
7月伊始,2023WAIC世界人工智能大会在上海开幕。海飞科Compass C10-S1X计算加速卡凭借显著的高性能、高性价比等优势,成功入围2023 SAIL奖TOP30榜单。同时,海飞科在会上集中展示了Compass C10(以下简称C10)高效部署ChatGLM、OPT、Stable Diffusion等模型方案,充分体现128GB 超大显存GPU实现单卡、分布式多卡部署千亿大模型的领先性和创新性,以强大算力赋能 AIGC 产业发展。
业界首个128GB超大显存GPU
轻松解锁千亿大模型部署
数月前,ChatGPT一路狂飙引发AI模型参数向百亿甚至千亿级演进,对模型推理部署的算力提出更高要求。但高性能GPU成本高昂且具有技术壁垒,制约 AI 大模型部署规模化。

面对AI大模型部署多重挑战,海飞科基于C10通用GPU高达128GB超大显存,与自有软件平台高效协同,达到算力和存储容量的优化平衡,为AI大模型部署提供通用敏捷、高性价比的解决方案。包括C10以128GB大显存高效支持大batch推理,实现单卡部署GLM130B千亿参数级别模型,为用户提供高性价比、高能耗比的算力;多卡分布式可部署超大模型,通过对算子、模型灵活切分,满足用户多任务处理低延时、高吞吐率的需求,可适用于人工智能的自然语言、图像、视频、音频等多模态模型部署。

C10是海飞科第一代通用GPU产品,依托通用并行计算架构、指令集等多项原创技术,兼容主流CUDA生态,拥有良好的通用编程能力和优异的高性价比算力,解决GPU通用性和高成本双重难题,可保留用户已有开发成果进行低成本迁移。此外,海飞科自研通用编程模型和完整软件工具链,提供语言级、算子级和模型级的通用开发界面,大幅度降低开发的门槛和难度,提升开发者工作效率,以更好地满足AI大模型部署和开发需求。
建立通用并行计算体系
加快通用GPU规模化落地
面向AI 2.0,海飞科自研通用并行计算架构,以统一内核打造产品体系,构建通用软件开发生态,为各行业用户提供高性能、低延时、低能耗、高性价比的算力服务,支持 AI 推理与训练、科学计算、图形渲染等应用场景。
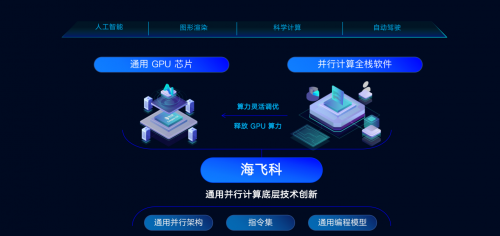
海飞科成功推出第一代Compass C10通用GPU芯片、C10-S1X和C10-S2X两款计算加速卡,支持多卡分布式部署,用户可根据吞吐率、延时、并发量等需求灵活配置,为算力规模、性能、密度带来质的提升。值得一提的是,C10在权威机构的综合评测中,其性能已企及市场主流产品,在处理张量数据类型的计算任务时,算力有效利用率有明显超出,更接近理论最大算力,验证了C10能为行业提供强劲算力的实力。
遵从开发者视角是海飞科软件平台的研发理念,打造面向AI应用的通用并行编程范式,提供高级语言编译器、AI 图编译器,支持 CUDA C、OpenCL 等高级编程语言,助力开发者提升工作效率。软件平台可对C10 GPU进行算力调优,可最大化的释放 GPU 算力,为AI 2.0产业筑牢算力基石。
作为建立通用并行计算体系的践行者,海飞科与头部服务器厂商、云服务厂商、算法厂商展加强合作,打造开放、普惠、共赢的产业生态,共同推动通用GPU规模化落地。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















