
大数据时代
大数据又称巨量资料,指的是所涉及的资料量规模巨大到无法透过目前主流软件工具,在合理时间内达到撷取、管理、处理并整理成为帮助企业经营决策更积极目的的资讯。从某种程度上说,大数据是数据分析的前沿技术。简言之,从各种类型的数据中,快速获得有价值信息的能力,就是大数据技术。
IDC报告显示,2025年全球数据存储量将达到163ZB(相当于16万多亿GB),到2030年将达到2500ZB。在过去几年,全球的数据量以每年40%以上的速度增长,在未来这个速度会更快。

浪擎DataOne数据融合系统的机遇
数据融合是解决跨平台应用、协作、共享的有效手段,如果缺少统筹规划,注重单次数据交互的结果,会忽略数据融合平台的兼容性和拓展性,出现以下问题:
急用先行:烟囱式建设思路,互相之间不连通,资源无法根据业务的变化实现动态调整,利用率很低;
无法复制:平台、脚本无法复用,多条数据链路错综复杂;
难以扩展:资源难以整合,不同的项目需要重复建设,实施过程长,难以长期拓展。市面上的传统工具ETL有许多的不足之处,无法支撑大数据时代背景下的数据融合,存在许多问题需要解决:
持续投入高:开发、维护、拓展、升级各个环节均需要人员和资金的持续投入;
经验难以持续:单机架构的开发经验无法延续到分布式架构,缺少对大数据量的支持能力;
开发维护量大:从平台开发到日常的管理运营,依然存在大量的脚本开发工作;
风险因素多:人员变更、数据源变化、数据量增长均会带来一定的风险;
适用性不高:对个人技术能力依赖性强,高可用性不佳,缺少时间和经验的验证;
实时性差:不具备实时性,难以进行相关改造。
这些问题不仅造成了用户在使用方面的困扰,也使得企业无法很好统筹自己的业务数据。在大数据时代下,数据成为了各个企业最为宝贵的财富,如何把数据完整、高效的进行汇聚融合成为了DataOne需要攻克的难题。DataOne采用分布式和并行架构,实现所有数据的融合和共享交换,灵活地连接所有数据源,实现真正的随心所变。
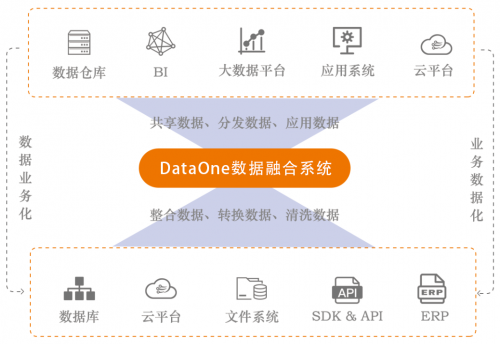
浪擎DataOne数据融合系统三大功能:
数据汇聚:
将不同来源、不同特性的数据在逻辑上和物理上有机地集中,从而为企业应用系统提供全面的数据共享。通过浪擎DataOne数据融合系统解决企业数据一致性和数据可靠传输问题,打破企业信息孤岛,建立企业数据中心,最终实现数据的共享发布应用。
数据迁移:
数据迁移工具主要是为了帮助企业解决在进行数据“搬家”时遇到的问题,浪擎DataOne数据融合系统支持多源异构数据兼容,支持多种数据源,在迁移过程中无需停机。性能方面采用分布式架构,进行多线程处理;并且拥有完善的数据管理、清理、校验功能,全流程可视化管理。
数据脱敏:
数据脱敏主要应用于涉密数据,如党政机关、金融医疗体系等,浪擎DataOne数据融合系统能够对涉密数据进行个性化脱敏脚本编写,对敏感数据进行多维度的脱敏操作,如关键词替代、隐藏敏感词汇、数字置换等。并且对脱敏全流程进行加密处理,确保源数据的安全保密。
浪擎DataOne数据融合系统应用场景:

1、主流数据库同构数据迁移:
DataOne产品支持对Oracle、SQL Server、MySQL等主流数据库的同构数据迁移,可以针对相同数据库进行不同版本以及不同库之间的数据迁移,可以将多个数据源分散的数据库数据进行汇聚整合,进行相关业务汇总以及数据分析。
2、信创环境异构数据迁移:
产品更多的应用场景是针对非国产数据库Oracle、SQL Server、MySQL向国产数据库达梦、人大金仓的数据同步。信创数据部署在不同的信创CPU、不同的信创操作系统中,因此存在环境上的多重异构。针对信创的复杂迁移场景,DataOne产品进行了对应的产品适配工作,能够保障将数据迁移到任何搭配起来的不同信创环境中。针对非国产数据库与国产数据库之间的数据字段的差异,设置了字段的自动匹配规则mapping,能够保障同步到国产数据库中的数据正常可使用。
3、非结构化数据迁移:
DataOne支持针对源业务数据库对应文件系统的迁移,保障数据迁移完成后,整体业务便捷可用,解决了传统只迁移完成数据库数据,对应文件无法及时迁移所面临的业务不可用的情况。支持非结构化文件源的文件迁移任务。

4、数据汇聚入湖
针对大型企业、大数据中心存储各种各样原始数据的大型仓库,其中的数据可供存储、处理、分析及传输。利用DataOne产品统一接入各类数据资源、融合数据孤岛,基于Kafka Connect的技术特点,能够非常便捷的对数据源进行管理,将多源分散的业务数据统一进行汇聚入湖。适配安全网络隔离架构,自动完成跨网的数据采集、中转与处理。将数据汇聚集中管理以及分析采集使用,数据湖结合数据分析和机器学习算法,帮助企业构建优化后的运营模型、预测分析等。

5、数据的清洗与治理
除了满足针对同构、异构场景的数据迁移任务外,DataOne产品能够针对大数据进行清洗治理。根据业务需求,在执行数据任务过程中进行相应数据处理设置,帮助用户零开发完成自定义表名、字段名称,过滤、替换数据等数据清洗功能。同时提供高级清洗选型,提供清洗脚本模板,供用户根据自身需求自定义设置清洗规则,完成对源数据的处理,将数据处理完成后可以进行对应业务的分析处理。

6、数据集成上云:
将不同业务环境上的结构化、非结构化数据汇聚、集成、整理至DataOne数据交换平台。DataOne批量采集数据后实时同步、批量加载数据, 统一存储上云至大数据中心。大数据中心为业务系统提供数据支撑。
浪擎DataOne数据融合系统的价值:
浪擎DataOne数据融合系统是数据迁移、集成、融合与共享管理平台。在信息化建设过程中,由于业务系统逐年分批建设,致使存在诸多烟囱形态与数据孤岛,不同业务之间不连通,数据无法整合利用。同时在数据时代,经营或决策都要求数据能被快速共享与整合,从而为决策提供数据支撑。DataOne为解决数据孤岛问题,构建数据中台与共享发布服务,提供多源异构数据的迁移、汇聚与融合技术实现方案,从而实现数据的流动,释放数据的价值。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















