
近年来,新一代硬件产品不断蓬勃发展,如多核CPU、GPU、FPGA,以及XPU,如TPU(Tensor Processing Unit,张量处理单元)等。以TPU为例,它可以在硬件层面上处理人工智能和机器学习经常涉及的张量数据结构和张量相关的计算,这大大提高了数据处理和计算的效率。
此外,新一代硬件的革新也在推动数据库系统和架构发生变化,数据库系统作为硬件和企业需求之间的纽带,需要通过巧妙精细的架构把硬件的能力和特性充分发挥出来,更好地满足企业存储和分析数据的需求。

因此,在新一代硬件的基础上,柏睿数据从数据库系统层面优化,囊括新一代计算平台和引擎,如内存计算、分布式计算、人工智能和机器学习计算、流计算等,构建业界领先的数据智能分析处理平台——RapidsDB,以完全自研的分布式全内存数据库、实时流数据库、数据库人工智能、跨源异构查询连接器、数据库安全&加速卡等为核心,针对海量、高吞吐、高并发、多源异构数据进行实时分析处理,充分利用和发挥新一代硬件的性能,落地数据治理、数据模型分析、数据资产管理、数据追溯等场景应用,携手政府部门和千行百业的企业开展数智化转型。

柏睿数据是如何将内存计算和分布式计算珠联璧合,构建出一个更快、更简单、性价比更高的数据智能分析处理平台?柏睿数据联合创始人、全球副总裁、首席技术官马珺表示,柏睿数据专家团队拥有国际领先的智能数据算力技术,完成了从解析层、优化层、执行层到存储层等全面自主可控的数据库产品体系。柏睿数据完全自主研发的数据智能分析处理平台RapidsDB,从内存计算出发,革新存储介质;通过分布式计算,对架构进行横向扩展,为数据平台带来数据存储与数据处理方面的革新。
内存VS磁盘,从储存到计算、实时分析的巅峰对决
柏睿数据RapidsDB是基于分布式架构的内存数据库。相较于传统数据库用磁盘存储数据,内存数据库直接在内存上进行数据存储和计算。
一、内存数据库避开了数据访问时磁盘的I/O瓶颈,存取速度更快。将内存与磁盘的访问速度对比可知,内存访问速度是纳秒级,而磁盘访问速度是毫秒级,数据处理速度差异高达百万倍。
二、内存数据库能够用压缩和优化的格式来存储数据,从而更好地发挥CPU、GPU等现代硬件,而传统的磁盘数据存储则无法实现。
三、内存数据库中从内存访问数据所使用的内存更少。这是因为从磁盘上读取数据时会涉及诸多复杂操作和过程,而从内存访问数据的过程指令集较少,所使用的内存也较少。
四、除了性能优势外,内存数据库还在一些有趣的领域具有磁盘存储和索引难以实现的优势。例如,列式存储和行式存储,内存数据库能够很容易地在两者之间灵活切换,且可以很容易地实现分层数据模型,甚至矩阵张量数据模型。而对于基于磁盘的存储来说,实现这样复杂的模型是难以想象的。
正因如此,柏睿数据RapidsDB选择基于内存存储架构进行设计和优化,具有无磁盘IO、高可扩展、高吞吐、高并发、低时延、节省内存等特性,比传统数据库性能提高近百倍,分布式架构支持按需动态在线扩展,支持日增20TB数据量实时采集与分析,满足100TB全内存数据量分析500/秒并发,TB级数据毫秒级响,且数据与内存空间的占用比例少于1:2,相较于传统数据库节省内存采购成本60%以上,充分满足企业对海量高并发大数据进行快速、精准智能分析和决策支持的需求。

相较于基于磁盘架构的传统数据库,RapidsDB在内存优化方面有四大显著特性:一、RapidsDB是一个分布式横向扩展系统,可以在普通硬件上扩展到数千台机器;二、没有缓冲池,不易造成资源争用;三、无锁数据结构,使用内存优化的无锁跳过列表作为其索引,允许高吞吐量的高度并发读写,且读取永远不会被阻止;四、代码生成,无锁的数据结构很快导致动态SQL解释成为限制查询执行的瓶颈, RapidsDB可将SQL向下编译为本机代码,以获得最高性能。
此外,RapidsDB虽然使用内存作为数据的主要存储模块,但会通过事务日志和定期快照不断地将数据备份到磁盘,这些特性可以从同步持久性(每个事务在完成之前都记录在磁盘上)一直调整到纯内存持久性(最大持续吞吐量)。同时,RapidsDB提供选项来控制性能和持久性之间的权衡,在其最持久的状态下,RapidsDB不会丢失任何一个已确认的事务。
重塑JOIN,实现更强大的分布式数据库
现代社会日新月异,万事万物数据化生成海量大数据,并在多维时空高速传播。为高效存储、处理、利用好海量大数据,分布式计算逐渐成为众多大数据平台采用的计算方式。原因在于,分布式数据库解决了传统集中式单机数据库面临的存储、处理等性能瓶颈。首先,分布式数据库能够简便的实现横向扩展集群,即通过增加更多的节点综合提升数据处理能力;其次,它能实现成本优化,部署的节点可以根据应用场景需求进行灵活设计;再次,具备高容错率,保证不会因为单点故障而影响整体的可用性。
但是,由于现实世界中数据处理繁杂多样,分布式数据库不能只是简单划分并分配计算任务给每个节点;尤其是作为数据库中最基本、最广泛使用的算子之一的JOIN(表连接),在分布式计算中实现系统节点间的数据交互,而随着分布式集群规模增大,网络数据传输量大增,节点之间的数据交互效率降低,从而导致分布式数据库扩容带来的性价比愈发降低,此时分布式数据库往往需要重新设计JOIN,以实现更优性能,降低部署成本。
面对这一问题,柏睿数据RapidsDB基于BLOOM JOIN(布隆连接)和BLOOM FILTER(布隆过滤器)提出了解决方案。BLOOM JOIN通过在节点集群中连接BLOOM FILTER,能够完成数据筛选、处理、连接工作;借助BLOOM JOIN,分布式数据库能够排除不使用、不必要的大量数据,保留具有查询意义的数据,以达到高效数据交互的目的。
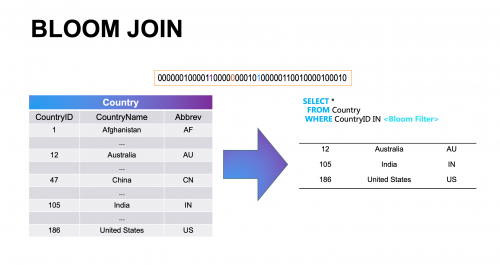
由BLOOM JOIN连接的BLOOM FILTER也被称为概率数据结构,它能够将大型数据压缩进一个非常复杂的数据结构,例如将原本几百个二进制位数据,变成只有一个或几个二进制位数据。因此,BLOOM FILTER比其他数据结构更节省空间,尽管它存在一定的误判,但这并不影响其性能优化目标的实现。

事实上,RapidsDB很早就已经开始部署BLOOM JOIN,然而当前许多数据库系统都还没有部署;即使已经部署了BLOOM JOIN的数据库,其使用方式也比较复杂,会对工作效率造成一定影响。不仅如此,柏睿数据的数据库产品还会智能地使用BLOOM JOIN,即数据库系统会动态探测和优化连接,根据不同的数据需求,自主选择BLOCK JOIN或 HASH JOIN,这也是RapidsDB的智能之处。
知之愈明,则行之愈笃。柏睿数据专家团队厚植数据库“卡脖子”技术,以“做中国的国际智能数据算力公司”为己任,坚持自主创新,以“DATA+AI”技术为核心,致力于打造更快、更简单、更低成本的领先数据智能分析处理平台,助力政企全面释放数据生产力,在数字化转型的道路上行稳致远,加快数字经济时代的到来。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















