
2022年5月26日 安德烈·佩奇库罗夫 QuestDB工程师
QuestDB 6.2是我们之前的次要版本,它为SQL过滤器引入了JIT(实时)编译器。正如我们上次提到的,下一步将是在适当的时候并行化查询执行,以进一步提高执行时间,这就是我们今天要讨论和测试的内容。QuestDB 6.3默认启用JIT编译的过滤器,更值得注意的是,它还包括并行SQL过滤器执行优化,允许我们大大减少冷查询和热查询执行时间。
在深入研究实现细节并为QuestDB运行一些前后基准测试之前,我们将与两个流行的时间序列和分析数据库TimescaleDB和ClickHouse进行友好的竞争。本次竞赛的目的仅仅是试图了解我们的并行过滤器执行是否值真的有效。

安德烈·佩奇库罗夫 QuestDB工程师
一、与其他数据库比较
我们的测试箱是c5a.12xlarge AWS VM运行Ubuntu服务器20.04 64位。实际上,这意味着48个vCPU和96 GB RAM。连接的存储是一个1 TB gp3卷,配置为1000 MB/s吞吐量和16000 IOPS。除此之外,我们将使用QuestDB 6.3.1和默认设置,这意味着同时启用并行过滤器执行和JIT编译。
为了使基准测试易于再现,我们将使用TSBS基准测试实用程序来生成数据。我们将使用所谓的物联网用例:
/tsbs_generate_data --use-case="iot"
--seed=123
--scale=5000
--timestamp-start="2020-01-01T00:00:00Z"
--timestamp-end="2020-07-01T00:00:00Z"
--log-interval="60s"
--format="influx" > /tmp/data
/
上述命令为5000辆卡车物联网设备生成六个月的每分钟测量值。这将产生近12亿条记录,存储在名为Reads的表中。
加载数据非常简单:
./tsbs_load_questdb --file /tmp/data
现在,当数据库中有数据时,我们将对Readers表执行以下查询:
Query 1
SELECT *
FROM readings WHERE velocity > 90.0
AND latitude >= 7.75 AND latitude <= 7.80
AND longitude >= 14.90 AND longitude <= 14.95;
这种(类似于合成的)查询旨在查找给定位置快速移动卡车发送的所有测量值。除此之外,它在三个双栏上有一个过滤器,不包括分析子句,如GROUP BY或SAMPLE BY,这正是我们所需要的。
我们的第一个竞争对手是运行在PostgreSQL 14.2之上的TimescaleDB 2.6.0。正如官方安装指南所建议的那样,我们确保运行timescaledb tune来微调timescaledb以获得更好的性能。
我们使用以下命令生成测试数据:
./tsbs_generate_data --use-case="iot"
--seed=123
--scale=5000
--timestamp-start="2020-01-01T00:00:00Z"
--timestamp-end="2020-07-01T00:00:00Z"
--log-interval="60s"
--format="timescaledb" > /tmp/data
/
这与之前的命令相同,但format参数设置为timescaledb。接下来,我们加载数据:
./tsbs_load_timescaledb --pass your_pwd --file /tmp/data
QuestDB和此特定环境中的其他两个数据库。然而,对于任何想重复基准的人来说,这只是一个注释。如果您想了解有关摄入性能主题的更多信息,请查看此博客文章。(https://questdb.io/time-series-benchmark-suite/)
最后,我们可以运行第一个查询并测量热执行时间。然而,如果我们这样做,TimescaleDB执行此查询将需要15分钟以上。此时,有经验的TimescaleDB和PostgreSQL用户可能会建议我们添加一个索引来加速这个具体的查询。那么,让我们这样做:
CREATE INDEX ON readings (velocity, latitude, longitude);
有了索引,TimescaleDB可以在大约4.4秒内更快地执行查询。为了全面了解情况,让我们再加入一名选手。
我们比赛的第三名成员是ClickHouse 22.4.1.752。与TimescaleDB一样,生成数据的命令保持不变,只有format参数设置为clickhouse。生成数据后,可以将其加载到数据库中:
./tsbs_load_clickhouse --file /tmp/data
我们已经准备好进行基准测试运行。
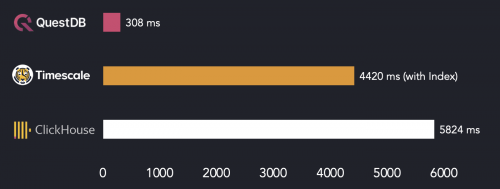
上图显示,在这个特定查询中,QuestDB比TimescaleDB和ClickHouse都快一个数量级。
有趣的是,基于索引的扫描并不能帮助TimescaleDB赢得竞争。这很好地说明了这样一个事实,即专用的并行友好存储模型可以使您不必处理索引并在数据摄取期间支付额外的开销。
下一步,让我们尝试另一种流行的查询类型。在时间序列数据的世界中,通常只根据某个过滤器查询最新的行。QuestDB通过负限制子句值优雅地支持这一点。如果我们要查询从快速移动但省油的卡车发送的十个最新测量值,它将如下所示:
Query 2 (QuestDB)
SELECT *
FROM readings
WHERE velocity > 75.0 AND fuel_consumption < 10.0
LIMIT -10;
请注意查询中的LIMIT-10子句。它基本上要求数据库返回与过滤器相对应的最后10行。由于基于指定的时间戳列的隐式升序,我们也不必指定order BY子句。
在TimescaleDB中,此查询看起来更详细:
Query 2 (ClickHouse and TimescaleDB)
SELECT *
FROM readings
WHERE velocity > 75.0 AND fuel_consumption < 10.0
ORDER BY time DESC
LIMIT 10;
这里,我们必须指定降序BY和限制子句。当谈到ClickHouse时,除了另一列用于存储时间戳(创建时间而不是时间)之外,查询看起来就像TimescaleDB。
我们列表中的数据库如何处理此类查询?
让我们测量并找出答案!
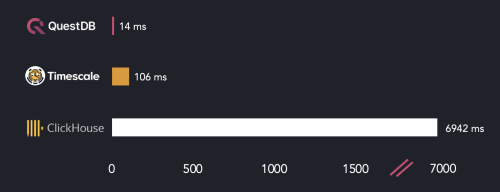
QuestDB、ClickHouse和TimescaleDB的热限制查询执行次数-查询2
这一次,不管是否令人惊讶,TimescaleDB比ClickHouse做得更好。这是因为,就像QuestDB一样,TimescaleDB过滤从最新的基于时间的分区开始的数据,并在找到足够多的行后停止过滤。我们还可以在velocity和fuel_consumption列上添加一个索引,但这不会改变结果。这是因为TimescaleDB不使用索引,而是对此查询进行完全扫描。由于这种行为,QuestDB和TimescaleDB在练习中都比ClickHouse快得多。
不用说,TimescaleDB和ClickHouse都是伟大的工程。您的观察可能会有所不同,而您的特定应用程序的性能取决于许多因素。因此,与任何基准一样,您可以带着怀疑来看待我们的测试结果,并且自己进行测试。
这是我们的比较,现在是讨论并行SQL过滤器执行背后的设计决策的时候了。
二、它是如何工作的?
首先,让我们快速回顾一下QuestDB的存储模型,以了解它为什么支持高效的多核执行。数据库具有基于列的仅附加存储模型。数据存储在表中,每列存储在其自己的文件或多个文件中,以防表按指定的时间戳进行分区。

列文件布局示例
执行SQL筛选器(think,WHERE子句)时,数据库需要扫描文件以查找相应的筛选列。正如您可能已经猜到的,当列文件足够大,或者查询涉及多个分区时,在单个线程上过滤记录的效率很低。相反,可以将文件拆分为连续的块(我们称之为“页面帧”)。然后,多个线程可以以一种更为优化的方式,利用CPU和磁盘资源在每个页面帧上执行过滤器。

并行页帧扫描示例
我们已经对某些分析类型的查询进行了此优化,但对于使用过滤器的完整或部分表扫描,我们没有进行此优化。这就是我们在6.3版中添加的内容。
像往常一样,存在边缘案例和暗礁,因此实现并不像听起来那么简单。比方说,如果您的查询有一个过滤器和一个LIMIT-10子句,就像我们最近的基准测试中一样,该怎么办?然后,数据库应该并行执行查询,获取最后10条记录并取消剩余的页面框架过滤任务,这样就不会有其他工作线程进行无用的过滤。当PG连接或HTTP连接关闭或查询执行超时时,应进行类似的取消。因此,正如您在上面的比较中所看到的,我们确保处理所有这些边缘情况。如果您对实现细节感兴趣,请检查这个冗长的pull请求。
从最终用户的角度来看,此优化始终处于启用状态,并应用于非JIT和JIT编译的过滤器。但是它如何提高QuestDB的性能呢?让我们看看吧!
三、加速测量
我们将使用与上述相同的基准测试环境,同时使用略有不同的查询来保持简单:
Query 3
SELECT count(*)
FROM readings
WHERE velocity > 75.0 AND fuel_consumption < 10.0;
此查询统计快速移动但省油的卡车发送的测量总数。
首先,我们关注冷执行时间,即列文件数据不在操作系统页面缓存中的情况。多线程运行使用QuestDB 6.3.1,而单线程运行使用6.2.0版本的数据库。这是因为JIT编译仅在从6.3开始执行并行过滤器时才可用。数据库配置保持默认,但在相应测量中禁用或启用JIT除外。还请注意,虽然此给定查询支持JIT编译,但JIT编译器支持的查询类型有许多限制。
下表显示了冷执行时间。
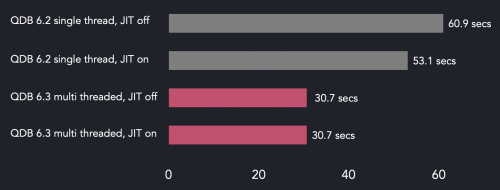
QuestDB 6.3-query 3中冷查询执行时间的改进
那是什么?并行过滤器的执行速度只有原来的两倍。此外,启用JIT编译的过滤器对最终结果几乎没有影响。问题是磁盘是这里的瓶颈。
让我们试着从这些结果中了解一些道理。当数据仅在磁盘上时,QuestDB 6.3执行查询大约需要30.7秒。查询引擎必须扫描两组列文件,182个分区,每个分区有两个50 MB的文件。这为我们提供了大约18.2 GB的磁盘数据和大约592 MB/s的磁盘读取速率。这低于EBS卷中配置的最大值,但我们应该记住,最大吞吐量允许有10%的波动,更重要的是,EBS优化实例的个别限制。我们的实例类型是c5a。12xlarge,而且根据AWS文档,它在128千兆位I/O上的速度限制为594 MB/s,这非常接近我们的封底计算。
长话短说,我们使用多线程查询执行来最大化磁盘,而版本6.2中的单线程执行时间保持不变。考虑到这一点,进一步改进实例类型和卷将带来更好的性能。
当涉及到热执行场景时,事情应该会变得更加令人兴奋,所以我们开始吧。在接下来的以及所有后续的基准测试运行中,我们测量同一查询的平均热执行时间。
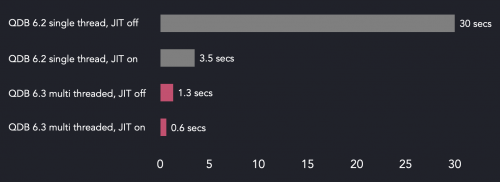
QuestDB 6.3-query 3中的热查询执行时间改进
在这个特定的框中,默认QuestDB配置导致共享工作线程池使用16个线程。因此,与6.2运行相比,这两个6.3运行都在多个线程上执行过滤器,从而加快了查询速度。另一个观察结果是6.3上JIT编译过滤器和非JIT过滤器之间几乎有1倍的差异。因此,即使有许多内核可用于并行查询执行,保持JIT编译处于启用状态也是一个好主意。
你可能已经注意到上图中有一个奇怪的比例。即禁用JIT编译时的执行时间差。QuestDB 6.2用一个线程完成查询需要30秒,而在6.3上只需要大约1.3秒。这是23倍的改进,仅用并行处理无法解释这一点(记住,我们在16个线程上运行过滤器)。那么,原因可能是什么呢?
问题是并行过滤器执行与JIT编译的过滤器函数使用相同的基于批的模型。这意味着过滤器在一个紧凑、CPU友好的循环中执行,而匹配行的结果标识符存储在一个中间数组中。例如,如果我们限制并行过滤器引擎在单个线程上运行,这就像添加共享一样简单。工人count=1数据库设置,则测试中的查询将在大约13.5秒内执行。因此,在这个场景中,在单个线程上完成的基于批处理的过滤器处理允许我们减少55%的查询执行时间。显然,引擎可以使用多个线程,使其运行得更快。有关如何在SQL JIT编译器中执行基于批处理的过滤器处理的更多信息,请参阅本文。
我们在这里使用的查询还有一个优化机会。也就是说,如果查询只选择简单的聚合函数,如count(*)或max(*),而没有列值,我们可以将函数下推到过滤器循环中。例如,过滤器循环将增加count(*)函数的计数器,而不是对过滤后的行标识符进行更通用的累加。您可以说这样的查询非常适合,但它们可以在各种仪表板应用程序中得到满足。因此,这是我们将来肯定会考虑添加的内容。
四、下一步是什么?
当然,6.3中引入的并行SQL过滤器执行并不是我们追求的最终目标。正如我们已经提到的,我们为聚合查询(如SAMPLE BY或GROUP BY)准备了多线程,但只针对特定形状的查询。聚合函数下推是另一种潜在的优化。因此,请继续关注进一步的改进!
一如既往,我们鼓励用户在QuestDB实例上试用6.3.1版本,并在Slack社区中提供反馈。您还可以玩我们的实时演示,看看它执行查询的速度有多快。当然,我们非常欢迎对GitHub项目的开源贡献。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















