
夏日的阳光已经洒在树梢枝畔,奋斗了又3个月的MindSpore社区开发者们,带着无比的兴奋,为大家献上全新的1.3版本!日益精进的我们,在这个版本中为大家带来了全新的MindSpore Federated能力,解锁了支撑盘古千亿稠密大模型的众多关键特性、以及面向更多类型硬件的推理优化、图算融合、简易部署等新工艺,犹如开源时所誓言,持续不断的为AI开发者带来惊喜。下面就带大家快速浏览1.3版本的关键特性。
MindSpore Federated——支持千万级无状态设备的联邦学习
联邦学习是一种加密的分布式机器学习技术,它是指参与联邦学习的各用户在不共享本地数据的前提下共建AI模型,主要用于解决数据隐私和数据孤岛的问题。MindSpore Federated优先专注于大规模参与方的横向联邦的应用场景。
端云场景下的参与方是非常大量的手机或者IoT设备,其分布规模和设备不可靠性带来了系统异构、通信效率、隐私安全和标签缺失等挑战。MindSpore Federated设计了松耦合分布式服务器、限时通信模块、容忍退出的安全聚合等模块,使得任何时候只要部分客户端可用,都可以进行联邦学习任务,并解决了系统异构带来的“长尾效应”,提高了学习效率。
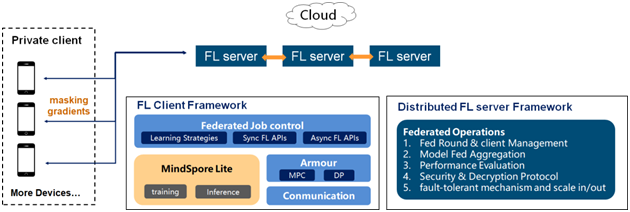
搭载于MindSpore端边云全场景统一的基础架构,MindSpore Federated将会作为华为终端的核心竞争力之一,在保护用户隐私的前提下,提供更具有个性化的用户信息决策。
盘古千亿稠密大模型关键特性开源
0.中文语言理解任务评测全球第一
全球最大中文语言预训练模型“鹏程.盘古”,在2021年4月23日权威的中文语言理解评测基准CLUE榜单中,总成绩及阅读理解、分类任务单项均排名第一,刷新三项榜单纪录,总成绩得分83;在NLPCC2018文本摘要任务中,取得了Rouge平均分0.53的业界最佳成绩,超越第二名百分之六十。
1.超大模型关键特性之——分布式推理及在线部署
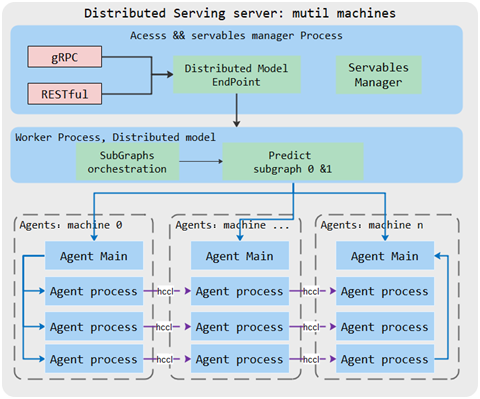
当大模型推理参数量较大难以部署到一张卡上时,MindSpore可通过OP-Level和PipeLine模型并行将大模型切分到多卡。我们实现了鹏程.盘古2000亿级参数量的模型部署。

MindSpore Serving支持分布式模型的在线推理部署,根据模型并行策略切分为多个小图,每个卡部署两个图的各一个小图。下图中,每个卡通过一个Agent进程管理图加载和执行,卡之间通过HCCL进行高速通信,分布式主worker进程和各个Agent进程之间通过gRPC通信,用于请求数据的发送和请求结果的接受。
2.超大模型关键特性之——增量推理(state resuse)及部署
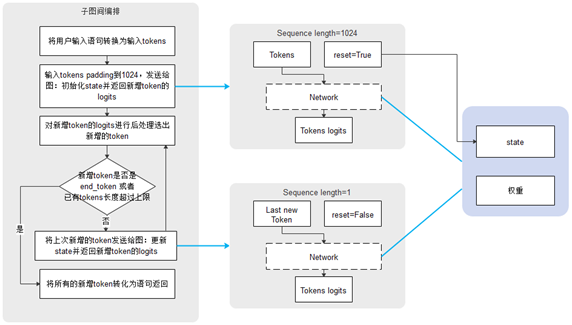
对于自回归(Auto-regressive)的语言模型,随着新词的生成,推理输入长度不断增大。如果使用动态图执行,在不同迭代间,图中每个算子的shape发生改变,无法利用之前缓存的算子编译信息,会影响性能。
我们通过修改推理脚本,实现了增量推理的功能,一次增量推理的流程包含两个阶段:第一阶段推理,输入为全量,将输入padding到固定长度,保存到state,这一阶段是为了处理不定长的输入,将输入的state保存下来;后续推理阶段,输入字长为1,即每次输入上一步生成的token,利用保存的state实现增量推理,产生下一个token并更新state。由于非线性操作的存在,此种增量推理的流程与正常全量推理并不完全等价,不过我们在下游任务推理中发现,增量推理的精度并无明显劣化。我们通过鹏程.盘古在昇腾硬件平台上进行了一系列实验,结果如下图所示:

在增量推理过程中,第一阶段只执行一次,而第二阶段会执行多次,比单纯的全量推理,整体性能提升比较明显。

MindSpore Serving支持增量推理模型部署,包括单卡模型和分布式模型场景。使用自定义子图间编排串接两个不同序列长度输入的执行,维护模型的状态,避免多个请求的执行干扰。
MindSpore Lite端云训练
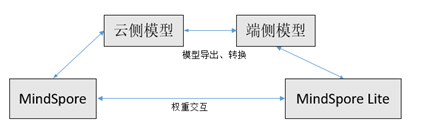
随着用户对数据隐私要求越来越高,许多用户隐私数据无法上传到云侧,因此在用户端侧进行训练将逐渐成为一个趋势,并且端云协同训练将可以充分利用端侧的计算资源,进一步降低训练所需的时间。当前MindSpore Lite支持对MindSpore训练导出的模型进行增量训练,实现云-端训练的无缝切换。但由于端侧硬件资源的限制,如何在不影响用户体验下进行训练,对端侧训练的内存和性能提出了挑战。
MindSpore Lite采用了训练内存复用、virtual batch、混合精度训练、在线融合、量化等手段对减少端侧训练时的内存占用。同时在联邦学习MindSpore Federated场景下支持云侧对端侧权重的读写,权重采用差分隐私方式进行端云传输进一步保证了端云训练中的安全性。端云训练一般流程如下:
调试器易用性更上一层楼:图码结合调试和训练回放
作为MindSpore图模式下的调试利器,调试器提供了丰富的检查规则帮助用户快速识别常见精度问题。为了帮助大家更好地在图模式下调试脚本,1.3版本中,我们新增了图码结合调试和训练回放功能。
图码结合调试能帮助您掌握代码和计算图的关系,通过调试器提供的代码信息,您能够更好地理解计算图背后的代码逻辑,提升精度问题分析效率。
训练回放是通过离线调试这一全新的试模式实现的,在训练结束后,您可以通过离线调试模式对训练过程进行分析,还能对并行训练(单机多卡)中的精度问题进行分析和定位。
1.图码结合调试:一眼掌握代码和计算图的关系
MindSpore图模式的调试中,如果能方便地找到某行代码所关联的计算图节点,对调试效率将有很大提升。在调试器的帮助下,您可以方便地查看计算图中算子节点和代码的关联关系,无论是以码搜图,还是以图找码,都能在图形界面下快速完成。
以码搜图时,输入想要查找的代码行(例如alexnet.py:52),即可寻找同此行代码关联的计算图节点。如下图所示:
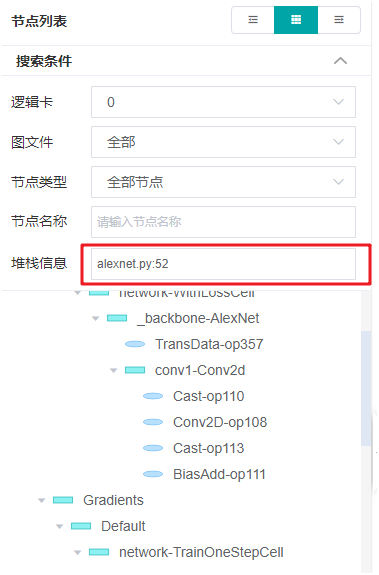
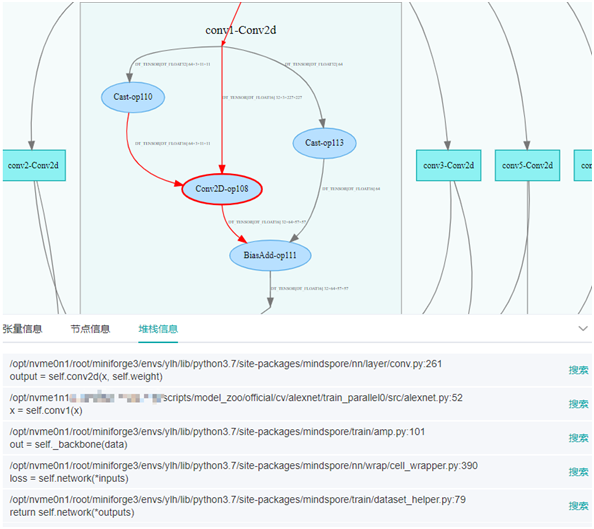
以图找码时,在计算图中选中算子节点(例如Conv2D-op108),即可在堆栈信息中查看该算子对应的代码行。如下图所示:
2.支持离线调试:随时离线回放分析训练过程,节约AI处理器资源
在使用之前的调试器时,要求先启动训练进程,在训练进程运行的过程中对精度问题进行分析。我们提供了离线调试的能力,通过dump功能将调试数据保存到磁盘上,然后就可以在不使用昇腾AI处理器的情况下回看训练过程,分析精度问题。由于数据在磁盘上,离线调试中还可以随意切换正在调试的迭代,回放训练,免去在线调试错过关键迭代后又要从头运行脚本的烦恼
3.支持单机多卡调试:定位并行训练中的精度问题
在离线调试功能的基础上,调试器支持了单机多卡训练的调试。在MindSpore上调试单机多卡的训练时,只需通过dump功能保存数据到磁盘,就可以使用MindInsight可视化地进行分析。调试器中已经提供的监测点,例如检查梯度消失,检查激活值饱和,检查权重不更新等,都可以继续在此场景下使用。图码结合调试同样支持单机多卡。
推理优化——X86_64 CPU PC推理能力
为了更好的支持PC侧推理,x86_64从汇编层面入手,支持针对不同卷积shape的动态block切分,充分利用寄存器等硬件资源,使我们推理性能达到极致,较上个版本推理时延有了10%~75%+的提升。我们在Intel Core i7-8700 CPU上与OpenVINO(2021.3.394)、MNN(1.2.0)、TNN(v0.3)在几个经典CV类网络上进行benchmark测试,从测试结果可以看出MindSpore Lite保持了较高的水平。

更多推理性能优化
随着数据集和网络规模越来越大,网络计算量也越来越大;同时交互式推理任务中的对时延要求更加严格,深度神经网络推理任务逐渐向AI加速硬件(比如GPU)进行迁移。MindSpore 1.3版本提供了更多与此相关的推理性能进行优化,性能相比此前大幅提升。
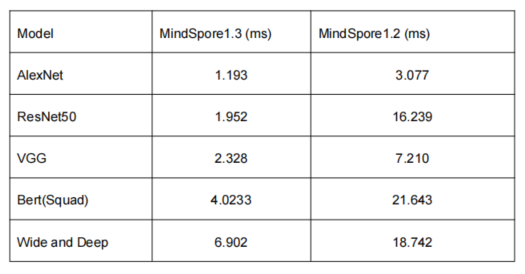
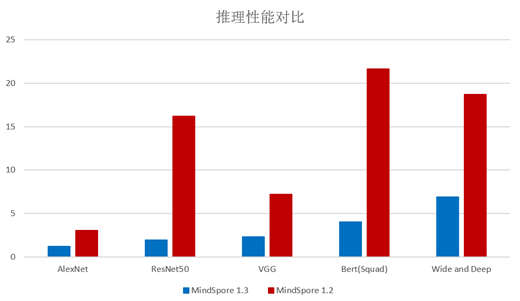
基于Model Zoo中的一些典型的网络,分别使用MindSpore1.2和MindSpore1.3版本对,统计推理请求平均执行时间,推理性能提升3~8倍。
图算融合加速MindSpore网络训练
图算融合是MindSpore的关键技术之一,通过图层融合与算子生成的协同优化来提升网络执行性能。在之前版本,我们使能了NPU(昇腾)和GPU上图算融合的基本能力,并且在标杆网络上取得了不错的成绩。在1.3版本中,我们加强了图算融合在GPU上的泛化能力,通过对Model Zoo 40多张主流网络的验证,平均可获得89%的性能提升。以Transformer为例,使能图算后,从2.5小时/epoch降低到1.75小时/epoch,完整训练时间从5.4天降低到3.8天!
同时,在易用性方面我们新增了环境变量的控制方式,使得用户不需要对网络代码做任何侵入修改,即可享受图算融合带来的性能收益:
export MS_GRAPH_KERNEL_FLAGS=”–opt_level=2”
我们选取了部分主流的网络(NLP、推荐及CV)开展性能对比评测,使用图算融合的有普遍的性能提升,提升详情如下图所示:

(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















