
数字化时代,机器数据无处不在。
在今天的在线研讨会上,爱数AnyRobot推出创新开放的Hub架构,统一纳管多源机器数据,助力IT运营化解机器数据管理难题,赋能数据驱动型组织业务创新发展。

爱数总裁贺鸿富直播演讲
机器数据管理的挑战
随着企业数字化转型的深入,IT建设、业务应用投入不断增加,服务器、存储、各类系统的设备或系统的运转产生了海量机器数据。机器数据来源复杂,种类、格式多样,实时产生增长速度快,数据量大,并且现有技术难以从中挖掘出数据价值。
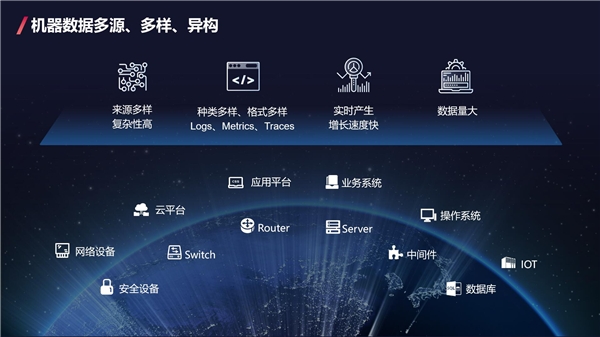
IT运营的机器数据分析场景需求也更为多样。合规留存、安全审计、智能运维、业务运营、安全态势感知等都需要对海量机器数据进行深度的挖掘和分析,从而驱动企业IT运营转型变革。
目前,很多企业客户,特别是金融企业,已经选择开源或商业机器数据平台。但,受限于产品本身的能力和安全合规的审计需求,无法全面满足IT运营的多样化需求。
以开放思维走进机器数据世界
AnyRobot Family 3,开放、高效、经济的机器数据分析平台,秉承爱数“平台+商业”的战略模式,创新推出开放的Hub架构,实现多源异构数据、多机器数据平台的统一纳管,释放海量机器数据的价值。
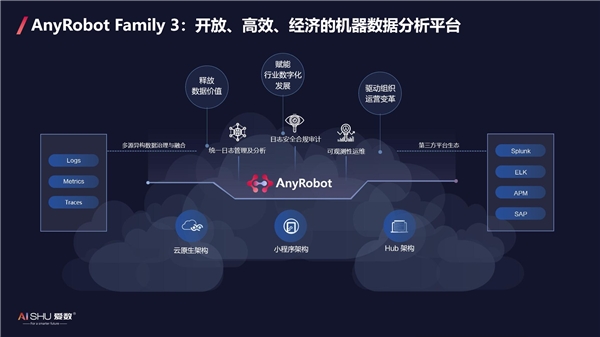
而,Splunk平台作为机器数据分析平台的领导者,采用大数据分布式存储和计算架构,通过采集企业内部日志数据(含核心应用),利用数据建模、行为识别、关联分析、机器学习等技术,对日志数据进行集中管控,提供全量日志极速检索和大数据日志分析功能。目前,超过300家中国知名企业在使用Splunk,但却面临Splunk缺乏本地化的服务支持,无法满足国产化合规建设,项目交付周期长,用户难以独立使用等问题。
在本次研讨会中,以AnyRobot Hub架构在某银行处实践为例,深度解读AnyRobot Hub架构的优势,以及如何实现纳管Splunk平台,并在后期平滑切换至AnyRobot平台,保障原有数据分析和查询服务的持续稳定进行。这其中AnyRobot的Hub架构是实现平台替换Splunk的不可替代的核心因素。
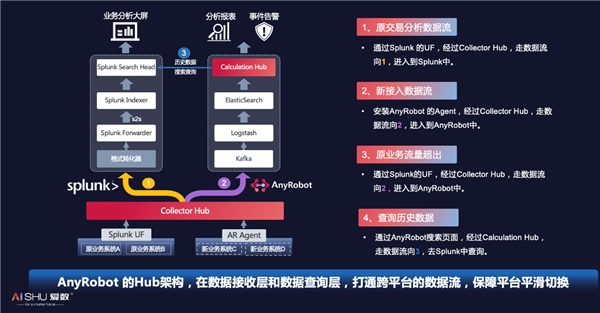
Splunk原有数据采集场景:
在现有Splunk平台可继续使用的情况下,保持Splunk UF采集数据,然后将数据接入到AnyRobot的Collector Hub上,再令数据转发到Splunk上,在数据流上增加一个格式处理器,以确保Splunk能识别到来自Hub的数据格式,同时引入Splunk的S2S协议,保障接入的数据host字段不变。其他数据的处理方式保持不变。
新增加数据管理场景:
部署AnyRobot Agent ,将Agent的数据流推送给Collector Hub,再传输到AnyRobot的Kafka,通过AnyRobot进行数据清洗、存储和分析处理。
Splunk原数据流量超出场景:
为避免数据流量超出导致Splunk的搜索功能无法使用,在Collector Hub上切换部分Splunk 的UF数据流到AnyRobot上,既保障原分析和查询服务不中断,又避免数据流量超出。
历史数据查询场景:
当新的数据接入到AnyRobot后,完整的查询中历史数据的部分在Splunk上。使用Calculation Hub,将请求调度给Splunk,并把接收到的数据返回给AnyRobot做统一计算。这个过程就像Hadoop的MapReduce一样,分布式请求,然后把结果再汇聚计算。
在本次研讨会上,AnyRobot Family 3 ,展示了其对多源异构数据的管理分析能力,赋能全行业客户数字化转型,深化数据驱动型组织的运营变革。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















