
近日,国际人工智能顶级会议AAAI 2021公布论文录取结果。网易伏羲实验室再创佳绩,共有9篇论文入选,研究方向涉及强化学习、虚拟人、自然语言处理(NLP)、图像动画、用户画像等领域。科研成果的集中爆发,充分显示网易伏羲在人工智能的多个领域已经具备国际顶尖的技术创新能力。

AAAI(Association for the Advance of Artificial Intelligence)是美国人工智能协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的的国际顶级学术会议之一。在中国计算机学会的国际学术会议排名中,AAAI被列为人工智能领域的A类顶级会议。
作为人工智能领域的风向标,每年的AAAI都会吸引大量来自学术界、产业界的研究员、开发者投稿和参会,论文竞争更是异常激烈。AAAI 2021联合主席Kevin Leyton-Brown在Twitter上表示,今年接受的投稿论文总数达到“惊人的高技术水平”。9034篇投稿论文中,7911篇接受评审,最终仅有1692篇论文被录取,录取率为21%。
网易伏羲成立于2017年,是国内专业从事游戏与文创AI研究和应用的顶尖机构。此次AAAI中稿论文中展示的部分技术成果,如:智能捏脸、表情迁移等技术,已在网易多个产品中应用落地,成为吸引行业关注的亮点。
以下是网易伏羲入选9篇论文:
MeInGame:从单个肖像中创建一个游戏角色
(MeInGame: Create a Game Character Face from a Single Portrait)
关键词:角色创建、智能捏脸
受到参数范围的限制,现有的游戏角色人脸自动创建算法无法很好地还原参数范围之外的人脸,且大部分方法都没有考虑贴图。少部分能够生成贴图的方法,也没有考虑光照和遮挡物的影响,导致创建的三维人脸无法很好地应用在游戏中。
为了提高创建的游戏人脸的形状相似度,本文提出先使用业内成熟的基于3DMM和CNN的方法重建三维人脸,然后基于径向基函数插值的方法,将三维人脸的形状迁移到游戏三维人脸模板上。

(网络结构图示)

(智能捏脸效果图示)
主观实验表明,本文提出的方法在约98%的测试用例上都优于其它现有方法。
2、基于标准化外观自适应的人脸重演方法
(One-shot Face Reenactment Using Appearance Adaptive Normalization)
关键词:表情迁移
人脸重演的目的是将一张人脸的表情和姿态迁移到另外一张人脸上去,该任务可以用于说话头生成、虚拟形象驱动等目的。
之前的部分模型需要多张源图片来训练一个单独的网络。一些one-shot模型往往无法较好地保存原始人脸的身份信息,且生成质量较低。通过对adptive normalization的分析,我们指出先前的模型不适用于人脸重演这一任务。
本文通过一个网络来预测所有层的adaptive 参数,这种设计能够对adaptive 参数进行全局的规划。此外,本文引入local-global机制,通过先将局部的五官迁移,然后用五官来指导生成整张脸简化了任务。
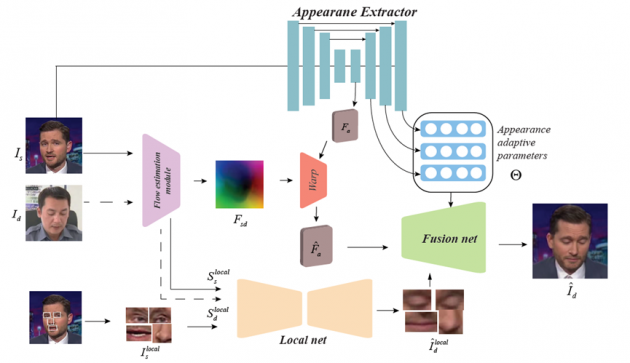
(网络结构图示)
实验表明,本文提出的方法能更好地保存原始人脸信息,生成更真实的图像。
3、结构感知下基于姿态分解和语义相关性的人体图像生成
(Structure-aware Person Image Generation with Pose Decomposition and Semantic Correlation)
关键词:动作迁移、图片生成
基于姿态引导的人体图片生成是一种将源输入图片中的人体图像变换为目标动作姿态的技术。目前,该技术已经被广泛地应用于影视制作、动画生成、虚拟试穿等诸多领域,具有广泛的应用前景和巨大的市场价值。
鉴于标准CNN无法高效地处理大的空间形变,本文提出了一种基于外观流的方法来建模源特征与目标特征之间的密集对应关系。在此框架下,我们结合人体的先验结构信息来指导网络学习,从而有效地改善效果。同时,我们进一步设计了一个轻量且有效的基于金字塔池化的非局部(non-local)模块以捕获不同尺度下不同人体部分的全局语义相关性。

(网络结构图示)
实验结果表明,本文提出的方法可以在较大的姿态差异下生成高质量的结果。

(实验结果图示)
4、基于视觉感知下全局关系学习的游戏住宅规划
(In-game Residential Home Planning via Visual Context-aware Global Relation Learning)
关键词:游戏庄园合成,全局关系图生成,视觉感知
在场景合成领域,基于组件的三维场景合成一直是一个相对空缺的研究方向。现有方案倾向于依赖组件之间的功能性约束,例如,电视机一定会放置在电视柜上等等。另外,室内场景组织的时候单一场景的组件比较少,大约在10个左右。
这类场景下的研究工作与实际的庄园合成场景差异很大。例如,在庄园中,组件之间没有很强的功能性约束;另外,在庄园中通常会有几百个组件,这也是之前的工作不能解决的。
本文提出了一种基于全局关系约束的思路。我们将当前场景转化为一个带有丰富空间信息的有向图。通过学习数据集中边的分布情况,我们可以采样出当前场景中所有节点到新节点的边的分布,进而通过边的分布来推断出新节点的位置。如此便可以辅助整个场景中组件的逐一摆放。
为了实现这个目的,我们基于图注意力机制下的循环网络来模拟当前子图到目标节点的边的分布情况,为了在模型中加入对2D空间的理解,我们将3D场景渲染为2D,提取对应节点视觉特征,融合到循环网络中。由于图节点信息和2D场景信息来自不同的域,我们还加入一个全局的视觉内容-图节点匹配损失。
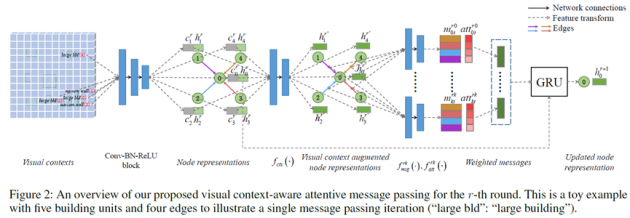
(网络结构图示)
实验结果表明,我们的方案能解决之前的工作在我们的场景下不适用的问题,并且能给出理想的位置推荐结果。
5、HR-Depth:高分辨率自监督单目深度估计
(HR-Depth : High Resolution Self-Supervised Monocular Depth Estimation)
关键词:自监督,深度估计
通过以图像序列作为唯一的监督来源,自我监督学习在单眼深度估计中显示出巨大潜力。尽管人们尝试将高分辨率图像用于深度估计,但是预测的准确性并未得到明显提高。
在这项工作中,我们发现主要原因来自于对大梯度区域的不正确的深度估计,从而使双线性插值误差随着分辨率的提高而逐渐消失。为了在大的梯度区域中获得更准确的深度估计,必须获得具有空间和语义信息的高分辨率特征。
因此,我们提出了一种改进的DepthNet HR-Depth,它具有两种有效的策略:(1)重新设计DepthNet中的跳跃连接以减少编码器和解码器之间的语义鸿沟;(2)提出特征融合Squeeze-and-Excitation(fSE)模块以更有效地融合特征。使用Resnet-18作为编码器,HR-Depth在高分辨率和低分辨率场景中都超越了所有现有技术,同时具有更少的参数。此外,以前的最新方法是基于相当复杂的深度网络,具有大量参数从而限制了它们的实际应用。因此,我们还构建了一个使用MobileNetV3作为编码器的轻量级网络。
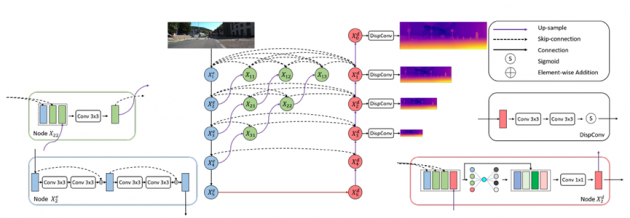
(网络结构图示)

(估计结果图示)
实验表明,轻量级网络可以以仅20%的参数与许多大型模型(如Monodepth2)以高分辨率相媲美。
6、结合解耦通用值函数的强化学习商品推荐
(Reinforcement Learning with a Disentangled Universal Value Function for Item Recommendation)
关键词:强化学习、商品推荐
近年来,将强化学习结合到推荐系统中,引起了人们极大的兴趣,也带来了新的挑战。本文总结了基于强化学习的大规模推荐系统在实际应用中面临的三大挑战,并研发了一种基于 goal-based 的强化学习框架 GoalRec。

(解耦值函数的强化学习推荐框架)
本文结合world model和值函数的思想,提出了一种基于模型的值函数形式化方式,能够将环境演变和奖励分离开来。通过使用稠密的推荐环境数据而非奖励信号,我们有效地学习了一个与奖励无关的、高模型容量的world model。
不同于只预测下一步状态的传统world model,我们通过引入goal-based 强化学习框架,通过对强化学习策略的参数化序列建模,将world model扩展到了用户轨迹维度。因为传统的基于模型的规划方法效率较低,我们进一步将world model融入到值函数中,且一定程度上帮助值函数规避了高方差环境与稀疏奖励信号带来的学习问题。
在网易热门游戏《遇见逆水寒》神秘商店场景中,我们部署了这一算法,验证了该算法相比之前的监督学习与普通强化学习算法能带来较大的业务收益。
7、NeuralAC:用于比赛结果预测的学习合作与竞争效应
(NeuralAC: Learning Cooperation and Competition Effects for Match Outcome Prediction)
关键词:神经网络,比赛预测、合作竞争
预测团体比赛的胜负是一项重要且有挑战的任务。由于人具有社会属性,比赛中的成员不可避免地会与其他成员产生交互,影响比赛结局。现有的工作主要关注于学习团队成员的个体能力,或者建模团队内部的交互。然而,群体比赛中存在多种复杂的交互,包括团队内部交互(即合作效应)和团队间交互(即竞争效应)。同时,不同重要性的成员还会在群体比赛中受到不同程度的关注,影响比赛结果。
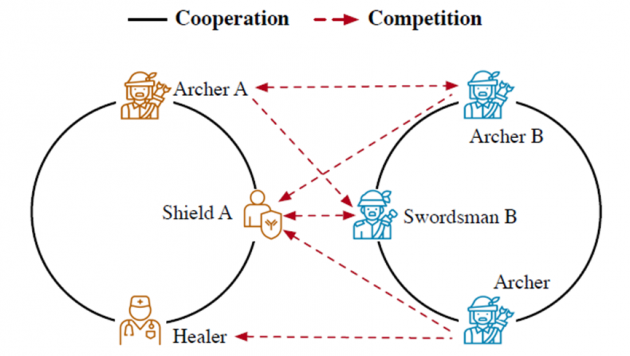
(游戏对战中的合作与竞争关系)
为此,本文提出了 NeuralAC,它能学习带权重的竞争合作效应,用于比赛结果的预测。具体来说,NeuralAC首先将个体成员投影到多个隐空间,使用神经网络作为交互函数来建模对友间的合作和对手间的竞争效应。随后,我们使用两种注意力机制来捕捉团队内部以及团队间的注意力分布,这同时提高了比赛预测的准确性和可解释性。

(NeuralAC模型框架)
在多个电子团体竞技的数据集上的实验结果都表明NeuralAC优于其它方法。该方法还可以很容易地推广到其他任务中,如团队组建、MOBA游戏平衡性检测等。
8、基于风格化的非平行语料的风格化对话回复生成
(Stylized Dialogue Response Generation Using Stylized Unpaired Texts)
关键词:自然语言处理、对话生成、自然语言生成、预训练语言模型、数据增强
生成风格化的回应是构建智能且吸引人的对话系统的关键。然而,这一任务远未得到很好的探索。这是因为让神经网络在生成连贯的响应的同时呈现特定风格非常困难,特别是当目标风格只嵌入在无法直接用于训练对话模型的未配对文本中时。
本文提出了一种风格化的对话生成方法,可以捕捉嵌入在未配对文本中的风格特征。具体来说,我们的方法可以生成既符合上下文,又符合目标风格的对话回复。在本文中,我们首先引入了一个逆向对话模型来预测一条回复内容对应的输入。然后,我们用这个逆向模型来根据这些风格化的非配对文本生成风格化的伪对话对。我们使用这些伪对话对来联合训练风格化对话模型。为了增强decoder中的风格特征,我们提出了style routing方法。

在两个数据集上的自动和人工评估表明,我们的方法在产生连贯和风格密集的对话回复方面优于竞争基线。
9、生成一个演讲者:基于文字生成的、具有表情和韵律的的说话人脸视频算法框架
(Write-a-speaker: Text-based Emotional and Rhythmic Talking-head Generation)
关键词:虚拟人、图像生成、数字人、音视频同步、说话人脸、视频合成
本文首次提出了从文字生成说话人脸视频的算法框架,除了音视频同步的口型,还同时生成了与说话内容匹配的面部表情和与说话节奏匹配度韵律头动。
本文的算法由两个阶段组成:第一阶段与特定说话人无关,包括三个并行网络,分别用于生成口型、眉眼表情和头部运动三组动作参数; 第二阶段合成特定说话人视频,基于三维人脸信息监督的自适应注意力网络来生成不同特定人的说话视频, 此阶段以动作参数作为输入,生成注意力掩码来修改不同说话人的面部表情变化。为了更好的采集面部动作和说话内容的关系,本文借助动作捕捉设备建立了一个音视频同步数据集。基于这个动捕数据集,本文的算法可以实现高效的端到端训练。


(由算法合成的说话人脸视频)
定性和定量的实验结果表明,基于任意特定人物的少量视频数据(5分钟),本文的算法能够从文字生成有情绪和韵律节奏的该特定人物的像素级说话人脸视频,其中视觉质量超过已有方法。
(免责声明:本网站内容主要来自原创、合作伙伴供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。
任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。 )




















