
智能客服机器人的核心是企业知识,而企业知识获取的核心步骤,是企业知识库的构建。
构建逻辑是:结构化企业数据,存入企业问答知识库。之后,根据知识库进行线上的FAQ问答(基于常见问答对的)、MRC问答(基于机器阅读的)等,对应构建形成 {问题:答案}、{文档}等知识库。
过往,这种企业知识库的构建,都是离线的、耗时的、需要人工反复校验的。尤其是上线后,为了提高机器人的问答准确率,就需要运营人员基于具体业务去持续做优化,如用户关键词抽取、实体抽取、同义词理解等等,耗时很多。
在AIGC时代,这一切都将改变。
构建知识库的速度和问答准确率,都将极大提升。主要是因为数据来源更容易无限扩展,不再局限于结构化、半结构化的企业文档,说明书,文字、语音、图片、视频等都可以被快速提取出有效信息,输入给大型预训练语言模型理解后问答,或者直接存储到知识库中,搜索后推出,也可二者结合。
1. FAQ文本知识库
FAQ(Frequently Asked Questions),即常见问题解答,是指整理和归纳常见问题及其对应答案的文档或资源集合。这些问题通常是某个业务场景下,客户会经常遇到的问题,可以帮助客服机器人快速、准确地解决常见问题,提升客户满意度。
FAQ文本知识库的创建、扩写对运营岗位的消耗较大。举个简单的例子:
query: “工作过多个城市,现在如何查询自己的公积金是属于哪个公积金中心?”。
我们需要对这个query扩展相似问,自动生成多个相似问。通过这种方式快速丰富知识库问题,同时提高实际线上问答的语义搜索结果可靠性。

就在这个过程中,扩展生成的相似问,需要经过多步自动化校验,包括答案一致性校验、口语化校验、相似性校验、属性分类校验等等。
答案一致性校验是指“从扩展的相似问题中,那些与原始query的标准答案相关,且该标准答案能对其进行解答的问题”。这样,它们有可能组成标准问题-相似问题对,答案也相同。
下面是通过答案一致性校验的相似问:

通过答案一致性校验后,还是会有很多问题。例如:
很多问题是有效问题,却不是该业务下的常见表述,简单来说就是不够口语化。这些问题,不仅会增加知识库的冗余,还会影响其他业务的搜索结果。针对这类问题还需要进行口语化校验,校验后保留如下:

经过上述校验的问答对,往往还会存在一个问题,就是相似性过高。这些问题,往往只是简单换了个词汇,存储知识库的必要性低。因此,我们还需要做一轮相似性校验,具体来说,就是根据业务特性设定去除和保留比例,通过聚类、相似度计算去除冗余部分。校验后保留如下:

可以看到,经过系列校验后,保留下来的相似问已经有很高的质量了。
在知识库的的构建方面,除了标准问、相似问的生成,还必须关注业务覆盖率这个指标,一般来说,业务覆盖率越高,知识库的质量也越高。
例如,“公积金”查询会涉及地点、时间、金额、查询方式、缴费方式等问题维度,维度越多,覆盖率就越高。
举个例子:可对“公积金归属地查询”这个原始问题拓展出的所有相似问题,进行分类,进一步发现更多有价值的句子。从下面分类结果看到,其中的类别1和原始问题答案相同,其他类别下的问题,是“公积金”相关的其他维度的业务问题,只是答案和原始问题的可能不同。那么,这些句子如果能加入知识库,就拓展了“公积金”相关的业务覆盖率。
对上面初始拓展的39个问题,分类如下:
类别1:公积金归属地的基本查询。
询问如何查询公积金的归属地,包括城市、地区、省份、县、区等,关注点寻找基本的位置信息。
分类结果包含:1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 13, 16, 18, 19, 21, 22, 24, 25, 27, 28, 30, 31, 33, 34, 37。
类别2:公积金归属地查询的具体步骤和流程
关注查询公积金归属地的步骤、流程,关注点是更详细的查询指导。
分类结果包含:11, 23。
类别3:公积金归属地查询的工具和平台
询问关于查询公积金归属地的工具、软件、系统、平台、网址等,关注点是查询工具和平台的选择。
分类结果包含:14, 17, 20, 26, 29, 32, 35, 38。
类别4:公积金归属地的详细信息查询
询问如何查询公积金归属地的具体地址、邮编、电话号码、邮寄地址等详细信息,关注点获取更具体的信息。
分类结果包含:15, 24, 27, 30, 33, 36, 39。
上面分类后的类别2、类别3、类别4,是经过答案一致性校验后,被排除的。查询知识库如果有相似query或答案,可进入到下一轮的自动化校验,对符合条件的可人工校验入库。另外,新增的这些问题,还可做预测性的FAQ (PFAQ),预测用户可能会遇到的问题,并提前提供问答。
2. MRC文本知识库
MRC问答,也就是机器阅读理解(Machine Reading Comprehension)的问答,系统通过阅读和理解自然语言文本,并根据这些文本回答给定的问题。在我们的机器人中,是将query和与它最相关的文本块给与LLM,输出answer。
通过文档上传,文档切片分块,向量化存储后,即可语义搜索。问答时,根据文档搜索结果和query一起加入Prompt,输入LLM理解后回答。
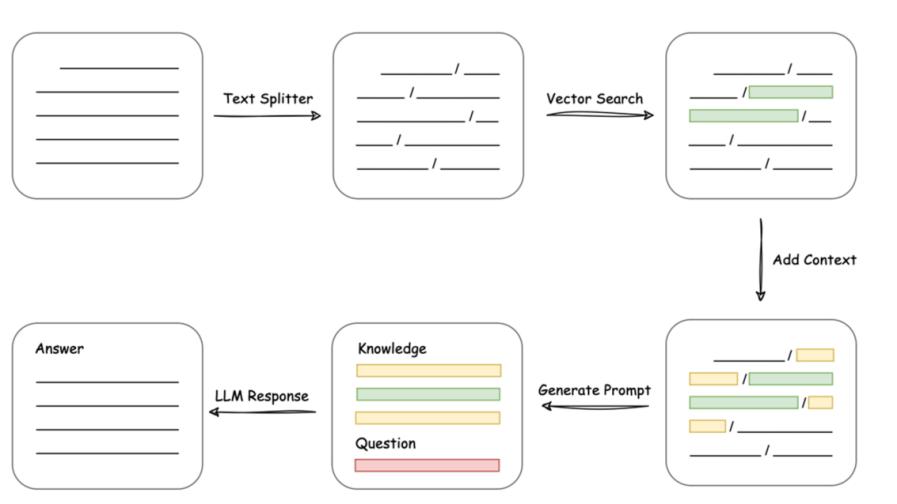
受限于语言模型的理解能力,过往的MRC的问答效果一般。现在,结合LLM模型, 文档理解和问答的准确性,已经能解决常见问题。
在智能问答客服机器人中,为进一步提高问答效果,对于分块文档,还可增加问答对的抽取。一方面结合原始的分块文档,可以提高query理解的准确性,另一方面,对于文档切片后引起的块内知识不完全,是个很好的补充。
常用的tricks,比如在原有的文档切片的基础上,提取摘要、关键词、关键句等信息,作为补充,也可提取问答对作为补充。
问答对的提取如下,例如分块后的文档如下:

进行问答对抽取,得到如下:

通过对切片后的文档进行问答对抽取,可以快速完成多源数据的知识库构建。
更重要的是,这种文档的直接切片分块,知识构建,在文档上传后,即可进行智能问答。好处是,快速更新的企业知识,也能够快速应用在业务中。
以上方法构建的企业知识库,生成校验极快。并且在机器人的问答准确性上,结合模型强大的理解能力,语义搜索后的多个潜在答案通过LLM进一步加工,答案准确性极高。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















