
制造业是一个古老而悠久的行业,它的起源最早可追溯到石器时代。从新石器时代简单的工具,到今天复杂的智能工厂,制造业历经千年发展,蜕变成了由技术驱动的创新行业,充满各种自动化流程、始终互连的设备和数据丰富的流程。
“离散型”制造业面临数据挑战
在制造业中,通常有着“流程型”和“离散型”两种区分。“流程型”是指被加工对象不间断地通过生产设备,通过一系列的加工装置使原材料进行化学或物理变化,最终得到产品。典型的流程生产制造业有医药、化工、石油化工、电力、钢铁制造、能源、水泥等领域。“离散型”制造,则是指材料的生产过程通常被分解为多项加工任务。典型的离散制造行业主要包括机械制造、电子电器、航空制造、汽车制造等行业。
在整个离散制造业的现场有着太多的生产、物料、工艺以及人员数据。以前,离散制造业往往只能通过人工上报、手动填单等方式来进行数据收集。对于管理层而言,这些数据往往是不透明的、不准确的,或是滞后延迟的。离散制造企业本身从业务到管理,都亟需通过数字化进行优化和提升。
如何解决“离散型”制造业的数据挑战?
工业数字化软件供应商数益工联,致力于打造基于“数据流+价值流”的离散制造业数字化软件。数益工联团队以IE+IT为核心能力,实现产品和技术的双轮驱动,已在十多个行业落成全球领先的数字标杆工厂公司。公司至今已获得华创资本、高瓴创投、元生资本等知名机构的风险投资,累计融资额数亿元,在上海、苏州、广州三地设有子公司,打造跨区域全国服务平台。
数益工联数字工厂系统(DFS,Digital Factory System)应用新一代的物联网技术与丰富的现场交互手段,获取工厂现场最实时、最真实、最有效的数据,不仅包含设备状态、设备异常数据、设备生产数据等设备 IOT 数据,还包含人员的交互使用数据,如计划报工、工艺、仓储物流、质检等核心生产管理业务的数据等。对管理层而言,通过数益工联数字工厂系统,可以直观看到清晰、直接的报表,从中发现数据的价值,继而深入分析并采取行动,优化制造现场。
数益工联数字化工厂架构面临的挑战

数益工联数字化工厂架构图
从架构上看,数益工联数字化工厂主要分为四层:
第一层为物联层,包括硬件和软件两部分。硬件主要为数益工联自研的智能终端,软件包括边缘应用和物联平台。其中应用主要具备设备参数的采集、人脸识别等功能,以上应用均运行于智能终端。物联平台则主要承担设备管理、配置和升级的相关工作。
第二层为应用层,包括 IOT 数据服务、核心服务、低代码平台。IOT 数据服务是接受物联上报数据,计算设备开机率,异常等设备相关的服务,同时也是其他业务的数据源头;核心服务包括了计划报工、质量等数字化工厂服务;低代码平台主要包括了报表的可视化平台、流程编排等功能。
第三层为大数据层,分成了大数据和算法两个部分。大数据应用包括了成本控制、APS、工艺大数据;算法包括了人脸识别、时序分析等算法。
第四层为基础架构层,作为基础设施提供其他业务使用。主要包括了存储、数据库、中间件和云原生等部分。
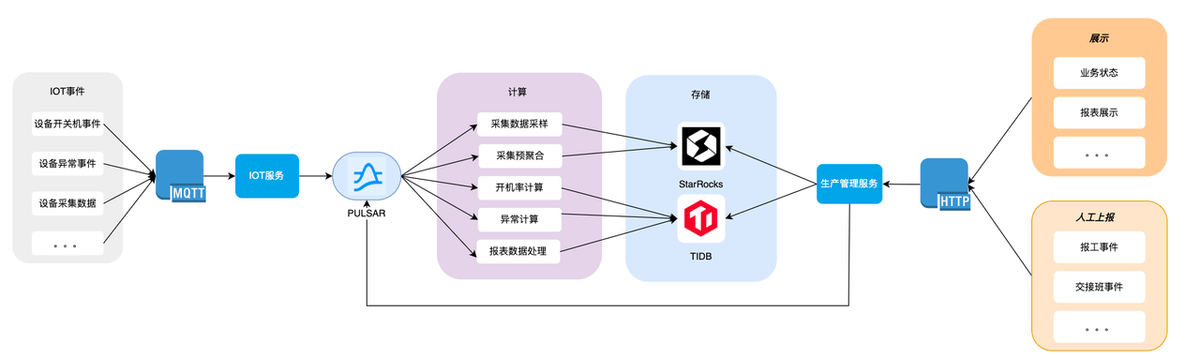
数字工厂的数据源头主要包括两部分:
第一部分是 IOT 事件,包括了设备的开关机,物联采集、异常等数据,这部分数据通过 mqtt 上传到 IOT 服务进行处理,同时会推送到队列中,方便后续的计算和存储;
另一部分是业务产生的数据,包括了计划报工、上下班等产生业务数据,主要通过 http 进行上传和展示。业务数据会直接存放到数据库中,同时将数据推送到队列中。
数据存储主要采用了 TiDB 和 Starrocks 两个数据库,除了时序相关的数据,业务数据都存放在了 TiDB 中。
随着数益工联业务规模的不断增长,数据量变得愈发庞大,对于数据库的稳定性也提出了更高的要求:
1、多数业务数据需要支持秒级延时,因此需要数据库具有很高的并发能力;随着业务的增长,数据量也会越来越大,需要数据库具有良好的拓展性;
2、随着数据量的增大,报表制作成本和难度变大,无法保证实时性。
为解决业务系统的性能瓶颈,提高数据库的性能问题,数益工联选择了 TiDB 这一新型分布式数据库实现重构。
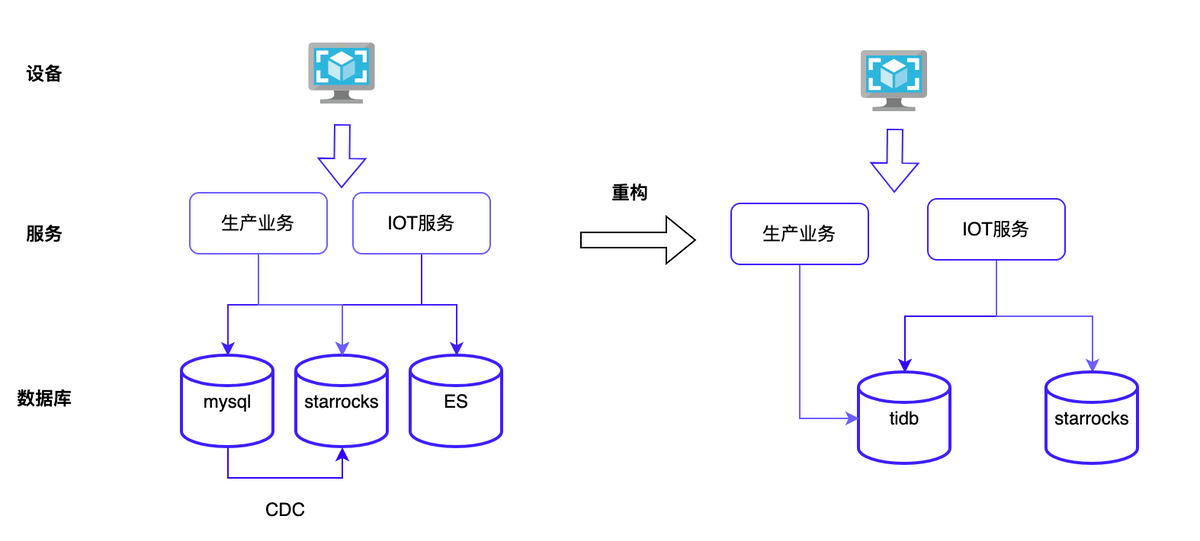
数益工联研发团队在实践过程发现,TiDB 许多优势正好可以满足数益工联的需求:
TiDB 兼容性强,在实践的过程中几乎没有遇到过不兼容的问题,除了少数默认编码的问题。
支持云原生部署,可以通过 Kubernetes operator 来快速部署TiDB集群,具有完善的配套监控功能。
能够实现自动化水平扩容,支持高可用,运维无需手动接入,极大地降低了运维成本。
支持 AP,TiDB 支持 TiFlash,降低部署复杂度,TiFlash 在亿级别数据的查询中,通常能达到 5 倍的加速。
TiDB如何助力数益工联挖掘价值数据?
那么,数益研发团队是如何使用 TiDB 实现对于工业数据的价值挖掘的?以工厂运转效率的重要指标设备开机率为例,对于工厂而言,设备的开机率与生产效率息息相关,能否实时获取开机率,机器是否实现了高效且合理的运转非常重要。数益工联团队通过 TiDB 实现了以下功能:

开关机记录:一条开机记录表示记录单个设备的一次开机时间和关机时间。这种记录表,由于数据量过大,现在主要放在ES中。
开机率:表示在一段时间内的开机时间的占比,延时需要精确到秒级,这种数据现在转换成时序的数据存放在 Starrocks,同时创建物化视图,加速时间跨度大的查询。
但随着时间增长,团队也遇到了以下问题:一是开机记录和开机率数据不同源,导致数据容易不一致;二是Starrocks 存储量大,占用了大量的计算和存储资源。
因此,数益工联数据团队对于开机率进行了第三次改造:Starrocks 不再保存开机率的时序数据。时序数据量比较大,容易出现异常,导致数据不一致。数益工联一方面将开机记录存放在 TiDB 中;另一方面通过开机记录来计算出开机率。
原先 ES 同步写入容易引发业务写入超时的问题,这次改造解决了 ES 数据写入延时的问题,同时,也减少了 Starrocks 的存储资源的占用。这次改造使得在在100 台设备的应用场景中,一年能减少百 GB 级别的Starrocks 存储;充分利用了 TiDB 的 HTAP 能力,通过 TiDB 的 HTAP 直接对开机记录进行聚合查询,降低了业务复杂度,给业务开发提供了很大的便利性。目前,TiDB 在线上运行表现十分稳定。
改造 TiFlash,实现 TiDB 物化功能
与此同时,数益工联研发团队也在进行一些定制化的改造。由于业务需要支持任意时间段查询开机率的能力,因此需要按天对数据进行预聚合,但TiDB 不支持物化能力,需要借助业务逻辑来实现,加大了业务实现复杂度。随着业务预聚合的需求越来越多,数益工联研发团队决定对 TiFlash 进行改造,实现 TiDB 物化功能:
1、每个基表根据物化语句生成物化表。
2、基表以分区为粒度进行聚合,当数据到达一定时间的策略的时候,会把整个分区进行聚合,放到物化表分区中。
3、查询引擎自动判断是否使用基表分区还是物化分区。
4、在和Tiflash团队的交流中发现,需要解决重复计算的问题,因此数据需要多副本去重计算。
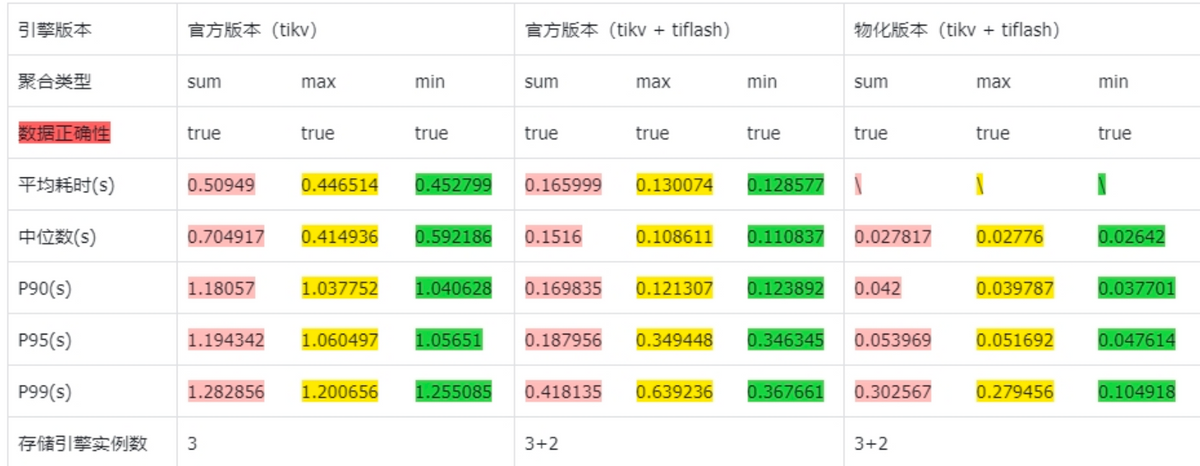
目前,在数益初步的单副本测试中,虽然还存在一些问题需要修复,但能看到 TiFlash 的物化功能展现了很大的潜力,相信将在未来多业务场景下发挥重要作用。
数据库在制造业中扮演着至关重要的角色,它们为工厂提供了强大的信息管理能力,帮助工厂更好地挖掘数据的价值。TiDB 可以帮助制造业处理海量数据,提供高效的查询性能,我们也期待帮助更多制造业用户完成数字化转型,从而提升企业的竞争力与效率。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















