
近日,华为云AI团队获得第9届国际自然语言处理与中文计算会议NLPCC 2020 轻量级预训练中文语言模型测评第一名。

NLPCC 由中国计算机学会主办,是自然语言处理(NLP)和中文计算(CC)领域的顶级国际前沿会议,每年会议都秉承国际化和一流化的严格标准来进行自然语言处理任务的开放评测,推动相关任务的研究和发展。NLPCC 2020吸引了康奈尔大学、伦敦大学、普林斯顿大学等海内外近600位自然语言处理领域的专家及学者参加大会,其中400余位专家学者在现场共同见证开放评测任务第一名的诞生。
当下,预训练语言模型已经成为NLP的主流方法,在多项NLP任务上都取得了明显的效果提升。但是预训练语言模型往往比较大,限制了预训练语言模型的应用场景。因此,如何构建轻量级的预训练语言模型就成了一个关键问题。
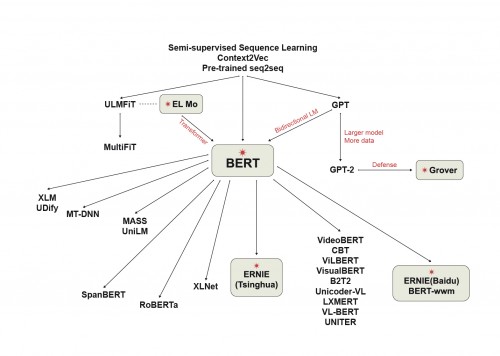
预训练语言模型出现以来发展得非常迅速,目前已经演化形成了一个家族
中文轻量级预训练语言模型能力评测任务的目的在于让参赛团队减少语言模型大小的同时尽可能保证模型效果。本次比赛包含四个任务,分别是指代消解,关键词识别两个句子级别分类任务,实体识别序列标注任务,MRC阅读理解任务,从不同角度评测模型的语义表达能力。同时,比赛要求模型的参数量低于bert-base模型的1/9,模型推理速度达到bert-base模型的8倍,这就要求模型运行快,体积小,效果好。
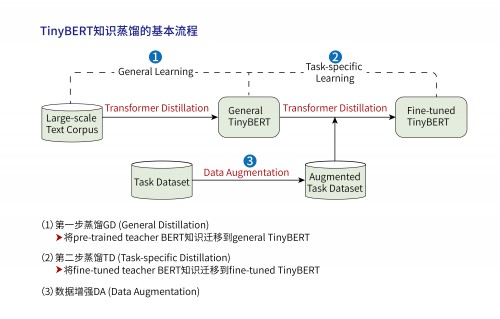
一般来说,可以通过量化、剪枝、蒸馏等方法来压缩大预训练语言模型来获得轻量级模型。华为云与诺亚方舟实验室联合团队基于自研的NEZHA中文预训练模型通过知识蒸馏得到tiny-NEZHA轻量级模型摘得桂冠。
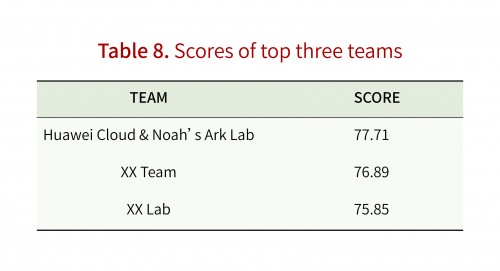
相比其他模型,华为的模型在结构上找到了一个较好的平衡点,采用TinyBERT两步蒸馏的方式让模型更好地学到任务相关的知识,蒸馏过程中用语言模型预测并替换部分token的方式进行数据增强可以使小模型拥有更强泛化性。
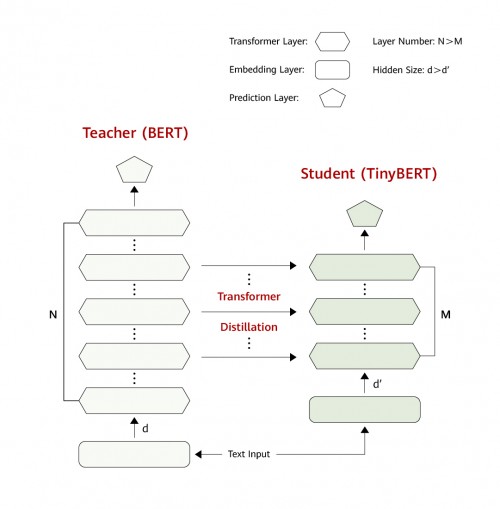
TinyBERT知识蒸馏的损失函数中一个重要环节是让中间层去学习隐藏状态和attention向量
同时,华为自研的NEZHA预训练语言模型采用相对位置编码替换BERT的参数化绝对位置编码,能更直接地建模token间的相对位置关系,从而提升语言模型的表达能力。
在即将过去的2020年里,华为云AI在人工智能领域的研发成绩斐然,斩获十二项包含WSDM、WebVision、CCKS篇章级事件抽取技术评测冠军、人工智能金炼奖、德国红点在内的国际国内榜单冠军和奖项。华为云AI将继续夯实技术优势,做智能世界的“黑土地”,持续践行普惠AI,将AI服务触及每一位开发者、每一个企业,助力各行各业进入人工智能新时代
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















