
近日,人工智能领域顶级国际期刊 IEEE Transactions on Pattern Analysis and Machine Intelligence(IEEE TPAMI,影响因子24.314)再次接收了火山语音团队有关机器学习的技术研究成果,即“基于自适应迁移核函数的迁移高斯回归模型”( ADATPITVE TRANSFER KERNEL LEARNING FOR TRANSFER GAUSSIAN PROCESS REGRESSION)(链接:https://ieeexplore.ieee.org/abstract/document/9937157)。

该成果主要针对迁移学习在低资源回归问题中的应用做了创新性基础理论研究,具体包括以下几个方面:
给出了迁移核函数的正式数学定义。
提出了三种广义形式的迁移核函数,而且现有的迁移核函数均可归纳为这三种广义形式的特例。
提出了两种改进的迁移核函数,即线性积式核函数与多项式积式核函数,并验证了在迁移学习中的有效性:一方面展示了迁移效果优劣与域相关性的必然关联;另一方面验证了模型可以高效提升迁移效果的情况。
背景介绍
一直以来,高斯过程回归模型(Gaussian process regression model, i.e., GP)作为一类基础的贝叶斯机器学习模型,在工程与统计等领域的回归问题中有着广泛应用。传统的高斯过程回归模型需要大量有监督数据进行训练才可发挥好的效果,但在具体实践中,收集和标记数据是一项昂贵且费时的工程。
相比之下,迁移高斯过程回归模型(Transfer GP)能够高效利用不同领域(domain)的数据来降低标记成本,主要通过设计迁移核函数(Transfer Kernel)来实现不同领域之间的数据迁移,通过引入域信息来建模域相关性,从而自适应调控数据迁移强度,使异源数据应用更加高效。
尽管在不同的领域(如计算工程学,地质统计学,自然语言处理)都有迁移核函数的身影,迁移核函数并没有一个正式的数学定义。基于此,该论文首先提出了正式的迁移核函数数学定义,并总结了三种广义形式的迁移核函数。
基于广义形式,本文展示了已有的迁移核函数为广义形式的一种特例,并讨论了其优缺点。更进一步,文章提出了两种改进的迁移核函数,即线性积式核函数与多项式积式核函数,旨在提高数据表征能力和域相关性的建模能力:具体来说理论证明了如何建模域相关性以确保提出的迁移核函数满足核函数(kernel)的基本要求(半正定性),并讨论了不同域相关性对应的迁移场景;更重要的还展示了改进的迁移核函数可以无缝应用到迁移高斯过程回归模型中,而不带来额外的计算负担,并在一些低资源回归场景下有效提升迁移效果。
原理阐释
本文的核心贡献之一是提出了如下迁移核函数的正式定义:

基于上述定义,火山语音团队进一步提出了三种广义形式的迁移核函数,分别为链式广义核函数和式广义核函数以及积式广义核函数,而三种广义形式分别对应三种不同地处理域信息的方式。
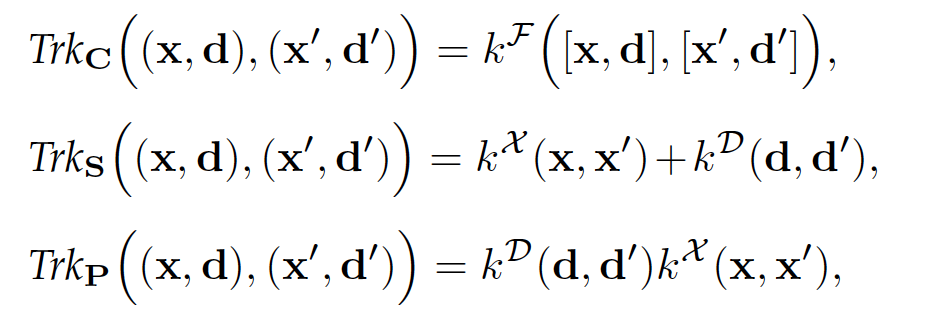
现有广泛应用的一类迁移核函数,属于积式广义核函数的一种特例。
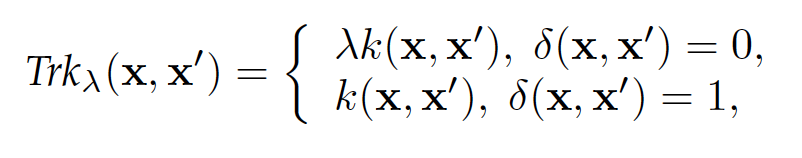

的一个重要局限在于其只用一个简单的参数化系数去建模域相关性,这对于复杂异构的数据,在表征能力上远远不足,所以首先提出了改进的线形积式核函数,形式如下:

可以看出,用两组基础核函数的线形组合来区别域内与域间的计算。这两组线形组合有着不同的线形系数,,而两组系数的比值代表了source 和 target 在基础核函数 上的域相关性。通过应用丰富的基础核函数,可以表征更加复杂细腻的域相关性。
接下来的挑战在于设计的在符合上述形式的同时,还需满足核函数的基本要求,即半正定性(Postive Semi-definite),所以给出了如下定理:

从定理1可以看出,要满足半正定性,中的线性系数应满足 ,即域间系数的值永远小于等于域内系数的值。其潜在含义是域内系数代表了在 上数据迁移的上限能力,因此域间系数不能超过域内系数。
更具体来说,若,则代表source和target在上完全不相关,则不进行迁移;若, 则代表source和target在上完全相关,则进行全量迁移;若,则代表source和target在上部分相关,则进行部分迁移。
虽然提高了的表征能力,但仍然不能表征非线性的情况。因此本文进一步提出了多项式积式核函数,形式如下:
其中,
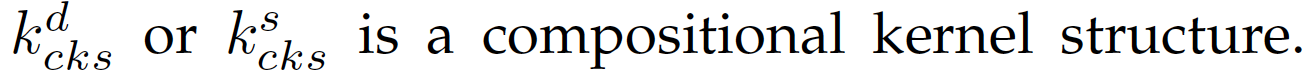
上述数学形式较为抽象,因此展示如下图形化结构:

可以看出,用两个基础核函数深度网络来区别域内与域间的计算,每个基础核函数深度网络由线形层与乘积层交替组成,例如上述例子中包括三层线形层和两层乘积层;线形层的每个节点为上一层的输出的线形组合,乘积层的每个节点为上一层相邻输出的乘积;每层线形层包含域内与域间两组线形系数,而乘积层不包含可学习的参数。
更进一步,可以展开每个深度网络,从而得到如下形式的:
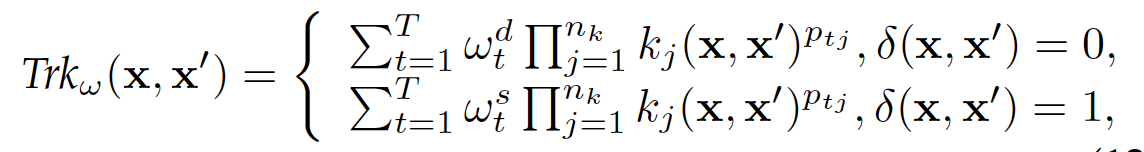
可以发现,是的一种高阶形式,即用基础核函数的多项式形式为新的基础核函数,从而引入非线性。此外根据定理1,就可以很容易得到如下推论,从而保证的半正定性。

实验验证
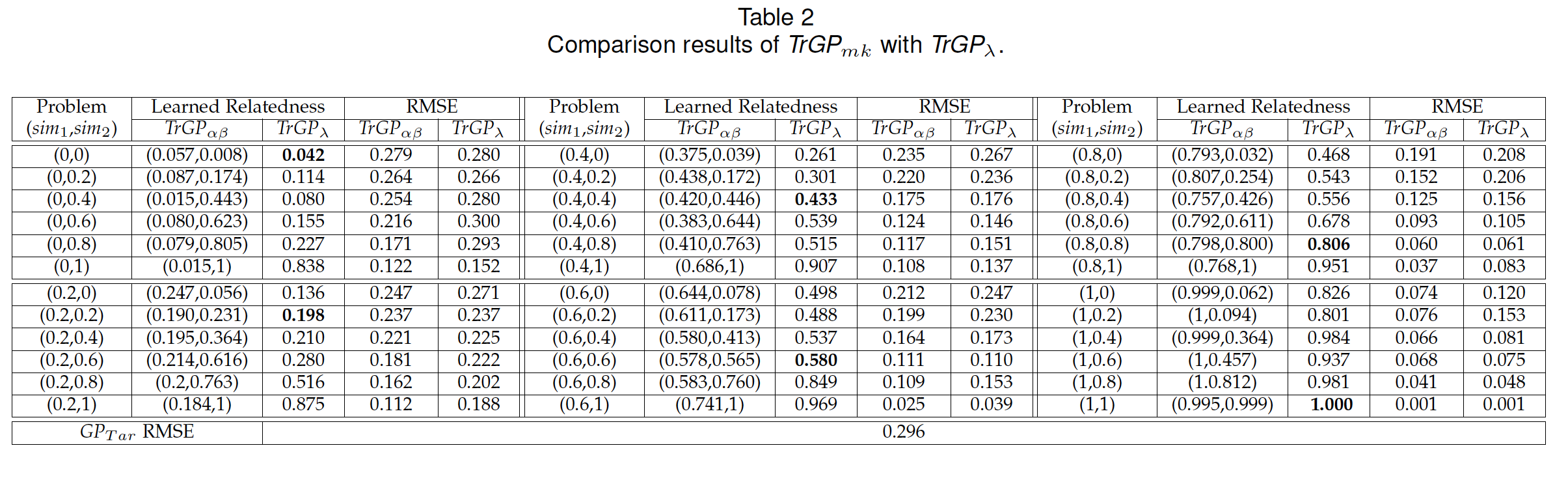
除了理论推导之外,文章还展示了丰富的实验验证。“我们首先验证了与准确学习不同领域相关性的能力。可以看出模型能够很好学习到两个领域之间的相关性,同时还能取得更好的迁移效果, 即更小的均方根差。”火山语音团队表示。
另外团队还研究了不同模型在时间序列外推任务下的迁移效果,即根据有限的目标数据和丰富的源数据对后续时序目标数据的拟合能力,可以看出模型在迁移效果上要远远优于其他模型。

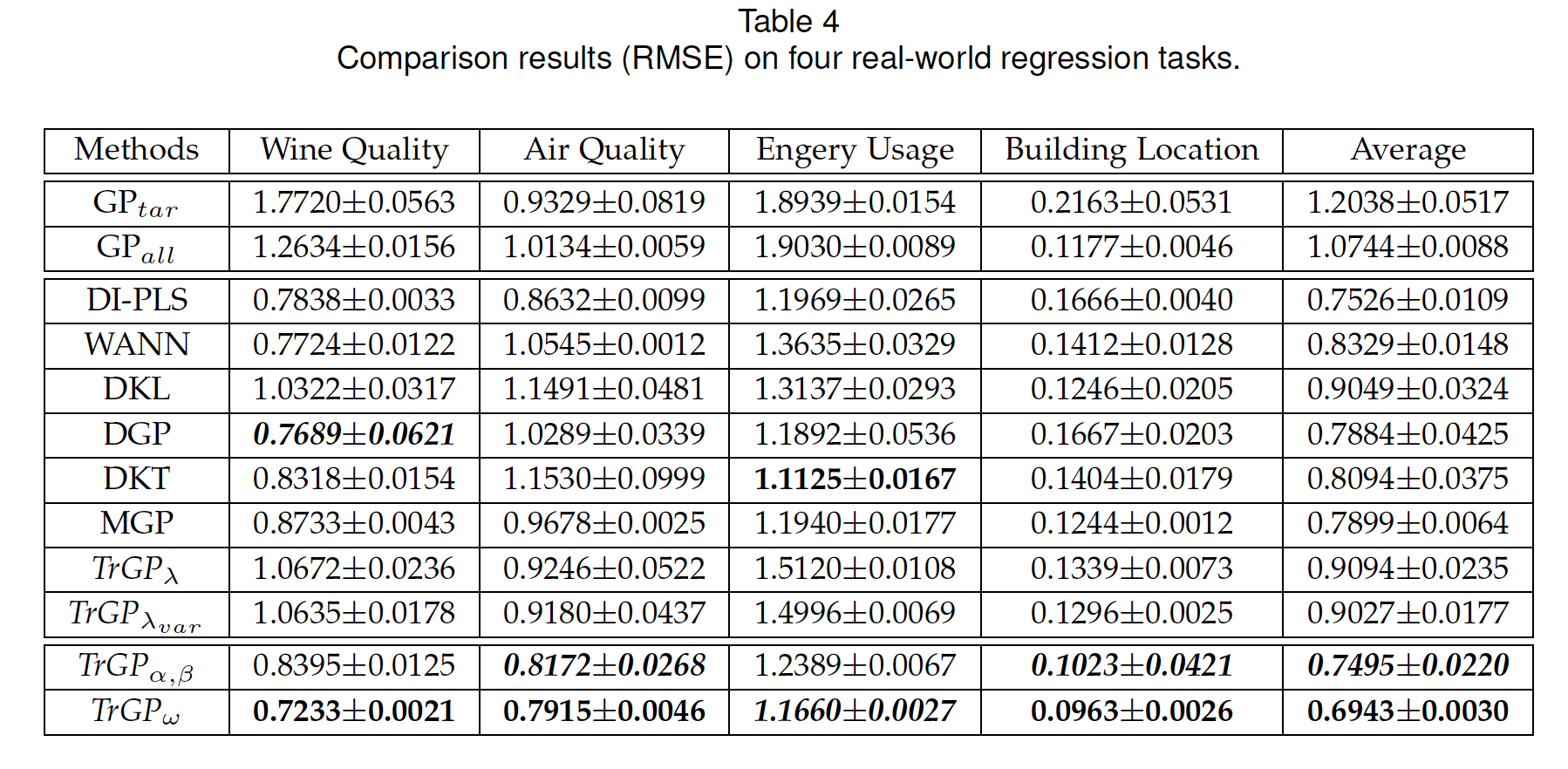
最后,团队还在四个现实数据集中对模型进行了验证。与8个SOTA方法相比,模型在不同的迁移回归任务中都取得了更好的迁移效果,即更小的均方根差。
火山语音,字节跳动 AI Lab Speech & Audio 智能语音与音频团队,长期以来面向字节跳动内部各业务线提供优质的语音AI技术能力以及全栈语音产品解决方案。目前团队的语音识别和语音合成覆盖了多种语言和方言,多篇论文入选各类AI 顶级会议,技术能力已成功应用到抖音、剪映、番茄小说等多款产品上,并通过火山引擎开放给外部企业。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















