
导语
为从海量数据中高效、实时、安全、简便地挖掘价值,柏睿数据推出一站式大数据平台Rapids Lizard,采用无中心架构,实现数据库的高可扩展性、高可靠性、高安全性和易运维,能够更好地支持海量数据处理和分析,助力企业加速实现数字化运营,驱动业务增长和创新。
从单机、集群架构到无中心架构
大数据时代,为满足不断增长的数据规模和并发访问需求,数据库经历了从单机架构到集群架构、分布式架构的演进,以提高数据库的可用性、可扩展性和处理分析性能。其中分布式架构又分为主从架构、多主架构和分布式无中心架构等常见类型。
我们可以通过“开饭馆”的故事简单直观地了解这几种分布式架构的特点。
假设我们创业开了一家小饭馆,经过辛勤经营,饭店的生意越来越好,单靠我们自己已经很难兼顾后厨管理了,于是提拔了一位老员工担任厨师长,来专门管理后厨各个厨师。此时厨师长相当于主节点,其他厨师相当于从节点;主节点负责协调所有从节点的工作,而从节点则负责执行具体的任务,此时整个后厨构成了主从架构;这种架构简单易于实现,但存在单点故障问题;如果主厨请假了,整个厨房可能无法正常运行。
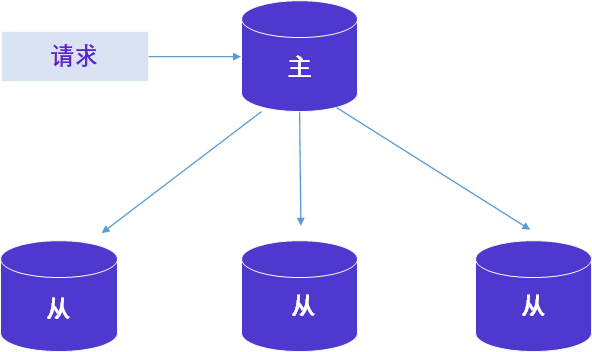
后来,我们的业务越做越大,后厨设立了两个出餐组,并在两个区域各任命一个主厨来分别管理各自区域;两位主厨之间协调合作,确保整个厨房顺利运作。此时,两位主厨相当于多个主节点,它们协调所有从节点的工作,整个后厨构成多主架构。这种架构可以实现更高的容错性,但可能出现数据不一致或不完整的情况。

还有一种便是完全无中心架构。假如我们没有在两个出餐组内分别任命主厨,因此厨师们之间没有固定的主从关系,而是通过协商来决定由谁负责制作哪道菜。此时,每个出餐组相当于一个节点,整个后厨相当于一个分布式无中心系统;每个节点都独立运作,负责处理分配给它的请求。这种架构在后厨中运用看起来会面临分工不明确、缺乏管理等问题,但作为数据库的技术架构,它较其他架构有着无可比拟的优势。
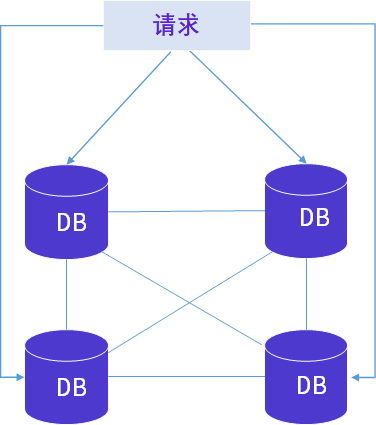
如上图,具体而言,在无中心架构下,整个数据库系统没有一个中心节点,集群中每个节点都是平等的,每个节点都可以向其他节点发送或接收信息,独立处理和存储数据,并通过节点之间的协调和通信完成整个系统的任务。该架构系统具备高可扩展性、可靠性、安全性和易运维,避免传统的单点故障问题,这也是柏睿数据大数据平台Rapids Lizard采用无中心分布式架构的重要原因。
柏睿数据大数据平台Rapids Lizard是集成数据采集、存储、计算分析、治理与可视化的实时大数据平台与解决方案,拥有开源架构数十倍的性能优势,基于低代码、全流程、模块化的方式,为企业提供一站式数据资产管理和大数据智能应用与服务。

为打造平台化一体化产品,集成数据存储平台、数据计算平台、数据应用平台等子平台,以及子平台内部的多个功能项,柏睿数据Rapids Lizard采用无中心分布式架构构建湖仓一体化解决方案,支撑大规模数据存储,解决数据表的分布式读写存放,满足高并发、大规模的计算查询等大数据应用场景需求。
二、Rapids Lizard无中心架构优势
柏睿数据大数据平台Rapids Lizard采用无中心架构,具备以下核心优势:
高可扩展性:根据实际需求支持集群动态扩容缩容,集群扩展几乎是无限制的。同时整体集群可达到查询性能高于开源Spark数十倍。
高可靠性:使用分区键进行Hash分区实现数据在不同数据节点中的均衡负载,当某个节点发生故障时,其他节点仍然工作,从而保证了系统的可靠性;同时多节点数据备份不会导致整个系统的数据丢失或不可用。
高安全性:每个节点都具有相同的权限和责任,因此不存在单点故障和单点攻击的问题。分布式散列算法分配数据和任务,保证数据的最终一致性、安全性和完整性。
易于维护和升级:集群角色统一化,用户能够单独对每个节点进行维护和升级,过程不会影响整个系统的运行,大大降低维护者运维的复杂性。同时,通过自动化部署和管理,减少了人力和物力成本。
三、Rapids Lizard无中心架构原理与实践
柏睿大数据平台 Rapids Lizard 以松耦合多层级架构,其主要核心模块由数据存储、数据计算分析和任务调度系统组成,下面将逐步介绍Rapids Lizard在这三大核心模块中如何实现统一的无中心架构。
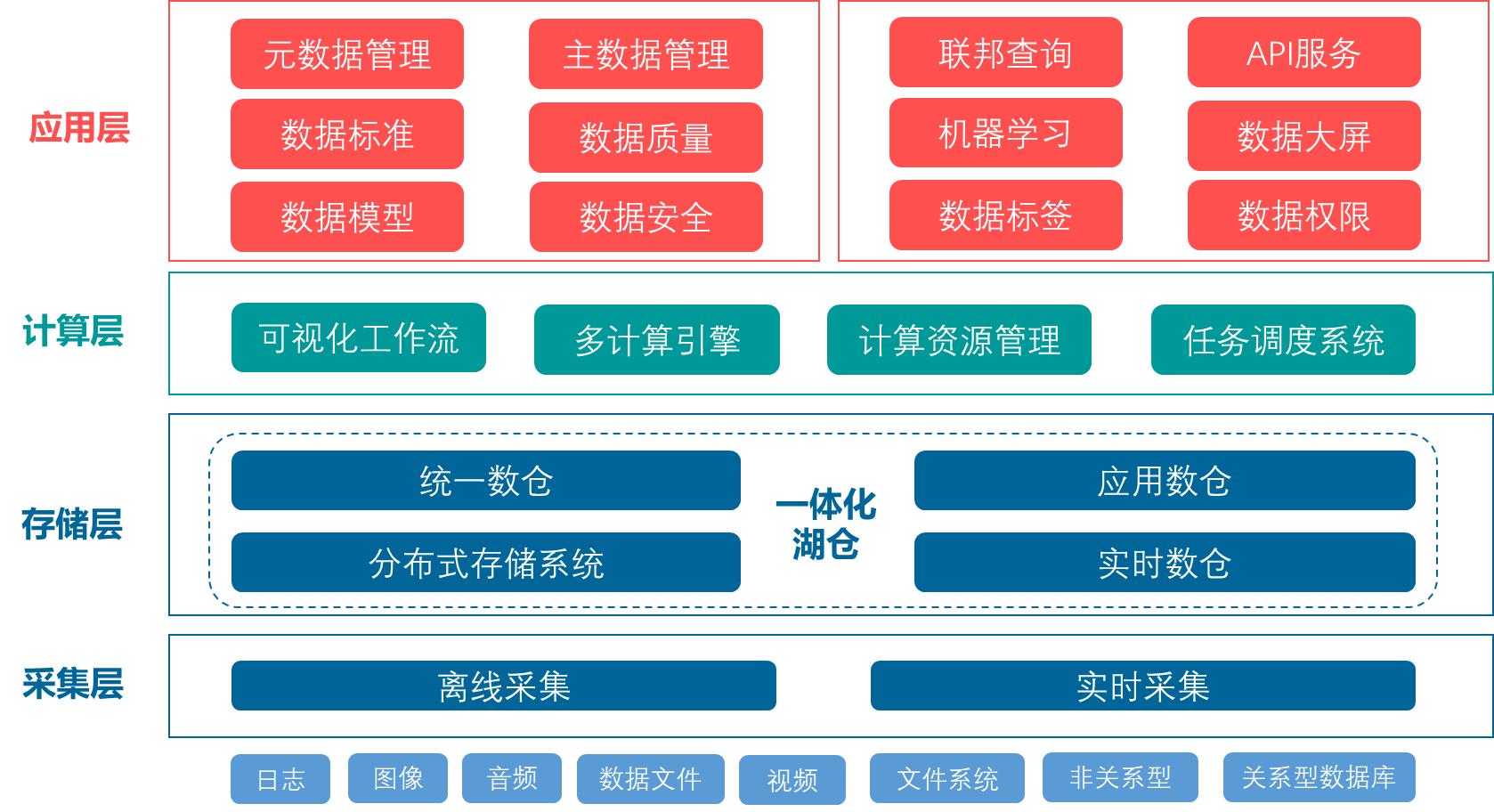
1、数据存储

Rapids Lizard 基于分布式、无中心架构设计的柏睿存储管理系统Rapids Store作为底座,满足支持海量存储容量管理,为用户提供高性能的稳定网络存储。
存储客户端能够同时从所有存储节点读写数据,大大提升了数据读写速度与可用性。
多副本技术保障数据文件的可靠性。Rapids Store将每份数据分成多份,每份数据同时写入多个主机的不同磁盘中,当某个磁盘或主机出现故障时,存储客户端还能从其他副本中正常读写数据。
支持故障域自治,自动迁移故障数据、恢复平衡数据。
Rapids Store为虚拟机提供磁盘快照功能,通过快照方式快速保存虚拟机磁盘中的重要文件、程序配置信息等。
内部集成KVE虚拟化计算和RapidStore功能。集群的物理节点可以同时用于计算(运行虚拟机和容器)和多副本存储;因此传统的计算资源和存储资源管理功能可以由统一的超融合应用实现,无需再部署专用存储网络设备(SANs)和网络存储设备(NAS)。
2、数据计算分析
Rapids Lizard 基于柏睿数据全内存分布式数据库RapidsDB作为计算分析引擎,满足PB级别数据存储和在线实时分析;采用分布式计算与存储分离架构,支持集群动态扩容缩容。

其基本原理包括:
数据分片:将整个数据集按照某种规则划分成多个片段,然后将这些片段存储在不同的节点上;能够解决单一节点存储数据量过大,导致性能下降和可扩展性受限的问题。

数据复制:为了保证数据的可靠性和容错性,RapidsDB支持内部HA模式,即数据会复制到多个节点上。主要支持成对模式和负载均衡模式。
数据一致性:RapidsDB基于CAP原理满足数据最终一致性。对于在内存中的数据,支持以事务日志和快照的方式,保障数据一致性。
负载均衡:为避免节点之间出现负载不均衡的情况,RapidsDB采用基于算法的负载均衡策略进行资源和任务的调度。
分布式计算:把需要进行大量计算的工程数据划分为多个小任务,由各个数据节点进行独立计算处理,各个节点基于通讯协议保障任务正确执行和结果正确,并合并得到最终结果。Rapids Lizard作为开放性大数据平台,除了自研计算引擎RapidsDB外,兼容Spark、Flink等分布式计算引擎。
故障恢复:RapidsDB支持主备集群切换、集群内HA数据复制、数据备份恢复等策略,应对节点之间通信和协调出现延迟、丢包及节点本身故障等问题。
安全机制:RapidsDB支持常见的安全措施,包括数据权限、身份验证、访问控制等,来保障数据的安全性。
3、任务调度
Rapids Lizard的任务调度部分由Rapids Schedulis负责,它基于去中心化架构,是一个分布式易扩展的可视化工作流任务调度平台。以可视化DAG工作流、任务调度、资源管理等功能,致力于解决Rapids Lizard平台中的复杂数据处理和计算资源分配问题。
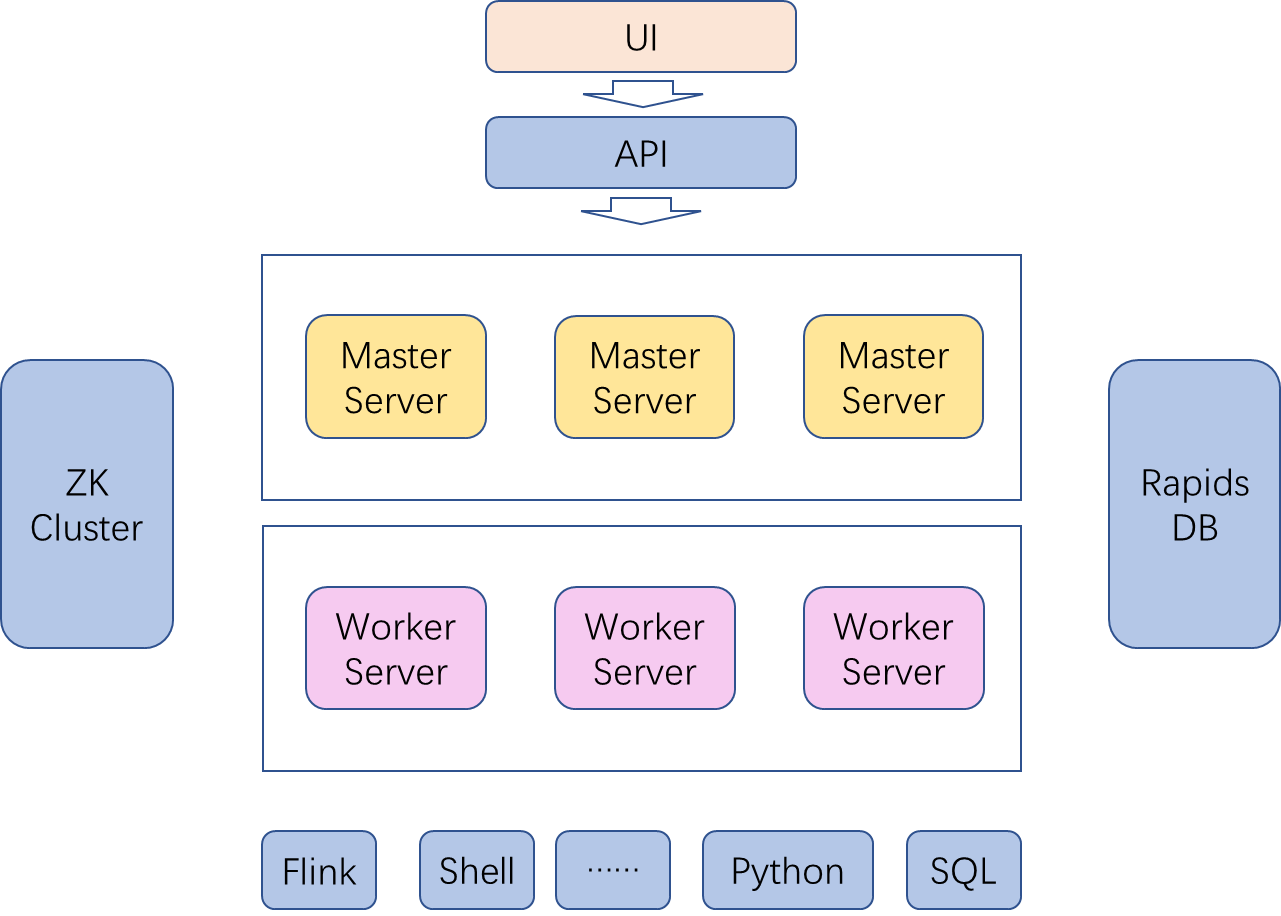
其具体组件包括:
MasterServer:主要负责DAG任务切分、任务提交,以及检测健康状态
WorkferServer:支持定义任务插件,负责任务执行和日志服务
RapidsDB:工作流元数据管理、告警相关功能支持
API:处理前端UI请求。提供统一RESTFUL API服务
UI:系统前端页面
四、应用场景与收益
采用柏睿大数据平台Rapids Lizard基于无中心分布式架构,具备了横向扩展能力、高数据负载均衡性、低运维成本、低延迟和高吞吐量等优势,能够更好地应对实时数据处理要求。
因此,Rapids Lizard适用于金融、运营商、交通等行业中数据量大、安全性要求高的业务场景中,以及智能短信、抢购秒杀等对实时性能和并发性能要求高的实时分析场景中,同时非常有利于在云上提供高性价比的服务,让企业的大数据应用更高效、更安全、更简便灵活、更高性价比,加速实现数字化运营,驱动业务增长和创新。
某地市轨道交通公司依托柏睿大数据平台Rapids Lizard,搭建了基于无中心分布式架构的智慧交通大数据平台,充分解决了用户数据量大且多元化及应用架构复杂化带来的性能瓶颈、数据安全等问题,同时实现了平台长期安全稳定的运转,不仅在日程使用过程中,实现了存储、计算资源的统一负载管理,还在运维管理中满足了数据多副本、数据多种形式备份、数据分区容错等要求。
五、未来展望
柏睿大数据平台Rapids Lizard的无中心架构演变遵循技术和市场的发展趋势,将朝着更加高性能、智能化、安全可靠、灵活的方向发展,以满足数字经济时代下大规模数据的实时采集、存储、计算分析、治理与可视化需求。
Rapids Lizard的无中心架构重点关注以下技术发展方向:
智能化管理:Rapids Lizard的原生AI机器学习模块AIworkflow通过对平台内部数据的建模分析,能够实现自动化的节点管理和控制,提高系统的可靠性和效率,还能够对用户系统进行预防性设备检测和运维处理。未来Rapids Lizard将更深层运用机器学习和人工智能技术,实现平台的智能化管理。
更加灵活的数据分片:未来的无中心架构将会采用更加灵活的数据分片方式,以适应数据的动态变化和多样化的数据访问需求。例如,可以使用动态数据分片技术来自适应数据的变化,并根据数据的重要性和访问频率进行优化。
更智能的故障恢复机制:未来的无中心架构可能会使用更加智能的故障恢复机制来提高系统的可用性和稳定性。例如,可以使用自动化故障检测和恢复技术来快速发现故障并自动化修复。
超大规模数据处理:目前Rapids Lizard能够满足PB级别海量数据的稳定存储和高效分析,未来也会向着超大规模的平台集群演进。
云原生应用:无中心架构具备适应云原生应用的独特优势,支持快速部署和扩展应用程序,未来Rapids Lizard将同时满足本地化部署和云原生,以适应用户灵活多变的交付需求。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















