
编者按:2021年全国知识图谱与计算语义大会(China Conference on Knowledge Graph and Semantic Computing 2021)共设立五个评测主题,十四个评测任务。百分点认知实验室参加了该评测任务中的“生活服务领域知识图谱问答”比赛,经过长达3个多月的激烈角逐,百分点认知智能实验室在比赛数据集上得分0.7852,位列B榜第三名,获得该大赛的季军。本文主要介绍实验室在本次比赛和知识图谱问答业务实践中使用的技术方案。
一、背景介绍
知识图谱的早期理念源于万维网之父Tim Berners-Lee关于语义网(The SemanticWeb)的设想,旨在采用图结构(Graph Structure)来建模和记录世界万物之间的关联关系和知识,以便有效实现更加精准的对象级搜索。知识图谱的相关技术已经在搜索引擎、智能问答、语言理解、推荐计算、大数据决策分析等众多领域得到广泛的实际应用。
随着自然语言处理、深度学习、图数据处理等众多领域的飞速发展,知识图谱在自动化知识获取、知识表示学习与推理、大规模图挖掘与分析等领域又取得了很多新进展。知识图谱已经成为实现认知层面的人工智能不可或缺的重要技术之一。
知识图谱是较为典型的交叉领域,涉及知识工程、自然语言处理、机器学习、图数据库等多个领域。而知识图谱的构建及应用涉及更多细分领域的一系列关键技术,包括:知识建模、关系抽取、图存储、自动推理、图谱表示学习、语义搜索、智能问答、图计算分析等。做好知识图谱需要系统掌握和应用这些分属多个领域的技术。
近年来,基于自然语言的问答系统逐渐成为人工智能及其相关产业的重点关注领域,成为人机交互的新趋势。相比于传统的搜索引擎获取知识的方式,智能问答系统基于自然语言交互的方式更符合人的习惯。
随着人工智能的进一步发展,知识图谱在深度知识抽取、表示学习与机器推理、基于知识的可解释性人工智能、图谱挖掘与图神经网络等领域取得了一系列新的进展。这些进展让知识图谱的问答系统需要面对的两个问题(问题的理解和问题到知识图谱的语义关联)得到了较好的解决,使得知识图谱智能问答工程应用成为现实。百分点认知智能实验室在多个行业积累了丰富的基于知识图谱问答的技术实践经验。
二、赛题任务
1. 任务描述
本任务属于中文知识图谱自然语言问答任务,简称CKBQA (Chinese Knowledge Base Question Answering)。即输入一句中文问题,问答系统从给定知识库中选择若干实体或属性值作为该问题的答案。
今年在OpenKG基础上引入生活服务领域知识库及问答数据。其中包括旅游、酒店、美食等多种领域的数据,同开放领域知识库PKUBASE一起作为问答任务的依据。
2. 数据格式
数据集以自然语言问句和对应的SPARQL查询语句标记组成。
SPARQL [1] (SPARQL Protocol and RDF Query Language),是为RDF开发的一种查询语言和数据获取协议。其语法由三元组组成,其中?x所在where语句中的位置表示需要查询的是哪一个要素。
比赛数据示例:
问题:莫妮卡·贝鲁奇的代表作?
Sparql:select?x where { <莫妮卡·贝鲁奇> <代表作品> ?x. }
答案:<西西里的美丽传说>
3. 问题格式
传统的问题知识图谱查询问题类型,根据实体数量不同主要分为单实体查询、双实体查询、三实体查询,又根据查询方式不同分为一跳查询,跳查询、关系查询,如图1所示。

图1. 传统问题类型
今年在问题设置上引入了一些特殊问题类型,主要是添加了filter、order等函数和http://www.w3.org/2001/XMLSchema#float等RDF标准类型后缀的美团生活服务类问题,如图2所示。

图2. 特殊类型问题
三、技术方案
1. 方案概述
百分点科技提出了一种结合语义解析和信息检索的方法,该方法应用语义解析处理具有固定句型或“Filter”等函数的问题,并应用信息检索处理具有不同句式的问题。技术方案总结如图3所示。在信息检索模块中,Pipeline由四个子模块组成,即指称识别、实体链接、路径生成和路径排序。在语义解析模块中,百分点科技采用了SPARQL模板匹配和SPARQL生成两种方法实现。最后,通过同样的方式选择答案,将语义解析模块和信息检索模块集成在一起。
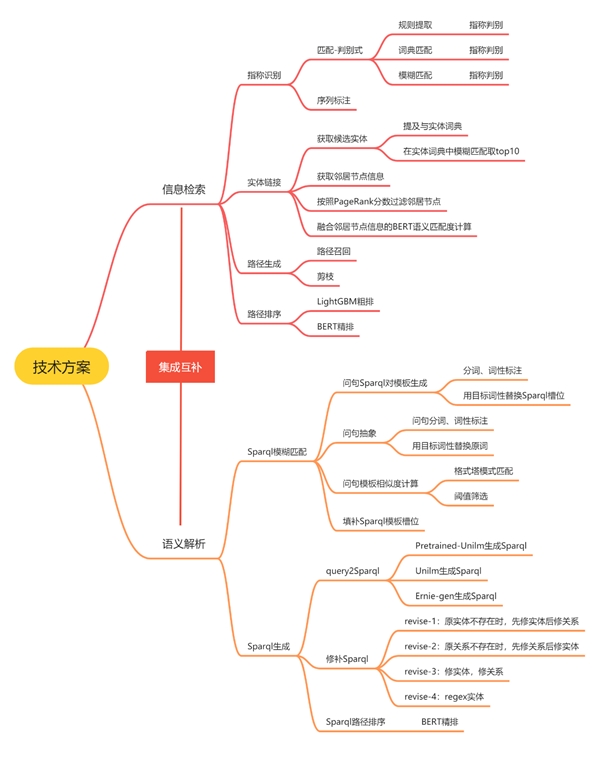
图3. 技术方案总结
该方案的优势在于能够处理复杂函数结构的问题,例如:
问题:我们现在在北京的首都宾馆,行走3公里的能到达的景点都有哪些?
Sparql:select ?x where { <首都宾馆(原首都大酒店)> <附近> ?cvt. ?cvt <实体名称> ?x. ?cvt <距离值> ?d. ?x <类型><景点>. filter(?d<=3) }
2. 方案介绍

图4. 流程实现和模型原理图
技术方案框架如图4所示,各个模块与各个子模块执行流程与功能介绍如下。
信息检索(Information Retrieval):借助问题传递的信息,直接从KG中检索出可能的答案,并排序答案。
指称识别:识别问题中提及的图谱实体节点的文本片段;
实体链接:根据指称和问题检索出图谱中与其对应的实体,作为话题实体;
路径生成:从识别到的话题实体出发,遍历生成从话题实体到答案实体的候选路径;
路径排序:对候选路径进行排序,筛选出最能回答问题的正确路径。
语义解析(Semantic Parsing):将问题解析成可执行的Sparql查询语句,执行语句获取答案。分为两种方法,一种是Sparql模板匹配,一种是Sparql生成,两种方法相互独立。
(1)SPARQL模板匹配:将问题与训练集中最相似的SPARQL模板进行匹配。
(2)SPARQL生成:利用预训练语言模型Unilm生成新的SPARQL。
query2Sparql:根据query语义解析成Sparql语句;
Sparql候选路径生成:基于Sparql语句中的实体,去知识图谱中匹配与Sparql相关的候选路径;
路径排序:对候选路径进行排序,筛选出最能回答问题的正确路径。
结果合并:根据不同模型输出结果的排序分数对输出进行过滤,获取最终结果。
3. 指称识别
指称识别的目标是识别问题中提到的知识库实体的文本片段。为了提高召回率,百分点科技实现了四种提及识别方法。
(1)序列标注:如图5所示,将识别作为序列标记任务建模,并基于Roberta+CRF训练K-Fold交叉验证的序列标记模型。
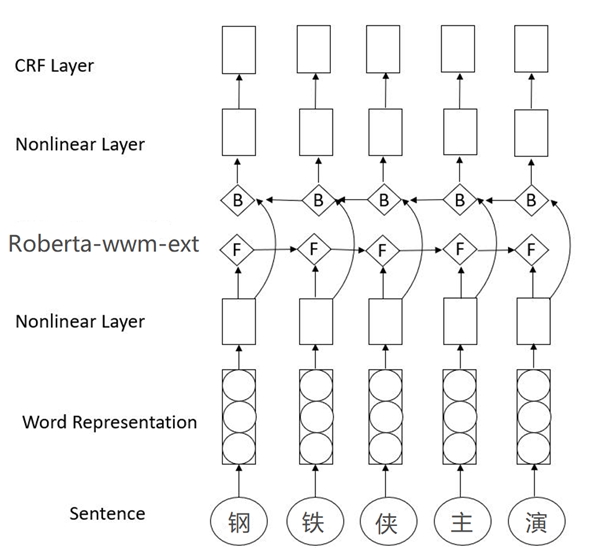
图5. 序列标注模型架构
(2)匹配-判别式:候选实体指称数目较多,因此通过一个指称判别模型进行过滤。在候选指称的开始和结束位置加入“&”号作为实体位置标志位,然后用BERT模型做文本分类判断当前的实体指称是否正确。
基于规则的识别:使用正则表达式来匹配特殊的实体和属性值,如日期、连续英语和引号中的文本片段等。
基于字典的识别:通过最长匹配算法与实体提及词典识别问题中的提及。
模糊匹配:建立一个实体提及次数的倒排索引,然后将问题作为查询词,回忆出匹配度最高的前10个提及次数。以序列标注的输出为主要结果,辅以其他方式的结果。
4. 实体链接
当前任务是基于上一步获得的候选实体指称,找到其对应的KG中真实存在的实体,也称为话题实体。分为以下步骤:
(1)获取候选实体:使用上一步获取到的实体提及在别名字典与实体集合中进行模糊匹配,获取排名top10的候选实体。
(2)获取邻居节点信息:从候选实体出发(作为头实体或尾实体),获取候选实体的所有一阶路径。
(3)按照PageRank分数过滤邻居节点:获取候选实体邻居节点的PageRank分数,保留前10分数的邻居节点。
PageRank假设:
数量假设:一个实体节点的入度(被链接数)越大,实体重要性越高。
重要性假设:一个实体节点的入度的来源(哪些实体在链接它)重要性越高,实体重要性越高。
(4)融合邻居节点信息的BERT语义匹配度计算:利用邻居节点和问题信息,通过BERT进行语义匹配度计算,过滤候选实体,得到话题实体。
候选实体筛选模型输入数据格式:[CLS]问题[SEP]提及&候选实体[SEP]邻居节点关系[SEP]
计算方式:取[CLS]张量做二分类(0,1分类),保留其分数排名top10 的实体。
5. 路径生成
在实体链接步骤中获取到了问题中的话题实体,路径生成是从话题实体出发,遍历KG,生成所有可能的答案路径,在过程中对路径进行剪枝。
(1)路径召回:路径召回策略分为单实体和多实体两种情况。其中,多实体优先,即如果多实体间存在路径,则不进行单实体召回。
单实体:
(1) 作为头实体的一度路径 <实体><关系>;
(2) 作为尾实体的一度路径<关系><实体>;
(3) 对 (1) 扩展至二度出路径 <实体><关系1><关系2>;
(4) 对 (1) 扩展至二度入路径 <实体><关系1><关系2>;
(5) 对 (2) 扩展至二度出路径<关系1><实体><关系2>;
(6) 对 (2) 扩展至二度入路径<关系1><实体><关系2>。
多实体(以双实体为例):
(1) 一度路径 <实体1><关系1><实体2><关系2>;
(2) 一度路径<关系1><实体1><关系2><实体2>;
(3) 一度路径<关系1><实体1><实体2><关系2>;
(4) 一度路径 <实体1><关系1><关系2><实体2>;
(5) 对 (1)(同2、3、4) 扩展至二度出路径 <实体><关系1><实体2><关系2><关系3>;
(6) 对 (1)(同2、3、4) 扩展至二度入路径 <实体><关系1><实体2><关系2><关系3>;
(7) 实体间的关系<实体1><实体2>。
(2)剪枝:为避免候选答案数目爆炸,我们根据以下策略进行剪枝。
(1) 删除一跳路径中答案实体是话题实体的路径,避免将话题实体本身作为答案;
(2) 如果二跳节点超过10000个,则不进行二跳;
(3) 删掉二跳路径中答案实体是话题实体的路径,避免将话题实体本身作为答案;
(4) 当二跳路径(出或入)数超过100条但小于500时,删掉二跳路径(出或入)中的关系与问句没有任何字符上的交集的候选答案路径;
(5) 当二跳路径(出或入)数超过500时,过滤掉所有二跳路径。
6. 路径排序
路径排序分为粗排和精排两个步骤。
粗排:根据问题query和候选路径path的特征,对候选路径进行粗排,采用LightGBM机器学习模型,保留最多20条路径,选取的模型特征如图6所示。

图6. LightGBM模型特征
精排:采用预训练语言模型计算query和path的语义匹配度,选择得分最高的答案路径作为答案,如图7所示。

图7. 语义相似度计算模型
7. SPARQL模板匹配
当前任务是根据训练集的数据获取“问题——Sparql”的问答模板,然后通过匹配问题模板的方式获取Sparql模板,并将实体关系填入Sparql模板,得到完整的Sparql。
(1)问句Sparql对模板生成:利用训练集的sparksql,抠出实体形成槽位,生成模板。
(2)问句抽象:将问句query转化为抽象的query模板,以方便下一步的query匹配和Sparql模板槽位填充。具体地,利用分词工具将词性为LOC,ORG,nz,m,PER,n的词抠出,并替换成相对的词性。
(3)问句模板相似度计算:相似度计算方法“格式塔模式匹配”,保留相似度分数最大的抽象query模板,取其对应的抽象Sparql模板。
(4)填补Sparql 模板槽位:将query中的实体关系和抽象Sparql模板中的槽位一一对应,将对应的实体关系填入到Sparql模板中,得到完整的Sparql。
8. SPARQL生成
采用预训练语言模型Unilm(Unified Language Model)的seq2seq架构生成Sparql。类似于翻译任务,输入问题,输出Sparql,Unilm模型结构如图8所示。

图8. query2sparql模型
输入query:运动员李娜的丈夫的主要奖项有哪些?
输出Sparql:select ?Z where{?X <中文名> “李娜”. ?X <类型><运动员>. ?X <丈夫> ?Y.?Y <主要奖项> ?Z.}
由于Unilm模型直接生成的Sparql可能与KG中存在的实体关系有差异,如上例中的“李娜”的“丈夫”是用“配偶”存储的,故不能直接查询得到答案,还需对实体关系做进一步的修补,使修补后的Sparql的实体和关系是真实存在于KG中的。有以下4种修补策略:
(1)原实体不存在时,先修实体后修关系。具体地,采用实体链接中的获取候选实体方法得到新实体,然后把原关系替换成新实体的一阶关系。
(2)原关系不存在时,先修关系再修实体。具体地,采用原关系在Elasticsearch中关系字典的模糊匹配或者原关系的同义词关系(需在kg的关系字典中),然后把原实体替换成新关系的一阶实体。
(3)不管原实体关系是否存在,修实体+修关系。
(4)对实体使用Sparql的regex语法(不需要完全正确的实体名称)。例如:select ?x where { ?x <主要成就> ?y. filterregex(?y, '杂交水稻之父'). }
由于修补后一个问题会有多个候选Sparql路径,因此也需对其进行排序,筛选出最能回答问题的正确Sparql,方法同信息检索中路径排序中的BERT精排。
9. 结果合并
在信息检索和语义解析两大类方法中,最终都是使用的同一模型计算与问题的相似度,因此可以将两类方法的结果放在一起比较,取分数最高的结果作为最终答案。
四、评测效果
本方案在2021 CCKS知识图谱问答大赛的数据集上进行了评测,数据方面,相较往年在OpenKG基础上引入生活服务领域知识库及问答数据,其中包括旅游、酒店、美食等多种领域的数据,同开放领域知识库PKUBASE一起作为问答任务的依据。特别是生活服务领域的数据集,涉及过滤、分类等功能。训练集有6525个带标签sparql和答案的问题,开发集有2100个问题,测试集有1191个问题。给定的知识图包含6600万个三元组和超过2000万个实体。
百分点科技使用ElasticSearch构建一个反向索引,整个知识图谱存储在Nebula图形数据库中,BERT模型统一使用RoBERTa-wwm-ext-large。
本任务的评价指标包括宏观准确率(Macro Precision),宏观召回率(Macro Recall),Averaged F1值。
本方案最终的实验效果指标如下:
识别效果:Averaged F1=0. 7852
总结
在应用有效性方面,通过2021年全国知识图谱与计算语义大会知识图谱问答任务,百分点科技设计的方案在公开数据集上性能表现优秀,具有很好的应用效果,且后续可继续对路径排序算法进行优化,使其能够更准确地选择正确的答案。
在价值潜力方面,该方案扩展性强,且适合各种不同业务场景的问答需求,表现出良好的可扩展性,适合工程应用。
百分点认知智能实验室已经将该方案部署到了众多不同业务的知识图谱系统中,将知识图谱与预训练模型融合,通过逻辑推理进行复杂问题查询,让问答查询更智能。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















