
4月7日,自然语言处理领域国际顶级学术会议NAACL 2022(The North American Chapter of the Association for Computational Linguistics)公布论文入选名单,由华为云语音语义创新Lab多名研究者撰写的信息抽取论文《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》被NAACL 2022 Findings接收,这代表着中文命名实体识别的最优结果 (SOTA) 被进一步刷新,更准确有效的实体识别将推动下游自然语言处理任务的进一步发展。
NAACL由国际计算语言学学会(ACL)主办,与ACL、EMNLP并称NLP领域的三大顶会,是人工智能的重要研究阵地。NAACL的录用十分严格,根据往年评选结果,只有不到30%的论文被接收。
作为自然语言处理中最经典、最基础的任务,命名实体识别一直受到广泛的关注与研究。近年来,中文命名实体识别任务上取得了明显进展,很多新的方法和框架被陆续提出,但往往忽略了实体词的内部组成。
对于中文命名实体而言,很多类别的实体都具有很强的命名规律性。比如说,以“公司”或者“银行”结尾的实体词,通常属于组织机构这一实体类别。因此,在《Delving Deep into Regularity: A Simple but Effective Method for Chinese Named Entity Recognition》中,华为云语音语义创新Lab的研究者提出用简单有效、规律性引导的识别网络来探究中文实体词中的规律性。
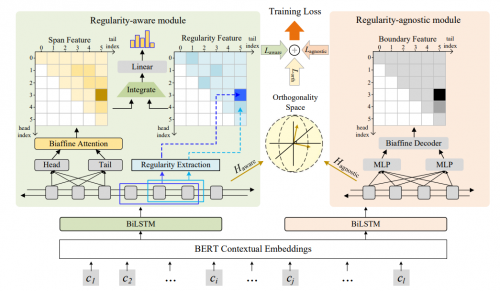
图1 规律性引导的识别网络
如图1,华为云研究者首先利用注意力机制显著地提取每个文本段的规律性,进而将这种表征文本内部的规律性的特征和通过Biaffine Attention提取的文本段特征结合起来,进行后续的实体识别。为了避免由于过度关注实体内部规律性导致的实体边界识别偏差,研究者们另外设计了一个与规则无关的模块来帮助模型更准确地识别实体的边界。
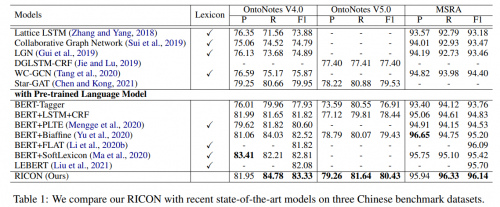
图2 中文数据集上的实验结果
华为云研究者提出的规律性引导的识别网络,如图2,在MSRA, Ontonotes4.0, 和Ontonotes5.0三个大规模中文实体识别数据集上都取得了SOTA的结果。同时,本文提出的方法不依赖于外部词典信息,并且F1值超过了目前所有使用词典信息的方法的结果。这充分说明通过研究实体词的内部规律性,研究者们提出了一个非常有效的网络结构。
不止在信息抽取方面,华为云语音语义创新Lab秉承开放创新、勇于探索、持续突破关键技术的精神,面向行业客户提供领先的语音语义AI能力,结合大量行业知识,推出知识计算等行业解决方案,打造业界一流的知识计算竞争力。截至目前,已在政务、金融、石油等多个行业进行了落地和实践,帮助客户实现AI落地与智能升级。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















