
一个电话,打破深夜的宁静
9月20日晚上10点
刚完成外地一个重点项目为期2周的现场支持,从机场回家的路上,一阵急促的铃声惊醒了出租车上昏昏欲睡的我,多年的工作经验告诉我这么晚来电一定是出事了,接起电话,是KS。
KS正在跟一个国内关键客户数据库国产化替代项目,该项目核心业务系统由Oracle替换为金仓数据库KingbaseES,项目前期应用适配和测试稳步推进,根据计划,整个系统将于9月21日晚上10点启动上线,并于22日早上8点前全部完成。以确保22日客户上班时间可以正常使用,并能顺利支撑业务高峰期。
KS是配合应用开发项目团队正在为项目上线做最后的测试和验证的技术支持人员,他急切地表示,在项目团队在进行一次压力模拟测试时,当数据库并发连接超700,系统中某一个业务流程的操作出现明显卡顿,再对该业务流程某项操作并发再增加时,甚至出现了数据库停止服务。
上线在即,突然发现此类问题,显然这是重大风险,该项目是客户计划重点打造的国产化标杆项目,本次待上线业务系统是客户所有部门员工每天必用的系统,客户上上下下对该项目都十分关注,项目按时上线是必须要完成的任务。
经过快速巡检和系统查看,并结合过往那个经验,KS初步判断这不是简单的系统问题,因此找到了我。
初见端倪,却几尽崩溃
9月20日晚上11点
挂了电话,我立马赶到项目所在地,客户、集成商和金仓三方的的项目负责人均在现场,项目上线在即,现场的状况让KS沟通起来稍显语无伦次,尽管如此,我还是清楚地感受到了集成商和客户的担忧。
问题的焦灼程度及现场巨大的压力告诉我,我的判断和处理结果直接影响项目的顺利交付和客户信息系统国产化的信心。
我快速进入工作状态,开始查看数据库的各项参数和相关日志文件、指标,同时仔细分析了下测试时的主要场景特点。首先抓住以下问题表现作为根因分析的抓手:
测试中,业务查询非常慢。监控数据库,从操作系统层观察到系统大量IO,CPU IO 等待达到40%,IO 大小超过500MB/s 。
聚焦该现象初步确认引发IO的进程:根据iotop确认产生大IO的进程都是kingbase进程,问题指向数据库,怀疑是部分SQL存在性能问题,导致数据库IO过大。但是如何准确定位数据库等待事件成了一个难题,首先按照以往经验我想到通过查询sys_stat_activity字典确定,但是sys_stat_activity只能查询当前时间点的数据,后来我又采用一些其他方法试图采集一些信息,但是这些信息分散、维度有限,不足以支撑问题的快速定位,一时间我陷入迷茫。
时间马上到了第二天,一边是我不知道该如何获取更多帮助定位问题的数据信息,另一边是客户差不多每过半小时过来询问一次解决进展,后来干脆坐在我们身后看着我们解决问题。无形的压力接踵而至,不断加速的心跳仿佛是在呼喊:谁来拯救我!!!
柳暗花明,关键问题迎刃而解
9月21日凌晨1点
数不清是第多少次安抚完客户,我强迫自己保持镇定,心想不能这么僵持下去,得快点找到突破口。于是我重整精神,迅速在大脑中回放、梳理、挖掘,寻找突破方法。突然我想到前一阵产品内部培训提到的产品新能力,可以通过工具KSH和KWR分别对数据库的会话历史和各种负载信息进行收集,并能快速生成报告,赶紧和相关同事了解了下现场的版本情况和使用方法,并确认现场版本已经具备相关能力。于是尝试先使用KSH工具进行分析,皇天不负有心人,终于在黎明到来前,迎来了“柳岸花明”:。
1.通过KSH周期性采集数据库的等待事件信息,展现当前及过去一段时间的系统等待事件情况。

2.查看KSH 报告,我发现了 “BufFileWrite” 等待事件比例极高,该等待事件表示进程正在等待将BUFFER内容写出到文件。“BufFileWrite” 等待事件,通常意味着进程在进行写临时文件操作。走到这里已经很明显了,可以确定是由于特定的SQL导致了系统的IO问题。接下来就是要找到这个“罪魁祸首”,即确认问题SQL并对其进行优化。
3.确认问题SQL:再次分析KSH报告,找到等待“BufFileWrite”事件的SQL,确认问题SQL如下:
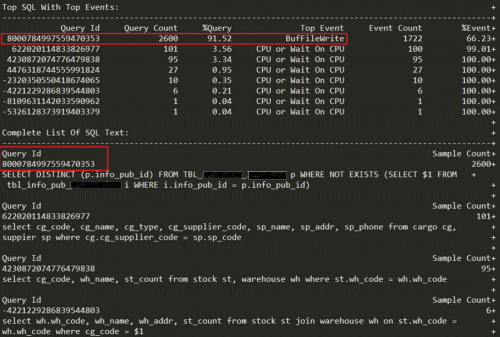

4.分析优化SQL:可以看到SQL采取hash join,而hash操作引发的磁盘写,是引发大量磁盘IO的原因。

去掉hint后,执行计划如下:

可以看到,去掉hint之后,SQL采用索引扫描了,不但IO减少了很多,速度也更快了。
5.跟应用开发人员沟通后,确认是前期适配时,由于测试环境数据量较少,通过加hint (/*+set(enable_nestloop OFF)*/),可以获得更快的性能。而现在模拟生产环境测试时,测试数据量成倍增加,hint 不再适用。
6.修改SQL:协调应用开发人员修改SQL,再次验证。
9月21日凌晨4点
确认经过修改,数据库不再有IO 问题,压测下,之前出现的卡死现象也未在出现。
“排雷”行动,确保无忧上线
完善的配套工具将我从问题的泥潭中解救,让问题定位和解决的速度得到了飞速提升,客户终于露出了笑脸。为了确保后续上线的顺利,我和现场的同事不敢放松,担心还会有潜在的风险,因此决定再进行一遍“排雷”行动。因为有工具的加持,让我们有信心能在几小时内完成之前可能几天都完成不了的事情。
9月21日凌晨5点
说干就干,应用开发商继续进行对业务进行压测,我们在业务运行过程中,采用各类巡检手段,配合使用KWR对数据库状态开始进行全面检测,以排查可能还未被发现的“雷区”,果然,在持续的测试和监控过程中,早上大约7点多,我发现系统CPU使用率此时非常高,但IO正常,显然这不太正常。这下心又提到了嗓子眼,我赶紧展开新一轮的排查:
1.先确认最耗CPU的进程:使用top命令,查看最消耗CPU资源的进程,确认这些进程都是kingbase进程。
2.确认数据库等待事件:查看数据库的 KWR报告,确认数据库的时间都花在CPU上,没有明显的等待事件。从这些现象可以推断进程状态是正常的,特定SQL性能不佳,消耗大量CPU资源。

3.准确定位SQL: KWR工具也提供了TOPSQL功能,可以根据CPU、IO、执行时间对SQL进行排序。对于当前问题,通过查看“Top SQL By Elaspsed Time”章节,可以快速确定出最消耗CPU的SQL。。


4.SQL 效率分析:完整的SQL有4次调用了以上的子查询,而且子查询用到了窗口函数,窗口函数是最消耗CPU资源的。这部分对于性能的消耗如下:

5.可以看到,这部分简单的查询需要 768ms,4次调用总共需要3秒。因此可以考虑通过提取公共表达式(CTE),整条SQL可以减少时间2秒左右。
通过提取SQL的公共表达式,将以上的子查询提取到CTE。
9月21日上午10点
修改完SQL后,再次运行KWR,确认以上SQL性能问题得以解决。
接下来,一切都比较顺利,但我们仍然不敢放松警惕,时刻关注数据库的运行状态,好在有KWR和KSH能帮助我们快速进行相关数据的收集,帮助我们做到心中有数,同时通过收集的数据,使用数据库自带的诊断工具——KDDM,对报告进行阶段性分析,进一步诊断性能问题,为开发商又提供了一些优化建议,比如下面的索引建议:
1.KDDM针对如下SQL给出了索引建议。

2.分析执行计划:从初始的执行计划看,执行效率非常低。

3.KDDM 优化建议:建议创建o.f_creattime 索引

4.根据KDDM的建议,创建索引后的执行计划如下:

5.可以看到,根据KDDM建议,创建索引后,SQL的执行效率提升了500倍。
经过24小时的奋战,客户的业务系统顺利上线,并通过使用高峰期,随着客户宣布项目上线成功,项目组的房间里响起了热烈的掌声,掌声既是对全体项目成员的感谢,也是对金仓产品和金仓人的肯定。
而我最要感谢的是我们研发团队为我们DBA提供的数据收集和诊断工具,帮我们从繁杂的数据中提炼出价值信息,让我们能够更高效轻松地面对现场优化问题。
走出客户大楼,吸一口北京秋天清冽的空气,这24小时不是终点,数据库国产化之路还会遇到很多棘手问题,但是作为人大金仓的一员,我有信心,我们将通过不断打造产品能力,为用户创造更多的价值。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















