为了可能。
语意正确。AIGC 时代,查询不再是准确 100% 的“正确性”,相关和上下文更加重要,基于向量检索的方案成为主流。
数据体量庞大。未来超过80% 的数据属于非结构化数据,AIGC 时代数据的生成速度远超过去,系统扩展性性能至关重要。
缺乏工具。虽然传统的结构化数据处理并不简单,但由于 ETL、数据库、数据仓库等工具在过去 30 年的发展,已经变得相对成熟。然而,非结构化数据处理的工具链才刚刚开始构建,这就使得结构化数据的处理变得更具挑战性(相较结构化数据)。
随后,栾小凡深度剖析了向量数据库在 AI 时代的变化过程。AI 1.0 时代,向量数据已经被广泛应用于机器学习应用中,包括推荐、搜索、翻译、图搜、风控、安防等;大模型时代的到来,使得向量数据涌现出维度更高、体量更大、用途更广泛的特征。在此过程中,全球*的向量数据库 Milvus 也经历从了 1.0 架构向 2.0 架构演进的过程。
提及当时重新搭建 Milvus 2.0 的决定,栾小凡感慨颇深。彼时,随着用户数据体量的增长,老的架构扩展性逐渐成为瓶颈;其次,随着 AI+大模型的快速发展,对向量数据库的功能要求越来越高,需要更加灵活的数据模型和 API;K8s 和云原生逐渐成熟,搭建分布式系统的难度逐渐降低……多种因素加持下,Milvus——这个集结了诸多优秀技术人的团队坚持向【做出世界*先进向量数据库系统】的理想靠近。*终,一个拥有 AI Native + Cloud Native 的 Milvus 2.0 诞生。
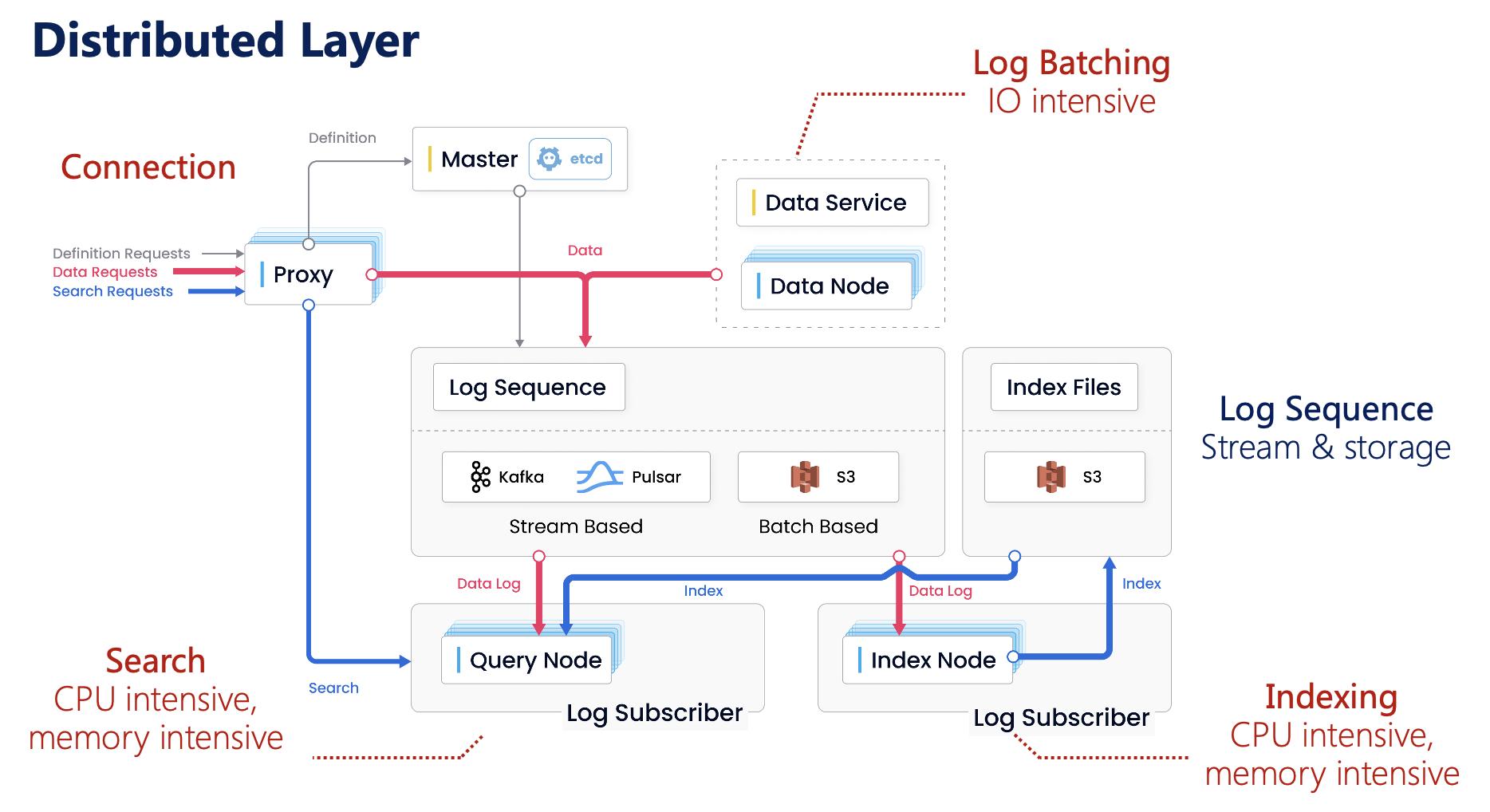
Milvus 2.0 架构
不过,栾小凡提到,向量数据库绝不仅仅是用来进行简单的向量检索,要想真正提升开发者的开发效率和使用成本,需要系统开发者深入理解硬件、存储、数据库、AI、高性能计算、分布式系统、编译原理、云原生等方方面面,以确保其稳定性、性能和易用性。一个理想的向量数据库应该具备以下特性:数据持久化和低成本存储、高性能查询、数据分布、易于使用、稳定可用。向量数据库是典型的 Big Data Serving 系统,可运维可观测、智能化。
想要了解更多对于向量数据库的知识,可关注微信公众号 Zilliz 获取。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















