
近日,超对称与UCloud优刻得合作,将公司推出的3个大模型开源到UCloud官网,以“大模型+大算力“的方式,共同推进AICG创新应用。
2022年5月超对称技术公司发布大语言模型BigBang Transformer【乾元】的第一版BBT-1,10亿参数预训练语言模型,在中文金融语料上训练而成,发布之后即获得经济金融领域客户热烈反馈,作为大模型底座已经为多家中国和海外机构提供服务。
近期,超对称公司再推出BBT-2,这是一个基于120亿参数的通用大语言模型,并在BBT-2的基础上,训练出代码、金融、文生图等专业模型。
超对称技术公司将发布基于BBT-2的系列模型:
•BBT-2-12B-Text:120亿参数的中文通用语言模型
•BBT-2.5-13B-Text: 130亿参数的中文+英文双语基础模型
•BBT-2-12B-TC-001-SFT 经过指令微调的代码模型,可以进行对话
•BBT-2-12B-TF-001 在120亿模型上训练的金融模型,解决金融领域任务
•BBT-2-12B-Fig:文生图模型
•BBT-2-12B-Science 科学论文模型
通过与UCloud优刻得在算力和开源方面的合作,超对称还将3个大模型开源到官网、github和UCloud,后续用户可直接在UCloud官方平台通过GPU云主机的行业镜像或算力平台直接开箱使用这些模型:

●BBT-1-0.2B:2亿参数金融模型,包括三个不同预训练方式进行训练的模型, 训了600亿Tokens:
(1)BBT-1-0.2B-001:2亿参数,金融模型,T5Decoder+Encoder架构
(2)BBT-1-0.2B-002: 2亿参数,金融模型,T5+GPT
(3)BBT-1-0.2B-003: 2亿参数,金融模型,T5+UL2
●BBT-1-1B:10亿参数金融模型,T5Encoder+Decoder架构,使用金融中文语料库1000亿tokens进行预训练,包含社交媒体,财经新闻,券商研报,公司公告财报等数据
●BBT-2-12B-Text:120亿参数基础模型,GPT Decoder-Only 架构,未经指令微调,完成2000亿token预训练,模型性能还有较大提升空间,开发者可在通用模型上继续训练或进行下游任务微调
●BBT-2.5-13B-Text: 130亿参数基础模型,GPT Decoder-Only 架构,未经指令微调,完成2000亿中文+英文tokens预训
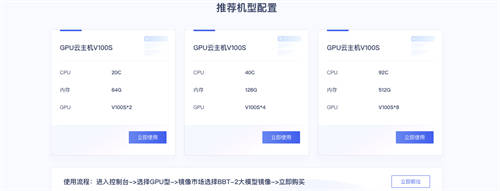
(UCloud官网开源模型使用流程)
以下是超对称技术公司基于BBT-2的系列模型介绍:
1、BBT-2-12B-Text 通用模型
BigBangTransformer[乾元]是基于GPT Decoder-only架构的大规模预训练模型。继2022年开源BBT-1-0.2B模型之后,正式开源最新系列的BBT模型:BBT-1-1B,BBT-2-12B-Text,BBT-2.5-13B-Text。预训练语料库覆盖14个高质量数据源,覆盖书籍、百科、论文、小说、新闻、政策文件、中文博客、社交媒体等多个数据源种类。BBT-2-12B-Text基于中文700亿tokens进行预训练,经过指令微调的BBT-2基础模型可以回答百科类和日常生活的问题。BBT-2.5-13B-Text基于中文+英文2000亿tokens进行预训练,暂时不开放基础模型的问答对话接口。
模型开源后所有开发者可以:
•可以直接调用大模型进行对话
•在我们训练的基础上使用自由语料库继续训练
•对大模型进行微调训练以满足各种下游任务



2.BBT-2-12B-Text+Code 代码模型
BBT-TC,是超对称技术公司近期发布的BBT-2大模型系列中的代码模型,在百亿基座模型BBT-2-12B-Text接续训练代码数据集,通过有监督指令微调(Supervised Fine-Tuning)解锁模型的推理能力。该模型在专业评测中分数超过其他中国公司开发的同类模型,仅次于GPT-3.5。
开发者可以在超对称公司官网https://www.ssymmetry.com测试BBT模型的代码问答(仅应用于代码生成场景,无法回答与代码无关的问题)
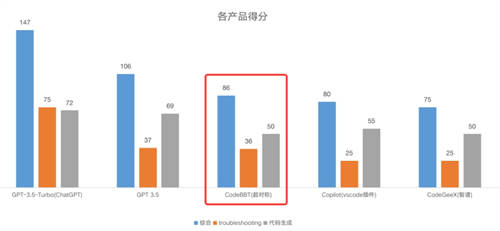

详情可见文章《超对称技术公司的代码大模型CodeBBT在专业评测中位居前列,仅次于GPT-3.5》
3、BBT-2-12B-TF-001 金融模型
超对称公司于2021年便开始针对金融投资领域的应用,着手设计和训练了一个大规模参数预训练语言模型Big Bang Transformer乾元(BBT),目前发布了Base 版本2.2亿参数和Large 版本10亿参数以及最新的BBT2,120亿参数通用模型。BBT模型的目标是为金融投资建立统一的人工智能算法框架,基于transformer构建能融合训练金融投资涉及的不同模态数据的架构。在统一架构的基础上训练大规模参数预训练模型,随着模型参数和训练数据集继续增大,超对称团队有希望开发出在金融领域接近人类智能水平的模型。作为金融领域的基石模型,BBT模型为所有金融投资,经济分析,商业咨询等场景的深度学习下游任务提供微调服务。
金融投资领域有大量从业机构和人员,大厂有财力雇佣算法工程师,小团队却用不起基本的文本抽取算法。BBT模型作为金融领域的算法基础设施,让所有从业者配备同级别的武器,让全行业站在同一起跑线去竞争更优的投资策略,从而推动金融和经济市场更高效的信息和要素流动。
为了更好地推进中文金融自然语言处理的发展,超对称搜集和爬取了几乎所有公开可以获得的中文金融语料数据:
1)过去20年所有主流媒体平台发布的财经政治经济新闻
2)所有上市公司公告和财报
3)上千万份研究院和咨询机构的研究报告
4)百万本金融经济政治等社会科学类书籍
5)金融社交媒体平台用户发帖

经测试,BBT-TF在公告摘要任务场景超越ChatGPT:使用ChatGPT和BBT-TF对同一份公告,相同输入,生成摘要并对比效果,发现BBT-TF更满足实际运用场景。BBT-TF还可进行四舍五入的计算。在金融行业对数字高精度要求下,BBT-TF可对单位进行准确的换算。
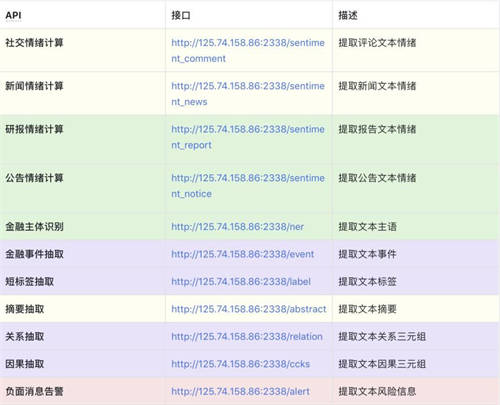
超对称已开发了11种已落地应用的下游任务,面向专业金融开发者API,已获得中国及海外金融机构付费
4.BBT-2-12B-Image文生图模型
基于BBT2大语言模型,超对称和中国专业图库公司联合开发文生图AIGC模型BBT-Fig,目前该模型向纺织行业,印刷,广告,游戏等行业客户提供文生图应用,经过专业评测,BBT-Fig在纺织行上的应用效果比Stable Diffusion和文心一格,明显更优。
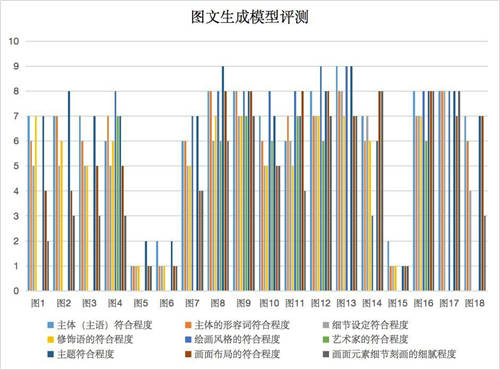
BBT-Fig能够生成非常逼真的图像,并且具有可控的样式和风格。在纺织行业中,BBT-Fig可以通过对不同纺织材料的图像进行学习,生成具有纹理(可无缝拼接)、色彩(色彩亮度不会受训练样本明暗影响,为标准化设计用样式)和设计元素(可随意组合元素)的纺织品图案,提高纺织品设计的效率和创新性。该技术还可用于家装等等需要图案设计的行业。

用于生成人造大理石花纹

5、BBT-2-12B-Science 科学论文模型
马斯克认为AGI的终极测试是模型能发现新的物理定律。GPT-4在医生资格考试、律师资格考试、AP考试、GRE上获得不错的分数,但目前还没有证明其能有效地发现或辅助人类知识库尚未存在的知识。
对于中国的大模型研发团队,直接瞄准大语言模型用于科学发现是超越GPT-4的一个可能路径。在科学研究上,研究人员可以使用语言模型来自动提取和分析论文中的主题、实验方法、结果和结论,从而发现新的科学发现和研究方向。
BBT-Science大模型是基于BBT大模型在几千万篇科研论文上训练构建的辅助科学发现的大模型,应用于物理、化学、生物、数学等不同学科的科研知识问题,可以提供三方面的能力
1、快速精准的知识检索。这项能力和大模型在其他领域的对话能力相近。
2、针对所研究领域的前沿问题提供新的ideas. 这种新ideas产生于大模型在该领域的海量数据检索和重新组合,发现前人未发现的可能性。
3、利用多学科知识训练出的能力提供跨学科的建议和洞见。这项能力潜力最大。
为了对科学大模型进行评测,超对称技术公司与复旦、上海交大、浙大、南航、中山大学、北师大等多所大学合作,正在号召全球一线的科研人员共同构建一个最大的科研问题评测数据集ResearchQA。该数据集覆盖数学、物理、化学、生物、地理地质、计算机、电子工程等主流科研领域。该数据集直接采集科研领域里前沿的研究课题作为问题,重点考察大模型回答的创新性。科学大模型将成为全球科研能力的底层引擎,带来科研生产力的加速。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















