
2018年以来,以BERT、GPT等为代表的大规模预训练模型,带来了人工智能领域新的突破,由于其强大的通用性和卓越的迁移能力,掀起了预训练模型往大规模参数化发展的浪潮。其中微软、谷歌、Facebook、NVIDIA等诸多公司在预训练算法上持续大量投入。国内如百度、华为、阿里等公司也相继投入到大规模预训练模型算法的研究中。现阶段,在中文自然语言处理方向上,预训练也如雨后春笋一样涌现。现有算法主要依赖纯文本学习,缺少知识指导学习,模型能力存在局限。
2021年10月13日,腾讯云小微与腾讯AI Lab联合团队提出了基于知识的中文预训练模型——“神农”,该模型仅包含十亿级参数量,并一举登顶CLUE总排行榜、1.1分类任务、阅读理解任务和命名实体任务四个榜单,刷新业界记录。
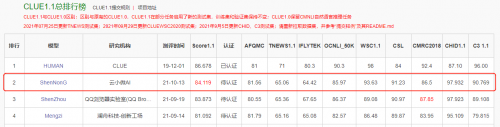
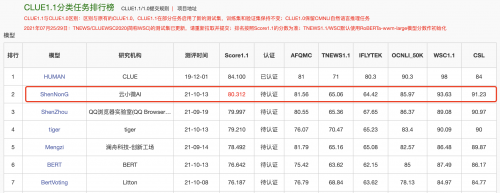
10月13日,“神农”刷新CLUE分类榜单纪录;HUMAN 为人类标注成绩,非模型效果,不参与排名。
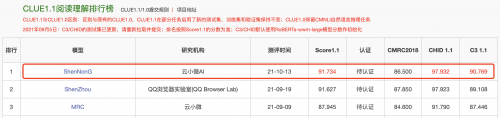
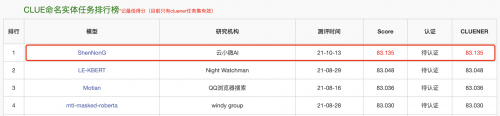
同时,“神农”登顶CLUE阅读理解、NER榜单,刷新业界记录。
作为中文语言理解领域最具权威性的测评基准之一,CLUE涵盖文本相似度、分类、自然语言推理、阅读理解、NER等众多语义分析和理解类子任务。近段时间,各大公司纷纷用CLUE作为预训练算法能力的验证和衡量标准。此次登顶CLUE榜单,不仅代表了云小微与腾讯AI Lab联合团队在中文预训练研究领域达到业内领先水平,并且推动中文预训练模型在理解和推理方面提升了一个新高度。
联合团队致力于将知识融入预训练模型,进而充分发挥已有参数下的模型潜力。模型结构方面,“神农”基于 Transformer 架构,仅包含十亿级的参数量。从数据量来看,“神农”以数百 GB 级的平文本做基石,涵盖百科、论坛博客、新闻、财经等众多领域的高质量文本。相对于业界其他中文预训练模型,“神农”在以下三个方面获得了突破性进展:
第一,“神农”从两个角度对知识进行建模,分别是“通用型推理知识”和“任务型知识”。通用型知识指的是现有知识,比如词法、句法、图谱等,这类知识的特点是通用性强,覆盖度广。虽然能整体提高模型的能力,但是在特定场景中往往不容易发挥作用。而任务型知识旨在挖掘场景下特有的知识,并通过将其泛化来提升预训练模型的能力。二者可谓相辅相成。
第二,联合团队将汉语中典型的篇章推理知识作为通用知识融入预训练过程中,如因果、对比、递进、转折关系等。中文是表达极其丰富的语言,存在大量指示性的虚词。这些虚词在中文的语义理解中起着至关重要的作用。比如:

这段话的语义可谓一波三折,而引起语义起伏变化的正是这些虚词。通过引入这类知识可以强化模型对中文的理解能力。
第三,“神农”提出基于对比学习的任务型知识挖掘和融入算法。通过定义知识模板,该算法可以为指定任务“定制知识”,并将其融入到训练过程中。另外,“神农”将挖掘出来的知识在大规模单语文本中进行泛化,大大提高了知识的表达能力。
“神农”正是通过充分利用这两类知识,进一步强化了中文预训练模型的能力,在包含文本分类、阅读理解等多类任务上表现出色。
一直以来,腾讯云小微团队和腾讯AI Lab团队持续深耕知识挖掘、语义理解技术以及预训练技术。云小微方面,依托自研的知识挖掘算法和深度学习技术,基于平台对行业知识的长期积累,能快速搭建多个领域的知识结构,有效地从非结构化文件中抽取关键信息,为行业提供全流程知识构建服务。在此加持下,团队通过将行业知识与预训练技术相结合,可以更好地服务应用,为各行各业输出完整的AI解决方案,不断渗透智慧生活各个场景。目前已在智能网联汽车、智慧文旅、智慧教育等多行业领域落地应用,服务广泛的用户群体。腾讯AI Lab始终强调研究与应用并重发展,其研究覆盖机器学习、计算机视觉、语音识别及自然语言处理等四大核心方向,其中自然语言处理方向强调赋予计算机系统以自然语言文本理解与外界交互的能力,并不断探索最前沿的文本理解和生成技术。实验室立足未来,开放合作,致力于不断提升AI的认知、决策与创造力,向“MakeAIEverywhere”的愿景迈步。
本次两个团队强强联合,深入探索知识与预训练的融合技术,提出了全新的基于知识的预训练方法,在这一领域又迈出了坚实的一步。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















