

追求卓越
打造极致文化与产品研发结合的最佳实践
神策已启动「卓越产品计划」
产品功能、性能、稳定性不断迈向新台阶
在上一篇文章《卓越产品计划丨神策分析之五重性能优化》中,我们了解了神策分析性能优化的的五重实践,主要包括批量导入性能优化、智能聚合表优化、数据重组织查询优化、查询去重优化、页面首次首屏加载时间优化。今天我们将重点讲述数据重组织查询优化。
在过去 7 年多的发展过程中,我们基于 Apache Impala 做了大量的二次开发,极大地优化了 Apache Impala 的查询性能。经过不断地探索与实践,我们开发的一些基于数据组织的性能优化效果显著,其中 shuffle merge 是其中重要的一项优化。
如下图所示,神策分析中,Event 数据按天和 EventBucket 做分区,即同一天的数据置于同一一级分区内,同一天的数据再按 EventBucket 分区,这样可以保证同一事件的数据在同一分区内,同时将分区内的文件按{User_id, Time}排序。

神策分析的 10+ 分析模型,大多基于按时间排序的用户事件序列进行分析,对该功能的性能优化,可以有效提升查询性能。
一、相关名词解读
在进行数据重组织查询优化的过程中,经常会提及不少名词,你都了解吗?为了帮助各位阅读,我们提取了常见的 5 个名词并做了详细解释。
1、数据模型
指神策分析中的事件模型。简单来说,事件模型包括事件(Event)和用户(User)两个核心实体,同时配合物品(Item)实体可以做各种维度分析。
2、数据组织
指按照一定的方式和规则来存储模型数据,比如数据如何做分区、如何建索引等。
3、数据重组织
对应数据组织,针对不合理的数据存储,重新组织模型数据,以提升数据的使用效率。
4、EventBucket
每个事件都有唯一的 Event_id, EventBucket 是对 Event_id 的分桶,在数据组织上,会将 Event 均匀地存放在 EventBucket 中,当前 EventBucket 默认为 10。
5、SamplingGroup
是对 User_id 的虚拟分桶。在数据重组织中, 会尽可能地将同一 User_id 的数据存放在同一 SamplingGroup 下,当前 SamplingGroup 默认为 64。
二、shuffle merge 原理
通常,exchange 算子后会接一个 sort 算子将数据按{User_id, Time}来排序,此时的排序为全排序,未利用底层数据的有序性,复杂度比较高,代价较大。shuffle merge 则可以充分利用底层数据的有序性,将全排序转化为归并排序,跳过耗时的 sort 算子,降低排序的时间复杂度,加速计算过程。
其优化前后的查询计划分别如下:
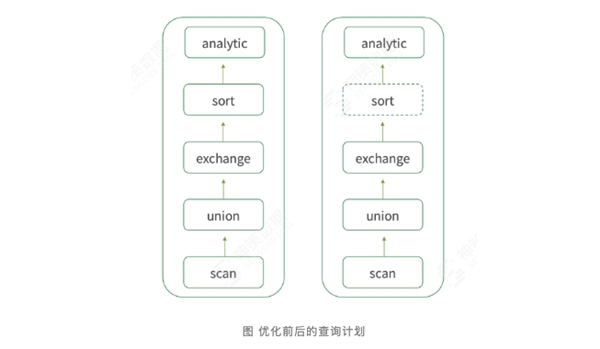
最终,基于此优化,我们可以实现如下逻辑的查询:
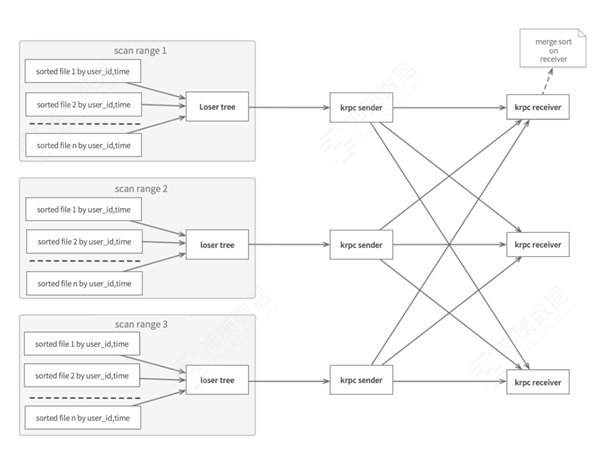
三、神策的数据重组织查询优化实践
在 shuffle merge 的实际应用中,对于数据量较大的客户,其分区内文件数量较多,再加上客户数据或存在延迟上报的情况,会形成比较多的小文件,进一步增加单分区内的文件数量,造成了以下问题:
● 同一分区内同一 User_id 的数据分散在不同的文件里,在 shuffle 时需要一次打开多个文件,每个文件仅读一部分,带来大量的随机 IO。因为同一 User_id 的数据分散在不同的文件里,在多读取不同的 User_id 序列时,会存在同一文件多次读取的情况,IO 会成倍放大
● 同一 User_id 的数据分散在不同的文件里,导致归并排序时归并路数过多,维护败者树的代价过高。单个文件读取较慢则会阻塞整个查询进程
为了减少上述问题带来的影响,我们需要尽可能地将同一分区下同一 User_id 的数据存放于同一文件中,这样可以明显减少归并路数,进而降低随机 IO,提升数据扫描性能。针对此,我们设计了虚拟分桶 SamplingGroup,它是 User_id 的 hash 值。在数据重组织具体应用过程中,将同一 SamplingGroup 的数据组织到同一文件中。重组织后的 Event 数据组织形式如下:

当数据量较大,且归并路数较多时,遇到慢文件的概率大大提升,很容易拖慢整体的 shuffle merge 速度;另外,在数据规整后,shuffle merge 的归并是按 SamplingGroup 串行执行的,未能充分利用 SamplingGroup 以提升并行度。针对此,我们提出了 merge all 的方案——将归并从 union 算子下移到 scan 阶段,直接桶对桶(SamplingGroup to SamplingGroup)做归并,如下图所示:
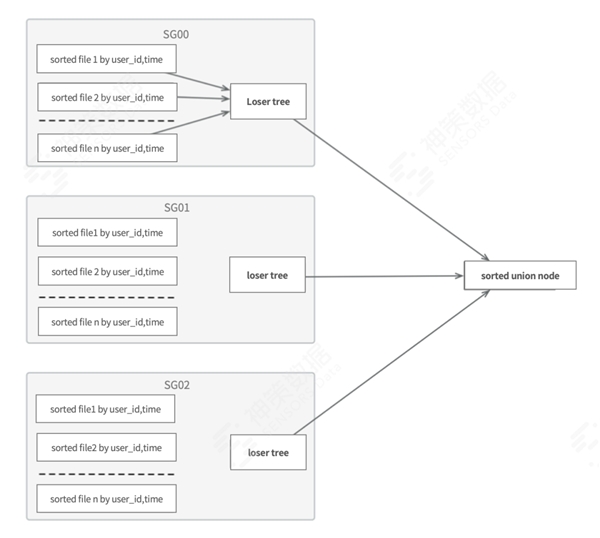
该方案能够直接在计算节点上,通过 hdfs api 对时间线上的同一 SamplingGroup 数据做归并,大大节省了网络间 shuffle 的数据量;更容易将谓词及列裁剪下推到 scan 阶段,以进一步减少数据扫描量;充分利用 hdfs api 的读优化功能,以提升 scan 效率;在计算节点较少或者内存不充足的情况下,可主动控制归并数量,按 SamplingGroup 分批归并,以降低计算所需内存。
另外,在和 profile 表做联合 join 时,可以采用 sort merge bucket join,进一步提升 join 效率,在 profile 表较大和内存资源有限的情况下发挥较大作用。
数据重组织查询优化后,神策数据帮助某客户实现了 shuffle merge 场景下 1 倍左右的性能提升,开启 merge all 后,其漏斗分析场景中的性能提升高达 40%~150%。
关注神策数据公众号,了解更多产品技术解读。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















