
近日,语音技术领域国际会议Interspeech公布了本届论文审稿结果,OPPO小布智能中心智能交互部语音技术组有5篇论文被大会收录。本次被接收的论文研究方向涵盖语音识别、模型压缩、目标说话人提取、语音鉴伪、异常声音检测等。
Interspeech是国际语音通信协会(International Speech Communication Association, ISCA)举办的年度会议,也是全球最大、最全面的专注于语音通信领域的学术盛会。Interspeech会议已成为该领域中来自各行各业的专家、研究人员、学生等,共同探讨、交流和分享前沿的语音技术、认知和创新的聚集地。本届Interspeech会议将于2023年8月20日至8月24日于爱尔兰都柏林举办。
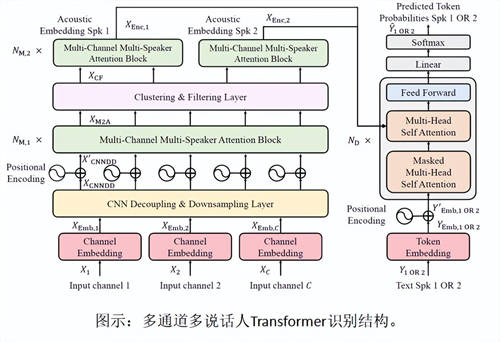
论文题目:Multi-Channel Multi-Speaker Transformer for Speech Recognition
论文作者:郭一凡,田垚,索宏彬,万玉龙
论文单位:OPPO
核心内容:随着线上会议和车载语音助手的发展,远场多说话人语音识别已经成为了一个热门的研究课题。近日,研究人员提出了一种多通道Transformer结构(Multi-Channel Transformer, MCT)。这一工作证明了Transformer结构具有建模远场声学环境的能力。然而,当存在多个说话人同时发声时,说话人之间存在的相互干扰,会导致MCT无法直接从多人混合音频中直接为每个说话人编码出对应的高维声学特征。基于此,我们在本文中提出了多通道多说话人Transformer语音识别结构。在SMS-WSJ开源数据集上的实验显示,我们提出的结构相较于基于神经网络波束形成器(Neural Beamformer),MCT,具有转换平均连接的双路径RNN(Dual-Path RNN with
Transform-Average-Concatenate)以及多通道深度聚类(Multi-Channel Deep Clustering)的方法,识别词错率分别下降了相对9.2%, 14.3%, 24.9%和52.2%。
论文题目:Task-Agnostic Structured Pruning of Speech Representation Models
论文作者:王皓宇,王思远,张卫强,万玉龙
论文单位:清华大学,OPPO
核心内容:近年来,基于无监督预训练技术的语音表征模型为许多语音任务带来了显著的进步,但另一方面,这些模型通常包括大量的参数,对硬件平台的计算能力和内存空间有很高的要求。为了将大模型部署到生产环境,模型压缩技术至关重要。结构化剪枝不需要特殊硬件就可以实现参数压缩和推理加速,是一种对硬件友好的模型压缩方法,但同时也会带来较大的性能损失。为了弥补性能损失,我们提出了一种细粒度的注意力头剪枝方法;除此之外,我们将梯度直通估计(Straight Through Estimator,STE)引入到L0正则化剪枝方法中,让模型参数的分布更加紧凑,从而实现了进一步的加速。我们在SUPERB排行榜上的实验表明,我们的压缩模型比Wav2vec 2.0 Base模型平均性能更好,同时参数量比前者减少30%,推理时间比前者减少50%。

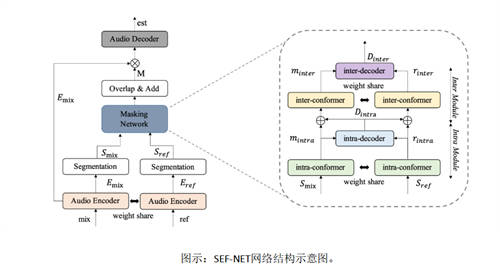
论文题目:SEF-Net: Speaker Embedding Free Target Speaker Extraction Network
论文作者:曾邦,索宏彬,李明
论文单位:武汉大学,昆山杜克大学,OPPO
核心内容:主流的目标说话人分离方法使用目标人的声纹embedding作为参考信息。获取声纹embedding的方式主要有两种:一是使用预训练的说话人识别模型进行声纹提取,二是采用多任务学习联合训练说话人识别模型来提取声纹。然而,由这两种方案的声纹提取模块都是面向说话人识别任务进行最优化训练的,所提取的声纹embedding对于目标说话人分离任务可能并不是最优的。本文提出一种新颖的、不依赖于声纹embedding的时域目标说话人分离网络SEF-Net。SEF-Net在Transformer解码器中使用跨多头注意力来隐式地学习注册语音的Conformer编码输出中的说话人信息并进行目标说话人分离。实验结果表明,SEF-Net与其他主流目标说话人提取模型相比具有可比性的性能。SEF-Net为在不使用预训练说话人识别模型或说话人识别损失函数的情况下进行目标说话人提取提供了新的可行方案。
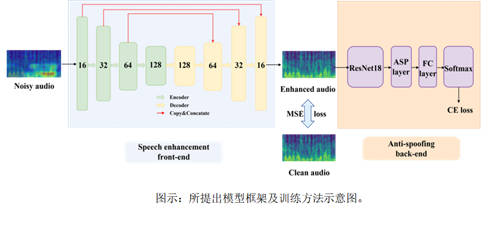
论文题目:Robust Audio Anti-Spoofing Countermeasure with Joint Training of Front-End and Back-End Models
论文作者:王兴明,曾邦,万玉龙,李明
论文单位:武汉大学,昆山杜克大学,OPPO
核心内容:很多语音信号处理系统的准确性和可靠性在噪声环境下往往会急剧下降。本文讨论了在噪声环境中的鲁棒伪造语音检测方法构建。首先,我们尝试使用预训练的语音增强模型作为前端模型,并构建级联系统。然而,增强模型的独立降噪过程可能会扭曲语音合成产生的伪影或抹除包含在语音中的与伪造相关信息,进而导致伪造语音检测性能下降。因此,本文提出了一种新的前端语音增强与后端伪造语音检测联合训练的框架,来实现对噪声场景鲁棒的伪造语音检测模型构建。所提出的联合训练框架在带噪场景的ASVSpoof 2019 LA数据集和FAD数据集上均验证了比朴素的伪造语音检测后端更加有效。此外,本文还提出了一种交叉联合训练方案,使单个模型的性能可以达到不同模型得分融合的结果,从而使联合框架更加有效和高效。
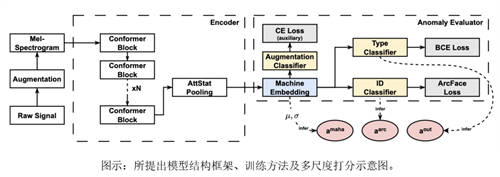
论文题目:Outlier-aware Inlier Modeling and Multi-scale Scoring for Anomalous Sound Detection via Multitask Learning
论文作者:章羽聪,索宏彬,万玉龙,李明
论文单位:昆山杜克大学、OPPO
核心内容:本文提出了一种异常声音检测方法,通过多任务学习将异常样本曝光(outlier exposure)和内部建模(inlier modeling)融合在一个统一的框架内。基于异常样本曝光的方法可以有效地提取特征,但其鲁棒性有待提高。内部建模能够生成鲁棒的特征,但这些特征的效果并不理想。最近,一些串行和并行方法被提出来将这两种方法结合起来,但它们都需要额外的步骤完成模型建模。这对于模型的训练和维护都造成了一些不便。为了克服这些限制,我们使用多任务学习的方法训练了一个基于Conformer的编码器,用于异常感知的内部建模。此外,我们的方法在进行推理的时候考虑了多尺度的异常打分,可以更加全面的评估异常值。在MIMII和DCASE 2020任务2数据集上的实验结果表明,我们的方法优于最先进的单模型系统,并且与比赛中排名靠前的多系统集成模型有相当的能力。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















