
尊敬的用户:
感谢在过去的一年里对小容的期许,过去的2020年小容先后发布了3个版本的功能迭代升级,在春节来临之际小容迎来了2020年度最后一次产品升级,内容如下:
1、新增系统内置实体
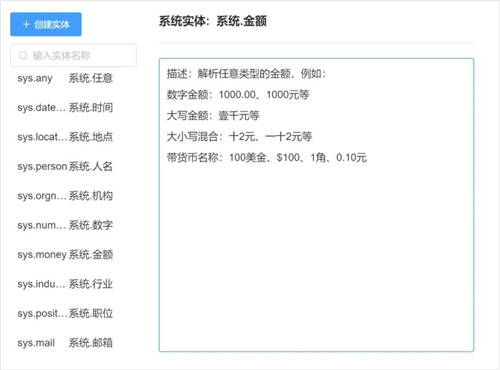
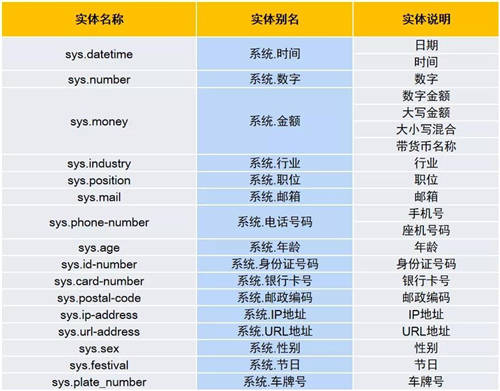
为了满足更多业务场景中对实体信息的识别,本次更新新增了二十余种系统内置常用实体,如,数字、金额、银行卡号、邮编、车牌号等。
2、账号体系升级
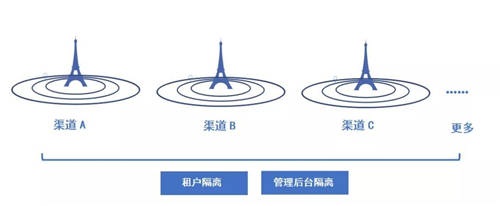
为满足不同客群的需求,本次对系统的账号体系进行了全面升级,在之前的多租户账号体系上,增加了多渠道账号体系,实现渠道间的租户端、管理端数据全隔离。
3、情绪识别结果输出
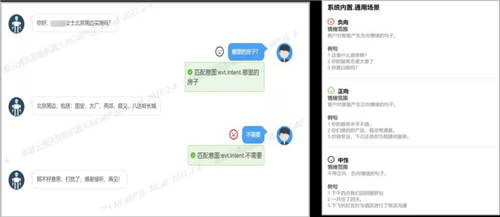
情绪识别结果输出基于情绪引擎分析,自动检测会话内容中文本蕴含的情绪特征,帮助企业更全面的把握产品体验、监控客户服务质量。
4、NLP原子能力不断扩容

本次升级除了对产品体验、数据安全、稳定运行等方面进行了数十项优化处理,我们也在持续不断扩容NLP原子能力。
中文分词
将自然语言文本切分成语义合理、完整的词汇序列,并为每个词汇赋予一个词性,如:动词、名词、介词等。

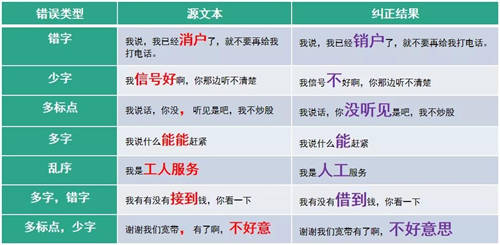
文本纠错
自动更正文本中存在错误的字段,减少由此带来的语义解析不准确或阅读障碍。
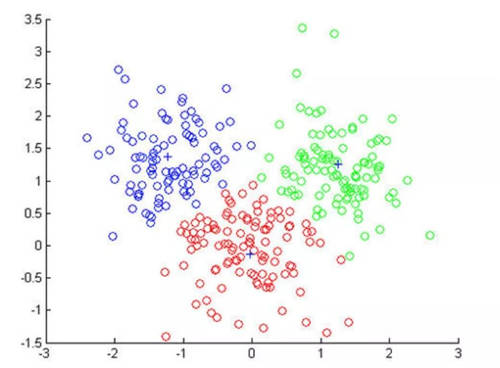
知识聚类
在没有业务场景和标准问的情况下,通过聚类算法对无标签数据集自动构建业务场景和标签。协助运营人员进行数据预处理,提升数据运营效率,减轻运营人员工作量。
中心词提取
基于BERT多任务训练和MMR重排算法,借助积累的通用、专业词库对结果再处理,自动提取体现文本核心主题的关键词语。

文本相似度计算
基于海量数据训练的网络模型,计算两个句子之间的相似度,实现高精度语义相似度比对。文本相似度可以帮助用户快速实现推荐、检索、排序等应用。

句式识别
输入对话中自然语句,返回对应的句式分类结果。支持陈述句、疑问句、感叹句和祈使句识别。

文本摘要
基于深度语义分析模型,自动抽取文本中的关键信息生成简短的文本摘要。

(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















